[大数据量]布隆过滤器(Bloom Filter)适用类型以及具体示例
一、Bloom Filter算法适用的场合
示例:
1)已知某个文件内包含一些电话号码,每个号码为8位数字,统计不同号码的个数。8位最多99 999 999,大概需要99m个bit,大概10几m字节的内存即可。 (可以理解为从0-99 999 999的数字,每个数字对应一个Bit位,所以只需要99M个Bit==1.2MBytes,这样,就用了小小的1.2M左右的内存表示了所有的8位数的电话)2)2.5亿个整数中找出不重复的整数的个数,内存空间不足以容纳这2.5亿个整数。将bit-map扩展一下,用2bit表示一个数即可,0表示未出现,1表示出现一次,2表示出现2次及以上,在遍历这些数的时候,如果对应位置的值是0,则将其置为1;如果是1,将其置为2;如果是2,则保持不变。或者我们不用2bit来进行表示,我们用两个bit-map即可模拟实现这个2bit-map,都是一样的道理。3)问题实例:给你A,B两个文件,各存放50亿条URL,每条URL占用64字节,内存限制是4G,让你找出A,B文件共同的URL。如果是三个乃至n个文件呢? 解决方案:将数据文件分割为20个文件,然后将每个文件内的url进行hashcode计算,然后存入长度为该hashcode结果值最大值得长度的BitSet中,例如hashcode最大值为99999999,那么bitset的大小就应该是9千多万位,实际上bitset大小最多可容纳2的32次方位,即4294967296,40多亿,如果存在此Hashcode则为1,否则为0,最后将所有位为1的数据取出来就去重了。此为单bitset想法,而布隆算法其实就是多个bitset,多个hash,防止冲突而已4)假设要你写一个网络蜘蛛(web crawler)。由于网络间的链接错综复杂,蜘蛛在网络间爬行很可能会形成“环”。为了避免形成“环”,就需要知道蜘蛛已经访问过那些URL。给一个URL,怎样知道蜘蛛是否已经访问过呢?简单的来说就是大数据量文件的查找或者去重类似这样的场景
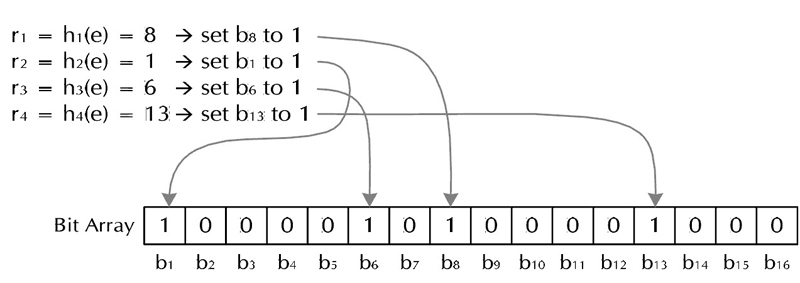
1. 将访问过的URL保存到数据库。 2. 用HashSet将访问过的URL保存起来。那只需接近O(1)的代价就可以查到一个URL是否被访问过了。 3. URL经过MD5或SHA-1等单向哈希后再保存到HashSet或数据库。 4. Bit-Map方法。建立一个BitSet,将每个URL经过一个哈希函数映射到某一位。 方法1~3都是将访问过的URL完整保存,方法4则只标记URL的一个映射位。 以上方法在数据量较小的情况下都能完美解决问题,但是当数据量变得非常庞大时问题就来了。 方法1的缺点:数据量变得非常庞大后关系型数据库查询的效率会变得很低。而且每来一个URL就启动一次数据库查询是不是太小题大做了? 方法2的缺点:太消耗内存。随着URL的增多,占用的内存会越来越多。就算只有1亿个URL,每个URL只算50个字符,就需要5GB内存。 方法3:由于字符串经过MD5处理后的信息摘要长度只有128Bit,SHA-1处理后也只有160Bit,因此方法3比方法2节省了好几倍的内存。 方法4消耗内存是相对较少的,但缺点是单一哈希函数发生冲突的概率太高。还记得数据结构课上学过的Hash表冲突的各种解决方法么?若要降低冲突发生的概率到1%,就要将BitSet的长度设置为URL个数的100倍。 实质上上面的算法都忽略了一个重要的隐含条件:允许小概率的出错,不一定要100%准确!也就是说少量url实际上没有没网络蜘蛛访问,而将它们错判为已访问的代价是很小的――大不了少抓几个网页呗。
import java.util.BitSet;public class BloomFilter { /* BitSet初始分配2^24个bit */ private static final int DEFAULT_SIZE = 1 << 25; /* 不同哈希函数的种子,一般应取质数 */ private static final int[] seeds = new int[] { 5, 7, 11, 13, 31, 37, 61 }; private BitSet bits = new BitSet(DEFAULT_SIZE); /* 哈希函数对象 */ private SimpleHash[] func = new SimpleHash[seeds.length]; public BloomFilter() { for (int i = 0; i < seeds.length; i++) { System.out.println(DEFAULT_SIZE); func[i] = new SimpleHash(DEFAULT_SIZE, seeds[i]); } } // 将字符串标记到bits中 public void add(String value) { for (SimpleHash f : func) { bits.set(f.hash(value), true); } } //判断字符串是否已经被bits标记 public boolean contains(String value) { if (value == null) { return false; } boolean ret = true; for (SimpleHash f : func) { ret = ret && bits.get(f.hash(value)); } return ret; } /* 哈希函数类 */ public static class SimpleHash { private int cap; private int seed; public SimpleHash(int cap, int seed) { this.cap = cap; this.seed = seed; } //hash函数,采用简单的加权和hash public int hash(String value) { int result = 0; int len = value.length(); for (int i = 0; i < len; i++) { result = seed * result + value.charAt(i); } return (cap - 1) & result; } } public static void main(String [] args){ BloomFilter bf =new BloomFilter(); bf.add("5"); boolean bool=bf.contains("5"); System.out.println(bool); }}