Coherence企业级缓存特点摘要:Oracle Coherence是一个企业级的分布式集群缓存框架。具有自管理,自恢复,高可
Coherence企业级缓存特点
摘要:Oracle Coherence是一个企业级的分布式集群缓存框架。具有自管理,自恢复,高可用性,高扩展性等优良特点,在电信BOSS等项目中有很大的应用价值。本文对它的特点,架构,基本使用方法,JMX管理,调优等进行简要但快捷的介绍,并对于Hibernate的集成过程进行说明,为BOSS,CMP等移动项目提供一个的参考。
关键词:分布式缓存 Coherence
网上除了官方用户指南,关于Coherence的介绍文章资料很少,因此总结出此文,从原理到快速指南和基本最佳实践,希望对需要的人提供一个参考。
1 Coherence 概述
1.1 Coherence是什么
Oracle官方网站的描述是:Coherence 在可靠的、高度可伸缩的对等集群协议之上提供了复制的、分布式的(分区的)数据管理和缓存服务。Coherence 不存在单点故障,当某台服务器无法操作或从网络断开时,它可以自动且透明地进行故障切换并重新分布它的集群化数据管理服务。当新服务器加入或故障服务器重 启时,它会自动加入集群,Coherence 会将服务切回到该服务器,透明地重新分布集群负载。Coherence 包含网络级的容错特性和透明的软重启功能,以支持服务器自我修复。
----来自Oracle Coherence 专区
http://www.oracle.com/technology/global/cn/products/coherence/index.html
一个典型的Hibernate应用 + Coherence集群如下图所示:
[img]http://raymondhekk.iteye.com/upload/attachment/44312/24357740-45f4-3cd8-9e95-05f7d1301197.jpg[img]
1.2 Coherence的特点
1.2.1 分布式集群缓存
Coherence是一个分布式的缓存方案,并且通过集群为应用提供强大的缓存后备支持。Coherence主要是内存缓存,即存储区域主要在内存当中。
与一般的分布式缓存方案如JBossCache, Memcache 等相同,分布式缓存的价值基于网络IO性能高于DB查询的磁盘IO性能这样一个特点。
Coherence所有的设计都是基于多个(可以是非常多)的JVM,很多Coherence的测试都是使用几十甚至上百个节点来进行的。
下图展示了一个典型的WAS项目架构:WAS集群 + Near型Coherence集群架构。对于大型Web2.0网站(PHP或其他),集成Coherence也是类似的。

1.2.2自管理
Coherence使用的网络协议是TCMP ,是对UDP,TCP/IP的组合使用。Coherence能将启动的实例节点(Node)自动组成为集群(Cluster)。在一个局域网环境中,通过多播(Multicast)机制,第1个启动的Node能自动发现后启动的Node,第1,2个Node同样能发现之后启动的其他Node,依次类推,自动组成集群; 并且也能自动检测到死亡节点。集群各节点间通过单播(Unicast)机制进行数据复制,同步及发送通知消息。
Coherence集群以统一的逻辑试图对外提供缓存的读写接口,看起来使用Coherence Client就像在使用一个缓存一样。
1.2.3 自动容错和恢复
基于自管理的特点,一个Node挂掉后,集群能自动监测到,并做好死亡节点的数据恢复机制,客户端依然能正确的读出在死亡节点上存储的数据,容错和恢复对客户端来说是透明的。
1.2.4 分区缓存(Partitioned Cache)
这是Coherence与众不同的地方。一般集群如:JBossCache, Websphere 集群等,每个Node都有数据的完整拷贝,Node间通过复制来实现数据同步和一致性,一般来说采用全复制模式,即一份数据在各节点上都有一份拷贝。这种模式下,节点要存储了较多的数据,同步复制时比较消耗网络带宽。
而Coherence的分区缓存只将一个Node上的数据在另一节点上做1个备份,有效降低复制的消耗好时间,并节省内存总需求,只需复制模式的1/N (N为缓存节点个数)。
1.2.5 线性扩展
假如你的Coherence集群已经有4个Node,当系统数据量过大引起Cache容量满员,导致缓存性能下降时,可以通过启动新的Node来扩容,改善集群的性能。
这一点也是源自分区缓存技术,集群有N个Node,每个Node只存放1/N的数据,这种设计让Coherence能够处理非常多的数据,只需要通过增加节点的数量,就可以处理更多的数据。
下图为例,当两台机器,4个存储Node不够用时,通过新增机器,新增Node实例即可自动加入集群,提升Coherence缓存性能。
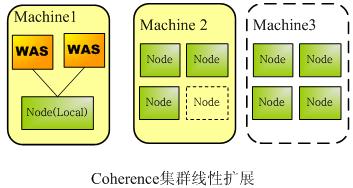
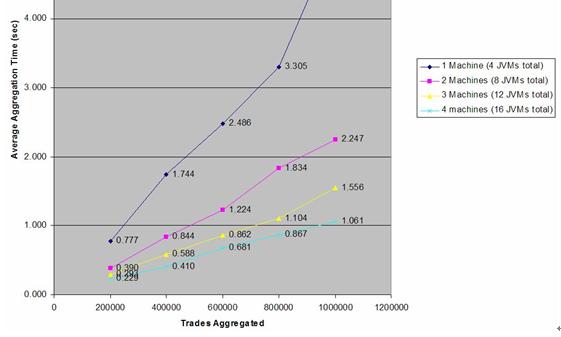
线性扩展更重要体现在性能上,下图展示了,Coherence集群通过增加机器,增加Node实例使得交易耗时大幅降低,而且随着集群规模呈线性下降。
1.2.6易用性
虽然上述特点看起来似乎很复杂,但那都是Coherence自己内部的事儿。对于客户端来说,与最简单的Map 操作一样,仅仅是 put(key,value), get(key) 等。
cache.put(key,value)
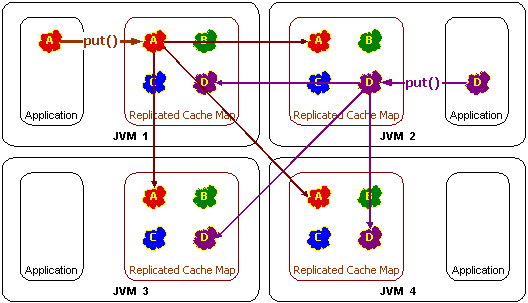
这是一种传统的集群技术,不是Coherence的亮点。
4.1 乐观缓存 (Optimistic Cache)
它类似于复制缓存,但不提供并发控制(Concurrency Control)。这种集群数据吞吐量最高,各节点容易出现数据不一致的情况。
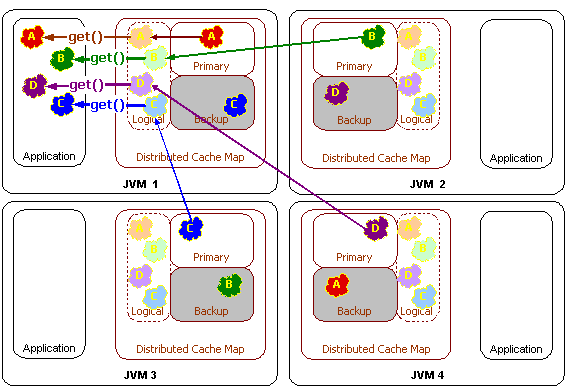
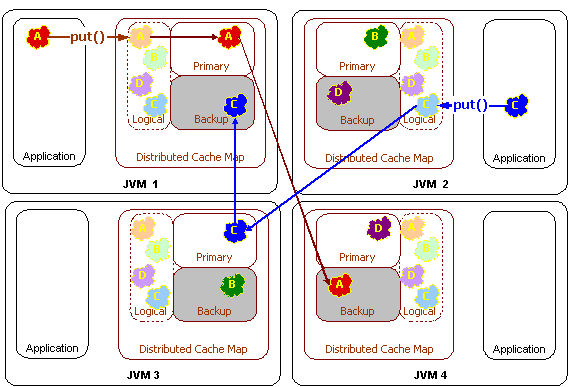
4.1 分区缓存 (Distributed (Partitioned) Cache)
Coherence 的亮点。默认情况下,一份数据A只在两个节点上有拷贝,第二份作为备份数据(Backup),用于容错。
从整体上看,假设应用需要的Cache总内存为 M,该模式将数据分散到N个节点上,每个JVM只占用 M/N 的内存消耗,与复制缓存每节点消耗 M量的内存形成对比,它可以极大节省内存资源。
cache.get(key)
cache.put(key,value)
4.1 Near缓存 (NearCache)
分区缓存的改进版。分区缓存将数据全部存到Cache Node上,而Near缓存将缓存数据中使用频率最高的数据(热点数据Hotspot)放到应用的本地缓存(Local Cache)区域。由于本地内存访问的高效性,它可以有效提升分区缓存的read性能。
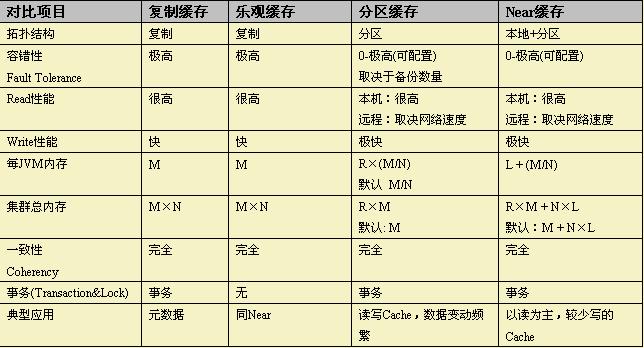
四种缓存类型的基本特点对比如下表所示:
几个重要因素:
JVM数量(N): 即启动的Node数量,每个节点为一个JVM进程;
数据大小(M):要缓存的数据总量的占用空间大小,如10M,120M等;
冗余度(R) :缓存的secondary备份个数。分区缓存默认为1,可以配置2,3,…
本地缓存大小(L):(仅对Near缓存而言)应用所在的本地缓存的空间大小字节数。
几种类型的对比
Coherence企业级缓存(四) 数据管理模式
Coherence提供了四种Cache数据管理模式:
Read-Through,
Write-Through,
Refresh-Ahead
Write-Behind
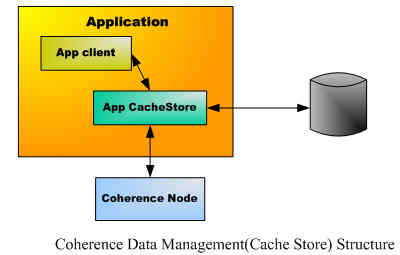
数据管理模式体现在CacheStore 接口的功能上。
CacheStore负责直接和数据源交互,进行增删改查操作;并也负责和Coherence Cache交互,向其中写数据(put),读数据(get)和删除数据(remove)。CacheStore相当于 数据源和Cache间的桥梁。
对于不同的应用,由于数据源不同,如:DB,WebService ,FileSystem等, CacheStore有不同的实现。它一般作为应用的一部分。Coherence也为 Hibernate,Toplink等实现了一个CacheStore。
5.1 Read-Through
Read-Through 的基本特点是同步读取。步骤为:
1)应用调用 CacheStore 查询数据X;
2)CacheStore 去Cache中查询,未发现数据时,向数据库执行查询操作,并将查询结果放到 Cache中, 并将结果返回给应用;
3)如果发现Cache中有数据,则直接从Cache读取,并返回给应用。
其特点体现在第二步,CacheStore调用 cache.get(X) 到 CacheStore 给应用返回数据,是同步操作。 也就是要在一个同步过程中先等待数据查询,Cache被填充,才能获得数据。 这种模式的性能比较低,不及 Refresh-Ahead。
5.2 Write-Through
Write-Through 对应于数据修改操作,如 update,也具有同步的特点。
1)应用调用 CacheStore update数据X;
2)CacheStore 先update Cache中的数据,然后再向数据库执行update操作;
这种模式在一个同步过程中,先改Cache,再改数据库。因此性能也不是最理想的。
5.2 Refresh-Ahead
与Read-Through相对,它是异步的。
Coherence在Cache数据过期前,有CacheStore自动重新从数据库加载数据。而前台应用在查询数据时,CacheStore 仅调用Cache.get(X)。因此这种模式的效率明显高于read-through。 自动重载数据的时间可以设定。
5.2 Write-behind
与write-through相对,它是异步的。
应用调用CacheStore进行update时,CacheStore不去操作数据库,直接返回结果。而Coherence集群自动对操作进行排队(queue),在间隔一段时间后(interval), CacheStore在执行队列中的 update 操作。 这样,减少的同步操作数据库的时间被节省,修改类功能的性能就能得到大幅提高。这也是Coherence的一大特色。
Coherence企业级缓存(六) JMX 管理和监控
7.1 概述
Coherence支持集群JMX管理和监控,方便在多Node环境下的统一管理。
根据Coherence官方的推荐,一般一个集群中只设置一个JMX管理服务器(MBeanServer),并且管理服务器不存储数据(设置启动参数storage_enabled=false);其他Node为受管节点,存储数据。
7.2 启动参数
要为节点启用JMX管理,启动时只要加入必要的java property即可。一般可以JDK5+自带的JConsole工具做管理和监控。
JMX Server:
图中,
Cluster代表整个集群
Node节点下代表各节点,图中有1,2 两个节点;
Cache目录代表当前集群中创建的的NamedCache,图中展示了集群中有一个分区缓存 cache1,存储在节点2 中。
其他还有Server,StorageManager,PointToPoint等管理项。
右侧列出了所选项目的详细属性,图中为Node 2 上数据存储的信息,比较有用的是
命中次数CacheHits,
失误次数CacheMisses,
缓存访问次数:TotalGets,通过 CacheHits/ TotalGets 就可得到命中率
缓存元素上限:HighUnits等。
通过观察各节点Cache的主要指标,就可以监控Coherence的运行情况,分析缓存的利用效率。见下图例:
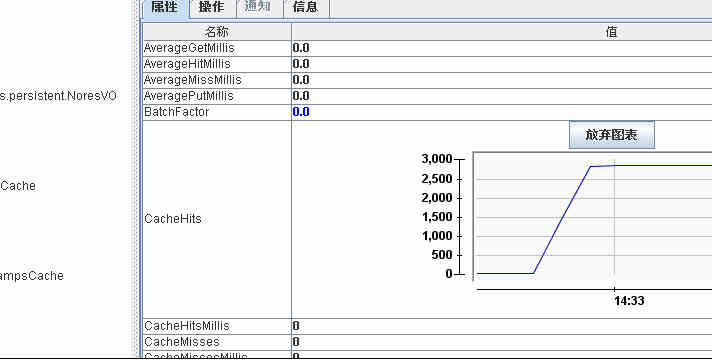
图显示了在JOP号码资源应用下,号码资源VO的CacheHits变化情况,命中数在逐步提高,为2800,说明缓存有效发挥了其作用;当然命中率是反映Cache利用率更为直观的指标。
7.4 Node监控
通过连接不同Node,还可以监控各存储节点的内存变化等信息,为调优提供必要依据。
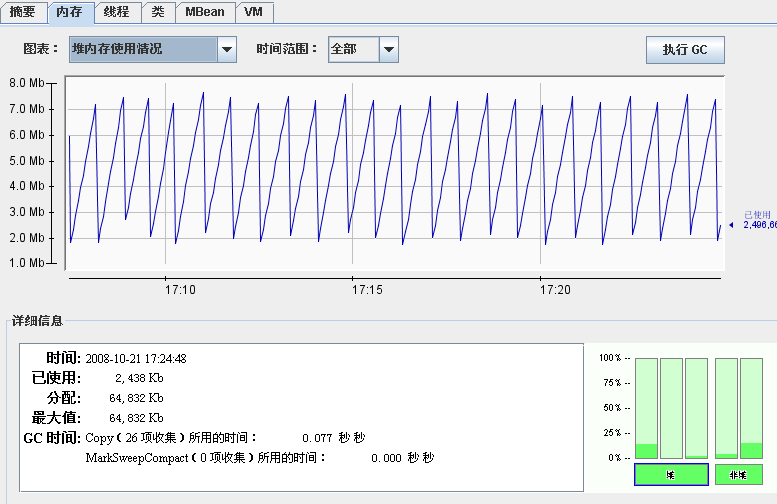
Coherence企业级缓存(七) 性能调优
Coherence调优是很关键的一环,特别是对大型企业级应用,海量数据型应用,它将决定Coherence集群能否将效能最大化的发挥出来。
调优通常分三步:基础调优,运行前常规调优,运行后调优
8.1基础调优
包括操作系统调优,网络调优
操作系统的一些参数,对Coherence集群的数据传输有影响。
如:非Wins系统下Socket缓冲大小,应该至少增加到2M;Windows上的Datagram大小等,这些在官方指南中有详细的说明。
网络调优主要对交换机缓冲(Switch Buffer), Path MTU 等因素,比较常见的情况是,交换机缓存如果太小,Coherence在做Node通信时会发生延迟,Node日志一般为:
应用分析:
如果为了简便,在Coherence配置中使用 * 配置NamedCache的存储属性,那么意味着,所有NamedCache或者说一部分Cache 使用了相同的设置,如元素个数,超时时间,清除策略,前端缓存大小等。
<cache-mapping> <!―Hiberante Entity cache configuration --> <cache-name>*</cache-name> <!― 类似配置如:near-*, com.xxx.crm.customer.* ?--> <scheme-name>hibernate-near</scheme-name> <init-params> <init-param> <!-- 后端entry个数限制 --> <param-name>back-size-limit</param-name> <param-value>1000</param-value> </init-param> <init-param> <!-- 后端超时时间 30m --> <param-name>back-expiry</param-name> <param-value>30m</param-value> </init-param> </init-params> </cache-mapping> <cache-mapping> <!―Hiberante Entity cache configuration --> <cache-name>*</cache-name> <!― 类似配置如:near-*, com.xxx.crm.customer.* ?--> <scheme-name>hibernate-near</scheme-name> <init-params> <init-param> <!-- 后端entry个数限制 --> <param-name>back-size-limit</param-name> <param-value>1000</param-value> </init-param> <init-param> <!-- 后端超时时间 30m --> <param-name>back-expiry</param-name> <param-value>30m</param-value> </init-param> </init-params></cache-mapping>
但不同业务功能其数据量大小,查询频率,查询条件的多样性,数据修改的频率都是不同的,如果配置相同,则Cache机制在不同业务上体现的性能是不同的,应该区别对待,例如:
1) 数据字典修改频率极低,可以只采用local cache, 超时时间设置长一些,例如12h 。
2) 鉴权操作频率很高,因此要求高性能。鉴权数据中权限点修改频率低,但角色授权数据修改频率略高,但比一般业务也低很多,可以将 front cache设置大一些,或者只采用local访问。
3) 在Hibernate中,低频修改数据缓存配置为 nonstrict-read-write 类型;只读数据采用 read-only 型。
4) 至于业务数据,情况比较复杂。
例如:手机号码表,数据量极大,并且服务于BOSS大部分业务,并且手机号码的用户资料变更较少,因此缓存可以设置大些, 超时时间设置长些。而类似的渠道数据,数据量略小一些,HighUnits可设置稍小一些。
而对于一些修改频繁,或新增频繁的数据,超时时间(Expiry Delay) 应当设置小一些。
此类分析应该跟踪生产环境的运行情况,业务频率,修改操作频率等,进行调整优化,并跟踪调优后的结果。
9. 结束
Oracle Coherence具有一般缓存框架的极不一样的强大特性,自管理,分区缓存,线性扩展等使得它能有效提升应用,特别是大型企业级应用的性能。Coherence也是一个网格计算方案,其线性扩展也体现了“另类”的系统架构,能发挥出强大的功能。
参考资料:
1. Oracle. Coherence User-guide.htm
2. http://www.oracle.com/technology/global/cn/products/coherence/index.html
3. iniu blog http://iniu.net/iwork/2008/02/oracle-coherence.html









