ubunutu11.10下hadoop1.1.1单机版环境搭建步骤详解(二)--单机版配置
ubunutu11.10下hadoop1.1.1单机版环境搭建步骤详解(二)--单机版配置
Hadoop是一由Apache基金会开发的一个分布式系统构架。Hadoop通过分布式集群技术,将多个物理机或虚拟机当作一台机器运行,充分利用集群的威力高速运算和存储。hadoop包括了HDFS(Hadoop Distributed File System)分布式文件系统以及mapreduce并行计算框架和hbase等组成部分。Hadoop的推荐部署环境是Linux,我的电脑安装的是Win7系统,由于对Linux系统的操作一无所知,为了给自己留一条后路,我在这里使用双系统,实现hadoop的搭建。具体的搭建步骤为:
一、安装虚拟光驱
二、在虚拟光驱上安装ubuntu
三、在ubuntu中创建hadoop用户和用户组
四、在ubuntu下安装JDK,配置JDK环境
五、安装SSH,设置SSH无密码登录本机
六、安装hadoop
七、在单机上运行hadoop
一、安装虚拟光驱
我的电脑是Win7系统,在这里我选择使用虚拟光驱安装ubuntu,当然大家也可以用硬盘光驱安装,差别在于前者安装系统的速度相对来说会快一点,但如果选择硬盘安装的话,这一步就可以省了。我下载的虚拟光驱是Deamon Tools Lite。
二、在虚拟光驱中安装ubuntu
将ubuntu-11.10-desktop-i386.iso这个镜像文件添加到虚拟光驱中,在虚拟光驱中,双击wubi.exe文件,弹出的窗体中,选择第二个:“在windows中安装”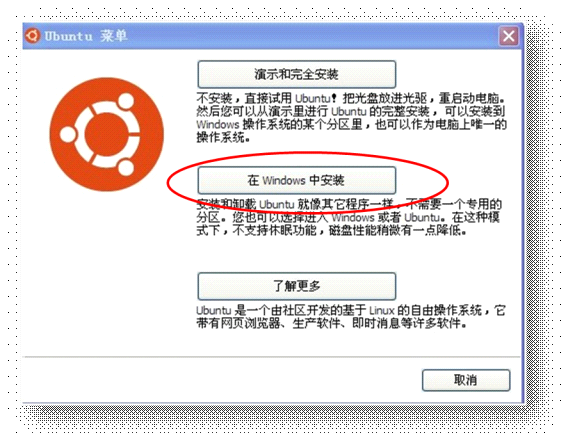
在弹出的界面中,选择ubuntu安装的系统盘,以及ubuntu的登录名和登录密码,因为,在切换用户时,会经常用到这个密码,方便起见,建议密码设置简单一点。设置完成后,点击“安装”,可能需要3--10分钟,安装完成后,系统会提示让你重启系统,当你重启后,选择进入ubuntu系统,进入ubuntu的图形化界面后,系统需要15-20分钟的时间配置文件,就安心等待吧。
三、在ubuntu中创建hadoop用户组和hadoop_chp用户
用快捷键Ctrl+Alt+T打开终端,在终端输入以下命令:
1、创建hadoop用户组:sudo addgroup hadoop
会提示让你输入用户组密码。Hadoop用户组主要用于以后集群版,在单击版时还体现不出其作用。
sudo:super user do,超级用户操作
addgroup:添加用户组命令
2、创建hadoop_chp用户 :sudo adduser -ingroup hadoop hadoop_chp
当提示输入用户密码时,建议密码设置的简单一点,因为这个密码会经常用到,对于用户名,如果是一个团队,也建议统一一下命名规则,这里用户名为hadoop_chp.
addusr:添加用户命令
-ingroup:把用户添加到用户组的命令
3、给用户添加权限
输入:sudo gedit /etc/sudoers
gedit:打开文件命令
在文件中 root ALL=(ALL:ALL) ALL语句的下一行添加下面的命令:hadoop_chp ALL=(ALL:ALL) ALL,然后保存,退出。
四、在unbutu下安装jdk
(假设jdk的安装文件jdk-7u11-linux-i586.tar.gz在桌面上)
1、在local目录下创建一个java文件夹
进入文件夹的目录:cd /usr/local
创建java文件: sudo mkdir java
mkdir:创建文件夹的命令
(在/usr/local下面就创建了一个java 文件夹,可以去看看哦)
2、复制jdk到安装目录:
(1)进入到桌面目录(JDK压缩包所在的目录)下:cd /home/administrator/桌面
(2)复制:sudo cp jdk-7u11-linux-i586.tar.gz /usr/local/java
(/usr/local/java为目标目录)
3、安装jdk
(1) 先进入到JDK的压缩包所在的目录下:cd /usr/local/java
(2)解压:sudo tar -xzvf jdk-7u10-linux-i586.tar.gz
tar:解压命令
tar -xzvf:解压.tar.gz的压缩文件命令
(在这里jdk1.7.0的安装只需解压就可以了,不同于jdk1.6.0,注意哦)
4、配置jdk环境变量
(1)、打开配置文件:sudo gedit /etc/profile
在文件的最后面添加如下代码
export JAVA_HOME=/usr/local/java/jdk1.7.0_10 export JRE_HOME=${JAVA_HOME}/jre export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib:$CLASSPATH export PATH=${JAVA_HOME}/bin:$PATHhadoop_chp@ubuntu:~$ ssh-keygen -t rsa -P ""Generating public/private rsa key pair.Enter file in which to save the key (/home/hadoop_chp/.ssh/id_rsa): /home/hadoop_chp/.ssh/id_rsaCreated directory '/home/hadoop_chp/.ssh'.Your identification has been saved in /home/hadoop_chp/.ssh/id_rsa.Your public key has been saved in /home/hadoop_chp/.ssh/id_rsa.pub.The key fingerprint is:e2:bb:35:cf:97:80:d0:52:e1:ea:fa:9a:bf:cb:fb:88 hadoop_chp@ubuntu:The key's randomart image is:+--[ RSA 2048]----+| .. || .. || o. || o.. || ooS. || o .. . || o o . . || = + + o || E+@*. o. |+-----------------+hadoop_chp@ubuntu:~$
<configuration><property> <name>fs.default.name</name> <value>hdfs://localhost:9000</value></property></configuration>
<configuration> <property> <name>mapred.job.tracker</name> <value>localhost:9001</value> </property></configuration>
<configuration> <property> <name>dfs.name.dir</name> <value>/usr/local/hadoop/datalog1,/usr/local/hadoop/datalog2</value> </property> <property> <name>dfs.data.dir</name> <value>/usr/local/hadoop/data1,/usr/local/hadoop/data2</value> </property> <property> <name>dfs.replication</name> <value>2</value> </property></configuration>
hadoop_chp@ubuntuCHP:/usr/local/hadoop$ bin/start-all.shstarting namenode, logging to /usr/local/hadoop/libexec/../logs/hadoop-hadoop_chp-namenode-ubuntuCHP.outlocalhost: starting datanode, logging to /usr/local/hadoop/libexec/../logs/hadoop-hadoop_chp-datanode-ubuntuCHP.outlocalhost: starting secondarynamenode, logging to /usr/local/hadoop/libexec/../logs/hadoop-hadoop_chp-secondarynamenode-ubuntuCHP.outstarting jobtracker, logging to /usr/local/hadoop/libexec/../logs/hadoop-hadoop_chp-jobtracker-ubuntuCHP.outlocalhost: starting tasktracker, logging to /usr/local/hadoop/libexec/../logs/hadoop-hadoop_chp-tasktracker-ubuntuCHP.out
hadoop_chp@ubuntuCHP:/usr/local/hadoop$ jps9878 SecondaryNameNode9428 NameNode9654 DataNode10248 Jps10188 TaskTracker9967 JobTracker
hadoop_chp@ubuntuCHP:/usr/local/hadoop$ bin/stop-all.shstopping jobtrackerlocalhost: stopping tasktrackerstopping namenodelocalhost: stopping datanodelocalhost: stopping secondarynamenode