JSOUP µœ÷ºÚµ•≈¿≥Ê
package com.cc.crawler.infrastructure;import java.io.File;import java.io.FileNotFoundException;import java.io.FileOutputStream;import java.io.IOException;import java.util.ArrayList;import java.util.Collections;import java.util.List;import java.util.Random;import java.util.concurrent.BlockingQueue;import java.util.concurrent.ExecutorService;import java.util.concurrent.Executors;import java.util.concurrent.LinkedBlockingQueue;import java.util.concurrent.RejectedExecutionException;import org.jsoup.Jsoup;import org.jsoup.nodes.Document;import org.jsoup.nodes.Element;import org.jsoup.select.Elements;public class Worker {//±£¥Êµÿ÷∑ ’‚¿Ô±£¥Ê‘⁄G≈õƒhtmlŒƒº˛º–ƒ⁄public static final String SAVED_FOLDER = "G:\\html\";private BlockingQueue<String> taskQueue = new LinkedBlockingQueue<String>(10000); // »ŒŒÒ∂”¡– ◊Ó¥Û100000private List<String> finished = Collections.synchronizedList(new ArrayList<String>()); // ¥Ê∑≈“—æ≠ÕÍ≥…¥¶¿Ìµƒµÿ÷∑µƒ¡–±Ìprivate List<String> processing = Collections.synchronizedList(new ArrayList<String>()); // ¥Ê∑≈’˝‘⁄¥¶¿Ì÷–µƒµÿ÷∑µƒ¡–±Ìprivate ExecutorService savedExector = Executors.newFixedThreadPool(100); // 100∏ˆŒƒº˛±£¥Ê∂”¡–private ExecutorService parserExector = Executors.newFixedThreadPool(100); // ◊Ó¥Û100µƒœþ≥Ã≥ÿ// ”√¿¥◊ˆΩ‚Œˆπ§◊˜private volatile boolean stop = false;public Worker() {}public void addStartAddress(String address) {try {taskQueue.put(address); // π”√◊Ë»˚µƒput∑Ω Ω} catch (InterruptedException e) {e.printStackTrace();}}/** * ∆Ù∂Ø ’‚±þ «“ª∏ˆµ•œþ≥õƒ≈…∑¢»ŒŒÒ ƒ⁄»ð∫кڵ• ≤ª∂œµÿ¥”»ŒŒÒ∂”¡–¿Ô»°÷µ ≈–∂œ «∑Ò¥¶¿Ìπ˝ √ª”–µƒª∞æÕ¥¶¿Ì */public void start() {while (!stop) {String task;try {task = taskQueue.take();if (filter(task)) { // ’‚±þ «π˝¬∑»ŒŒÒµƒ π˝¬ÀÃıº˛◊‘º∫–¥continue;}// System.out.println("start():"+task);processing.add(task); // ’˝‘⁄¥¶¿Ìµƒ»ŒŒÒparserExector.execute(new Parser(task));} catch (InterruptedException e) {e.printStackTrace();}}// ¡¢º¥πÿ±’–¥∫Õ∂¡µƒ»ŒŒÒparserExector.shutdownNow();savedExector.shutdownNow();}public void stop() {stop = true;}/** * * @param task «∑Òπ˝¬ÀµƒÕ¯÷∑ * @return true ±Ì æπ˝¬À false ±Ì æ≤ªπ˝¬À */public boolean filter(String task) {if (finished.contains(task) || processing.contains(task)) {return true;}if (finished.contains(task + "/") || processing.contains(task + "/")) {return true;}if(task.contains("#")){String uri=task.substring(0,task.indexOf("#"));if (finished.contains(uri) || processing.contains(uri)) {return true;}}return false;// else {// int in = task.indexOf("?");// if (in > 0)// contains = finished.contains(task.substring(0, in));// }}/** * Ω¯––Ω‚Œˆµƒπ§æþ * * @author cc fair-jm * */class Parser implements Runnable {private final String url;public Parser(String url) {if (!url.toLowerCase().startsWith("http")) {url = "http://" + url;}this.url = url;}@Overridepublic void run() {try {Document doc = Jsoup.connect(url).get();String uri = doc.baseUri();try {savedExector.execute(new Saver(doc.html(), uri)); // œ»Ω¯––¥Ê¥¢} catch (RejectedExecutionException ex) { // ≤˙…˙¡À’‚∏ˆ“Ï≥£Àµ√˜±£¥Êœþ≥Ã≥ÿ“—æ≠πÿµÙ¡À// ƒ«√¥∫Û–¯µƒπ§◊˜æÕ≤ª“™◊ˆ¡À// ’‚±þø…“‘‘Ÿ±£¥Ê“ªœ¬◊¥Ã¨return;}Elements es = doc.select("a[href]");for (Element e : es) {String href = e.attr("href");// System.out.println("worker run():"+href);if (href.length() > 1) {if (href.startsWith("/")) {href = doc + href;if(href.endsWith("/")){href=href.substring(0,href.length()-1);}}if (href.startsWith("http") && !filter(href)) {try {taskQueue.put(href); // ∂¬»˚µƒ∑≈»Î} catch (java.lang.InterruptedException ex) {System.out.println(href + ":»ŒŒÒ÷–÷π");return; // ∫Û–¯µƒhref“≤≤ª‘ŸΩ¯––}}}}// System.out.println("parser:"+url+" ÕÍ≥…");finished.add(url); // ‘⁄’‚±þÀµ√˜’‚∏ˆurl“—æ≠ÕÍ≥…¡À} catch (Exception e) {e.printStackTrace();} finally {processing.remove(url); // ∞—’˝‘⁄¥¶¿Ìµƒ»ŒŒÒ“∆≥˝µÙ(≤ªπÐ «∑Ò≥…π¶ÕÍ≥…)}}}/** * ”√”⁄Œƒº˛±£¥Êµƒœþ≥à * * @author cc fair-jm * */class Saver implements Runnable {private final String content;private final String uri;private Random random = new Random(System.currentTimeMillis());public Saver(String content, String uri) {this.content = content;this.uri = uri;}@Overridepublic void run() {String[] sps = uri.split("/");String host = sps.length > 2 ? sps[2].replaceAll("\\.", "_") : "";String fileName = new StringBuffer(SAVED_FOLDER).append(host).append("_").append(TimeStamp.getTimeStamp()).append("_").append(random.nextInt(1000)).append(".html").toString();FileOutputStream fos = null;try {fos = new FileOutputStream(new File(fileName), true);fos.write(content.getBytes());fos.flush();System.out.println("saver:" + uri + "–¥»ÎÕÍ≥…");} catch (FileNotFoundException e) {e.printStackTrace();} catch (IOException e) {e.printStackTrace();} finally {if (fos != null) {try {fos.close();} catch (IOException e) {e.printStackTrace();}}}}}}
? π”√»Áœ¬:
package com.cc.crawler.main;import java.util.concurrent.TimeUnit;import com.cc.crawer.infrastructure.Worker;public class Main { public static void main(String[] args) throws InterruptedException { final Worker worker=new Worker(); worker.addStartAddress("www.baidu.com"); System.out.println("»ŒŒÒø™ º"); new Thread(new Runnable() {@Overridepublic void run() {worker.start();}}).start(); TimeUnit.SECONDS.sleep(10); worker.stop();}}?
√ª◊ˆ ≤√¥”≈ªØ(“≤≤ªÃ´«Â≥˛∏√‘ı√¥”≈ªØ)
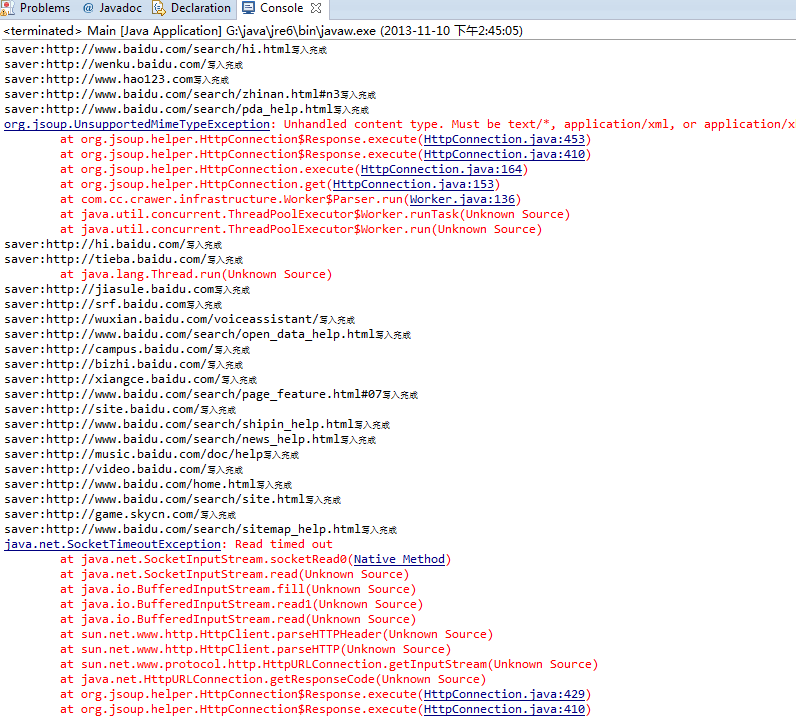
‘À––10s ”√º“÷–µƒÃ® Ωª˙÷ªƒÐ≤˙…˙200∏ˆ◊Û”“µƒÕ¯“≥
‘À––»Áœ¬:
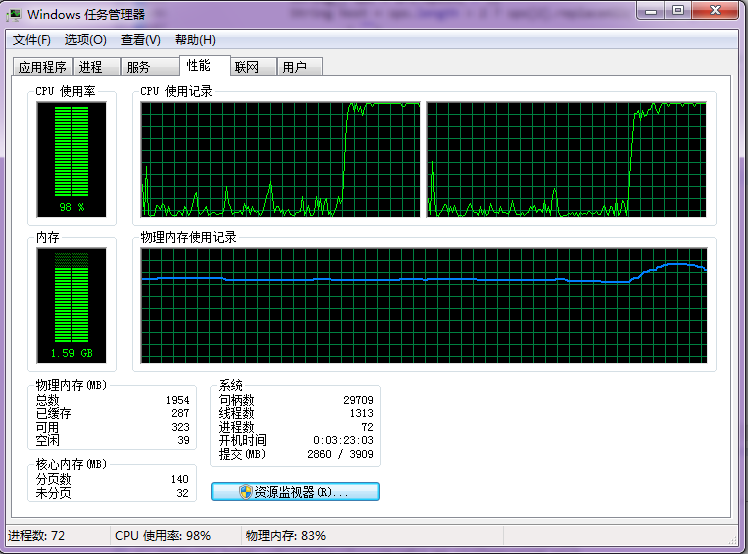
?
?
?
4 ¬• fair_jm 2013-11-11 hk_one –¥µ¿is crawler,not crawer.