重排序与volatile的介绍和资料
?
? ? ??指令重排序的原因:对主存的一次访问一般花费硬件的数百次时钟周期。处理器通过缓存(寄存器、cpu缓存等)能够从数量级上降低内存延迟的成本这些缓存为了性能重新排列待定内存操作的顺序。也就是说,程序的读写操作不一定会按照它要求处理器的顺序执行。
编译期重排序的典型就是通过调整指令顺序,在不改变程序语义的前提下,尽可能减少寄存器的读取、存储次数,充分复用寄存器的存储值。
假设第一条指令计算一个值赋给变量A并存放在寄存器中,第二条指令与A无关但需要占用寄存器(假设它将占用A所在的那个寄存器),第三条指令使用A的值且与第二条指令无关。那么如果按照顺序一致性模型,A在第一条指令执行过后被放入寄存器,在第二条指令执行时A不再存在,第三条指令执行时A重新被读入寄存器,而这个过程中,A的值没有发生变化。通常编译器都会交换第二和第三条指令的位置,这样第一条指令结束时A存在于寄存器中,接下来可以直接从寄存器中读取A的值,降低了重复读取的开销。
在程序运行中,程序可能会对一些经常被运行的执行进行重排序,从而提高性能。而且在硬件方面有些架构也会对一些指令进行重排序执行。
现代CPU几乎都采用流水线机制加快指令的处理速度,一般来说,一条指令需要若干个CPU时钟周期处理,而通过流水线并行执行,可以在同等的时钟周期内执行若干条指令,具体做法简单地说就是把指令分为不同的执行周期,例如读取、寻址、解析、执行等步骤,并放在不同的元件中处理,同时在执行单元EU中,功能单元被分为不同的元件,例如加法元件、乘法元件、加载元件、存储元件等,可以进一步实现不同的计算并行执行。
流水线架构决定了指令应该被并行执行,而不是在顺序化模型中所认为的那样。重排序有利于充分使用流水线,进而达到超标量的效果。
尽管指令在执行时并不一定按照我们所编写的顺序执行,但毋庸置疑的是,在单线程环境下,指令执行的最终效果应当与其在顺序执行下的效果一致,否则这种优化便会失去意义。
通常无论是在编译期还是运行期进行的指令重排序,都会满足上面的原则。
?
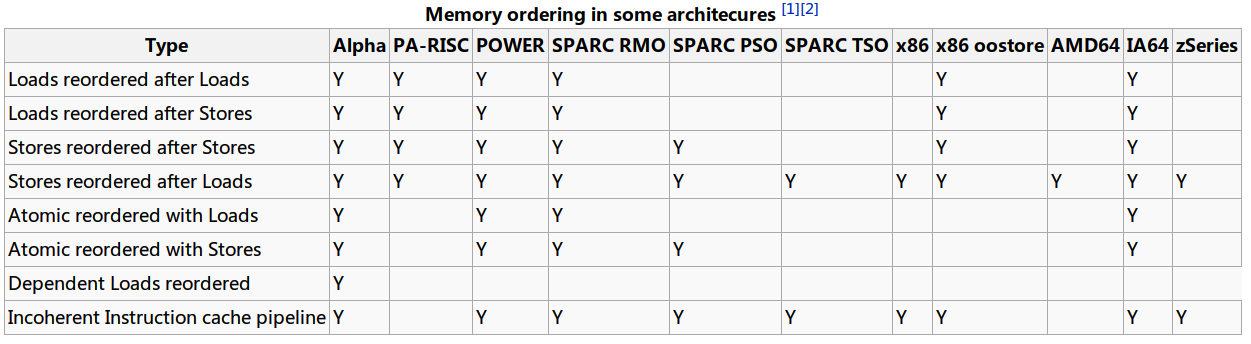
从图中,可以看到,X86仅在?Stores after loads?和?Incoherent instruction cache pipeline?中会触发重排。
Stores after loads的含义是在对同一个地址进行读写操作时,写入在读取后面,允许重排序。即满足弱一致性(Weak Consistency),这是最可被接受的类型,不会造成太大的影响。
?
?
---------------------------------------------------------------------
?
先看一下原子性是什么:
? ? ? ?原子操作是不可分割的,在执行完毕不会被任何其它任务或事件中断。在单处理器系统(UniProcessor)中,?能够在单条指令中完成的操作都可以认为是"?原子操作",因为中断只能发生于指令之间。这也是某些CPU指令系统中引入了test_and_set、test_and_clear等指令用于临界资源?互斥的原因。
? ? ? ?在对称多处理器(Symmetric Multi-Processor)结构中就不同了,由于系统中有多个处理器在独立地运行,即使能在单条指令中完成的操作也有可能受到干扰。?在x86?平台上,CPU提供了在指令执行期间对总线加锁的手段。CPU芯片上有一条引线#HLOCK pin,如果汇编语言的程序中在一条指令前面加上前缀"LOCK",经过汇编以后的机器代码就使CPU在执行这条指令的时候把#HLOCK pin的电位拉低,持续到这条指令结束时放开,从而把总线锁住,这样同一总线上别的CPU就暂时不能通过总线访问内存了,保证了这条指令在多处理器环境中?的原子性。
? ? ? ? ?锁总线是非常损耗性能的,目前的CPU一般都采用了很好的缓存一致性协议,在很多情况下能够防止锁总线的发生,这其中最著名的就是Intel CPU中使用的MESI缓存一致性协议。
?
优化屏障/内存屏障
-------------------------------
? ? ?对于比方说io操作而言??要避免的问题包括像指令的重排优化(包括高速缓存的使用)?以及处理器的乱序执行解决这些问题所提出的方法也就是优化屏障和内存屏障
? ? ?linux中的优化屏障也就是barrier宏它所解决的问题就是指令的重排优化ldd3给出的解释是这个函数通知编译器插入一个内存屏障(注意?是内存屏障也间接的说明了linux中优化屏障和内存屏障的关系)但对硬件没有影响。编译后的代码会把当前cpu寄存器所有修改过的数值保存到内存中?需要这些数据的时候再重新读出来。对barrier的调用可以避免在屏障前后的编译器优化,但硬件能完成自己的重新排序。
? ? ?总结一下ulk3和ldd3在linux中优化屏障其实就是一种特殊的内存屏障它负责防止编译器的指令重排和优化?但不对cpu的乱序执行负责。在看下ldd3对mb系列的函数这样解释:这些函数在已编译的指令流中插入硬件内存屏障。。。。这些函数(指rmb wmb)都是barrier的超集。
? ? ?也就是说linux中的内存屏障有两种一种是软件内存屏障?它们负责对编译器起作用也就是ulk中提到的优化屏障还有一种就是上面提到的硬件内存屏障也就是我们通常所说的内存屏障它做为前者的超集不但对软件起作用同时对硬件也起作用
?
内存屏障主要解决的问题是编译器的优化和CPU的乱序执行。
? ? ??编译器在优化的时候,生成的汇编指令可能和c语言程序的执行顺序不一样,在需要程序严格按照c语言顺序执行时,需要显式的告诉编译不需要优化,这在linux下是通过barrier()宏完成的,它依靠volidate关键字和memory关键字,前者告诉编译barrier()周围的指令不要被优化,后者作用是告诉编译器汇编代码会使内存里面的值更改,编译器应使用内存里的新值而非寄存器里保存的老值。
? ? ??同样,CPU执行会通过乱序以提高性能。汇编里的指令不一定是按照我们看到的顺序执行的。linux中通过mb()系列宏来保证执行的顺序。具体做法是通过mfence/lfence指令(它们是奔4后引进的,早期x86没有)以及x86指令中带有串行特性的指令(这样的指令很多,例如linux中实现时用到的lock指令,I/O指令,操作控制寄存器、系统寄存器、调试寄存器的指令、iret指令等等)。简单的说,如果在程序某处插入了mb()/rmb()/wmb()宏,则宏之前的程序保证比宏之后的程序先执行,从而实现串行化。wmb的实现和barrier()类似,是因为在x86平台上,写内存的操作不会被乱序执行。
实际上在RSIC平台上,这些串行工作都有专门的指令由程序员显式的完成,比如在需要的地方调用串行指令,而不像x86上有这么多隐性的带有串行特性指令(例如lock指令)。所以在risc平台下工作的朋友通常对串行化操作理解的容易些。
?
? ? ? wmb、rmb为什么是barrier的超集?是因为wmb和rmb都有volidate关键字修饰,而barrier的功能就来源于该关键字。volidate关键字能让多大范围的指令不重排?”让多大范围的指令不重排”的提法本身就是错的。volidate实际是个点,这个点后的代码对应的指令不能出现在该点之前;之前的代码对应的指令不能出现在改点之后。
? ? ??在x86平台下,wmb和barrier是一样的?那是因为x86的写是顺序的,不会乱序。
--------------------------------------
?
?
#include?<linux/kernel.h>?void?barrier(void)?/*告知编译器插入一个内存屏障但是对硬件没有影响。编译后的代码会将当前CPU?寄存器中所有修改过的数值保存到内存中,?并当需要时重新读取它们。可阻止在屏障前后的编译器优化,但硬件能完成自己的重新排序。其实<linux/kernel.h>中并没有这个函数,因为它是在kernel.h包含的头文件compiler.h中定义的*/#include?<linux/compiler.h>#?define?barrier()?__memory_barrier()#include?<asm/system.h>?void?rmb(void);/*保证任何出现于屏障前的读在执行任何后续的读之前完成*/void?wmb(void);/*保证任何出现于屏障前的写在执行任何后续的写之前完成*/void?mb(void);?/*保证任何出现于屏障前的读写操作在执行任何后续的读写操作之前完成*/void?read_barrier_depends(void);?/*?一种特殊的、弱些的读屏障形式。rmb?阻止屏障前后的所有读指令的重新排序,read_barrier_depends?只阻止依赖于其他读指令返回的数据的读指令的重新排序。区别微小,?且不在所有体系中存在。除非你确切地理解它们的差别,?并确信完整的读屏障会增加系统开销,否则应当始终使用?rmb。*//*以上指令是barrier的超集*/void?smp_rmb(void);?void?smp_read_barrier_depends(void);?void?smp_wmb(void);?void?smp_mb(void);?/*仅当内核为?SMP?系统编译时插入硬件屏障;?否则,?它们都扩展为一个简单的屏障调用。*/
一个例子:?
?
#define wmb() __asm__ __volatile ("sfence":::)unsigned int a = 0;unsigned int b = 1;pthread_mutex_t lock;static void* f(void* arg){ unsigned int c,d; for(;;){ c = a; //wmb(); d = b; if (c>=d) { printf("c=%x d=%x\n",c,d); return NULL; } }}static void* g(void* arg){ for(;;){ pthread_mutex_lock (&lock); b++; a++; if (b == 0x7fffffff) { b = 1; a = 0; } pthread_mutex_unlock (&lock); }}int main(int argc, const char* argv[]){ pthread_t pid1,pid2; pthread_mutex_init (&lock, NULL); if (pthread_create(&pid1, 0, f, 0)){ printf("Create thread1 error\n"); exit(-1); } if (pthread_create(&pid2, 0, g, 0)){ printf("Create thread2 error\n"); exit(-1); } while (1) sleep(1); return 0;}?
上面代码创建了 2 个线程,线程1 在 CPU1 上执行,线程2 在 CPU2 上执行。如果因为超标量的关系,在执行过程中,c=a; 和 d=b; 两条语句互换了位置,那么得到的结果也就和预期的相反。所以为了得到正确的结果,这里可以采用专门的汇编指令来完成这个工作,这些指令分别是:lfence, sfence, mfence ,它们的原理都是停止流水线,并保证相关操作按照顺序完成。这些指令的作用如下:
lfence?: 当 CPU 遇到 lfence 指令时,停止相关流水线,直到 lfence 之前对内存读取操作的指令全部完成。
sfence?: 当 CPU 遇到 sfence 指令时,停止相关流水线,直到 sfence 之前对内存进行写入操作的指令全部完成。
mfence?: 当 CPU 遇到 mfence 指令时,停止相关流水线,直到 mfence 之前对内存进行读取和写入操作的指令全部完成。
于是,像上面的代码中,在 c=a; 和 d=b 加入这样的指令,这两条语句的执行就不会乱序了。
----------------------------------------------------
?
在Java中,可以采用volatile来当做内存屏障,防止重排序的问题
1.?确保对volatile域的读写操作都是直接在主存内进行,不缓存到线程的本地内存中。
2.?在旧的JMM中,volatile域的操作与nonvolatile域的操作之间可以重新排序。但是在JSR133以后,规定volatile操作和其他任何内存操作之间都不允许进行重新排序。
3.?在新的JMM下,当线程A写一个volatile变量V,然后线程B读取V的时侯,任何在写入V时对线程A可见的变量值,都对B可见
? ? ?java中,volatile 指令前面的一些内存操作,会不会在这个volatile相关指令执行的时候,volatile修饰的变量写回到内存中的时候,那些 no-volatile变量的内存是否也会写回到内存中,而不是保留在java的工作内存中。如果jvm、jit也像上面内容一样的插入诸如mb(),rmb()等相关的内存屏障指令的话,那么no-volatile变量,也是会写回到主内存中。具体的细节,只能看相关的实现了。
?
参考资料:
http://kenwublog.com/illustrate-memory-reordering-in-cpu(从JVM并发看CPU内存指令重排序(Memory Reordering))
?http://www.groad.net/bbs/simple/?t3246.html(重排序的一个例子)
?http://wenku.baidu.com/view/0c5a48c489eb172ded63b771.html(java内存屏障与JVM并发详解)
http://blog.csdn.net/cnctloveyu/article/details/5486339(优化屏障和内存屏障)
?
?