Tomcat 假死原因分析
?????????????????????????????????????????? Tomcat 假死原因分析报告
?
??? 最近监控服务发现有台tomcat 的应用出现了无法访问的情况,由于已做了集群,基本没有影响线上服务的正常使用。下面来简单描述该台tomcat当时具体的表现:客户端请求没有响应,查看服务器端tomcat 的java 进程存活,查看tomcat 的catalina.log ,没有发现异常,也没有error 日志.查看localhost_access.log 也没有最新的访问日志,该台tomcat 已不能提供服务。
??? 根据前面的假死表象,最先想到的是网络是否出现了问题,于是开始从请求的数据流程开始分析。由于业务的架构采用的是nginx + tomcat 的集群配置,一个请求上来的流向可以用下图来简单的描述。
???????????? 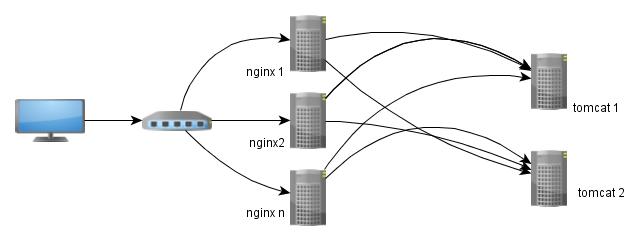
? ? ?? ??? 从上图可以看出,如果是网络的原因,可以从两个点进行分析。
??? 1、从前端到nginx的网络情况;
??????????????????? 分析nginx上的access.log ,在其中一台上可以查出当时该条请求的访问日志,也就是说可以排除这段网络的问题。
??? 2、从nginx 到tomcat 的网络情况。
??? 分析tomcat 的访问日志localhost_acess.log 上无法查出该条请求的访问日志。可以怀疑是否网络有问题。就该情况,从该台nginx ping 了一下tomcat server ,均为正常,没有发现问题。既然网络貌似没有问题,开始怀疑是tomcat本身的问题,在tomcat本机直接curl 调用该条请求,发现仍然没有响应。到此基本可以断定网络没有问题,tomcat 本身出现了假死的情况。
??? 基于tomcat 假死的情况,开始分析有可能的原因。造成tomcat假死有可能的情况大概有以下几种:
??? 一、tomcat jvm 内存溢出
????????? 分析当时的gc.log? ,
7581861.927: [GC 7581861.927: [ParNew
Desired survivor size 76677120 bytes, new threshold 15 (max 15)
- age?? 1:??? 5239168 bytes,??? 5239168 total
: 749056K->10477K(898816K), 0.0088550 secs] 1418818K->680239K(8238848K), 0.0090350 secs]
???? 没有发现有内存溢出的情况
??? 直接grep catalina.sh 也没有结果,证明没有发生内存溢出的情况 ,,这种假死可能可以排除。
??? grep OutOfMemoryException catalina.sh
?
?
??? 二、jvm GC 时间过长,导致应用暂停
?????? 7581088.402: [Full GC (System) 7581088.402: [CMS: 661091K->669762K(7340032K), 1.7206330 secs] 848607K->669762K(8238848K), [CMS Perm : 34999K->34976K(58372K)], 1.7209480 secs] [Times: user=1.72 sys=0.00, real=1.72 secs]
????? 最近的一次full gc 显示,也不应该会暂停几分钟的情况,这种假死可能可以排除。
?
??? 三、load 太高,已经超出服务的极限
???????? 当时top一下linux
???????? top?
?load average: 0.02, 0.02, 0.00
Tasks: 272 total,?? 1 running, 271 sleeping,?? 0 stopped,?? 0 zombie
Cpu(s):? 0.2%us,? 0.2%sy,? 0.0%ni, 99.6%id,? 0.0%wa,? 0.0%hi,? 0.0%si,? 0.0%st
Mem:? 32950500k total, 23173908k used,? 9776592k free,? 1381456k buffers
Swap: 33551744k total,????? 236k used, 33551508k free, 12320412k cached
???????? load 并不是高,,这种假死可能可以排除。
??? 四、应用本身程序的问题,造成死锁。
???????? 针对这种情况,做了一下jstack,有少量线程处于TIMED_WAITING。
"Ice.ThreadPool.Client-75" daemon prio=10 tid=0x000000005c5ed800 nid=0x4cde in Object.wait() [0x0000000047738000]
?? java.lang.Thread.State: TIMED_WAITING (on object monitor)
??????? at java.lang.Object.wait(Native Method)
??????? - waiting on <0x00002aab14336a10> (a IceInternal.ThreadPool)
??????? at IceInternal.ThreadPool.followerWait(ThreadPool.java:554)
??????? - locked <0x00002aab14336a10> (a IceInternal.ThreadPool)
??????? at IceInternal.ThreadPool.run(ThreadPool.java:344)
??????? - locked <0x00002aab14336a10> (a IceInternal.ThreadPool)
??????? at IceInternal.ThreadPool.access$300(ThreadPool.java:12)
??????? at IceInternal.ThreadPool$EventHandlerThread.run(ThreadPool.java:643)
??????? at java.lang.Thread.run(Thread.java:619)
??????? "ContainerBackgroundProcessor[StandardEngine[Catalina]]" daemon prio=10 tid=0x00002aacc4347800 nid=0x651 waiting on condition [0x00000000435f7000]
?? java.lang.Thread.State: TIMED_WAITING (sleeping)
??????? at java.lang.Thread.sleep(Native Method)
??????? at org.apache.catalina.core.ContainerBase$ContainerBackgroundProcessor.run(ContainerBase.java:1378)
??????? at java.lang.Thread.run(Thread.java:619)
"version sniffer" daemon prio=10 tid=0x00002aacc4377000 nid=0x645 in Object.wait() [0x0000000040f3c000]
?? java.lang.Thread.State: TIMED_WAITING (on object monitor)
??????? at java.lang.Object.wait(Native Method)
??????? - waiting on <0x00002aaaee20b7b8> (a java.lang.Boolean)
??????? at com.panguso.map.web.service.LocateServiceFactory$IpDataVersionSniffer.run(LocateServiceFactory.java:351)
??????? - locked <0x00002aaaee20b7b8> (a java.lang.Boolean)
??????? at java.lang.Thread.run(Thread.java:619)
"ReplicaSetStatus:Updater" daemon prio=10 tid=0x000000005d070800 nid=0x636 waiting on condition [0x0000000044001000]
?? java.lang.Thread.State: TIMED_WAITING (sleeping)
??????? at java.lang.Thread.sleep(Native Method)
??????? at com.mongodb.ReplicaSetStatus$Updater.run(ReplicaSetStatus.java:428)
?
??? 从jvm 堆栈信息可以看出,其中有可能出现线程锁死的情况为:IceInternal 和访问mongdb 的客户端 com.mongodb.ReplicaSetStatus$Updater类。针对这两种情况,看了一下源码,基本排除。
?
?
??? 五、大量tcp 连接CLOSE_WAIT
netstat-n | awk '/^tcp/ {++S[$NF]} END {for(a in S) print a, S[a]}'?
CLOSE_WAIT 从上面的图可以看出来,如果一直保持在CLOSE_WAIT状态,那么只有一种情况,就是在对方关闭连接之后,服务器程序自己没有进一步发出ack信号。换句话说,就是在对方连接关闭之后,程序里没有检测到,或者程序压根就忘记了这个时候需要关闭连接,于是这个资源就一直被程序占着。个人觉得这种情况,通过服务器内核参数也没办法解决,服务器对于程序抢占的资源没有主动回收的权利,除非终止程序运行。
由于咱们自己使用的是HttpClient,并且遇到了大量CLOSE_WAIT的情况。所以怀疑这个点可能出了问题。
查看了咱们的httpClient 的写法需要改正:
HttpGet get = new HttpGet(url.toString());
??????? InputStreamins = null;
??????? try {
??????????? HttpResponseresponse = excuteHttp(httpClient, get);
??????????? //HttpResponse response = httpClient.execute(get);
?
??????????? if(response.getStatusLine().getStatusCode() != 200) {
??????????????? ?
??????????????? throw newMapabcPoiRequestException(
??????????????? ??????? "Httpresponse status is not OK");
??????????? }
?
这种写法意味着一旦出现非200的连接,InputStream ins 根本就不会被赋值,这个连接将永远僵死在连接池里头.
解决方法:
if (response.getStatusLine().getStatusCode() !=200) {
??????????????? get.abort();
??????????? ?
??????????????? throw newMapabcPoiRequestException(
?
??????????????? ??????? "Httpresponse status is not OK");
??????????? }
应该改为显示调用HttpGet的abort,这样就会直接中止这次连接,我们在遇到异常的时候应该显示调用,因为无法保证异常是在InputStream in赋值之后才抛出。但是这种情况也是发生在httpClient后端的服务出现了没有响应的情况,
?
?
?
?
?
?
?
?
?
?
?
?
?