Lucene学习小结之二:Lucene的总体架构
Lucene学习总结之二:Lucene的总体架构Lucene总的来说是: 一个高效的,可扩展的,全文检索库。 全部用Java实现
Lucene学习总结之二:Lucene的总体架构
Lucene总的来说是:
一个高效的,可扩展的,全文检索库。 全部用Java实现,无须配置。 仅支持纯文本文件的索引(Indexing)和搜索(Search)。 不负责由其他格式的文件抽取纯文本文件,或从网络中抓取文件的过程。
在Lucene in action中,Lucene 的构架和过程如下图,
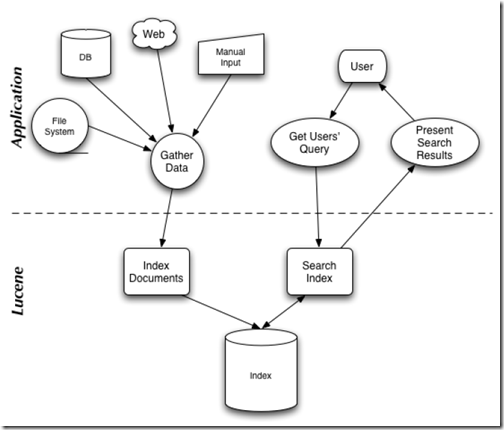
说明Lucene是有索引和搜索的两个过程,包含索引创建,索引,搜索三个要点。
让我们更细一些看Lucene的各组件:
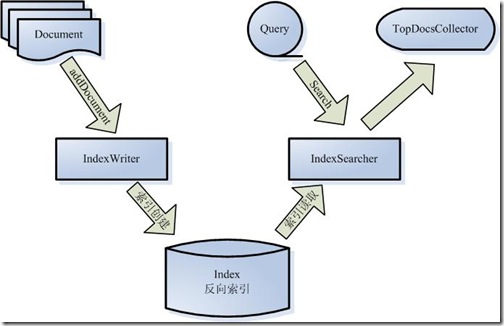
?
被索引的文档用Document对象表示。 IndexWriter通过函数addDocument将文档添加到索引中,实现创建索引的过程。 Lucene的索引是应用反向索引。 当用户有请求时,Query代表用户的查询语句。 IndexSearcher通过函数search搜索Lucene Index。 IndexSearcher计算term weight和score并且将结果返回给用户。 返回给用户的文档集合用TopDocsCollector表示。?
那么如何应用这些组件呢?
让我们再详细到对Lucene API 的调用实现索引和搜索过程。
?
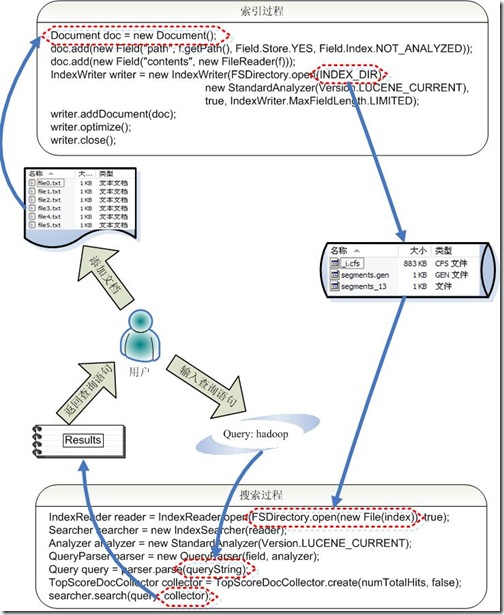
?
索引过程如下: 创建一个IndexWriter用来写索引文件,它有几个参数,INDEX_DIR就是索引文件所存放的位置,Analyzer便是用来对文档进行词法分析和语言处理的。 创建一个Document代表我们要索引的文档。 将不同的Field加入到文档中。我们知道,一篇文档有多种信息,如题目,作者,修改时间,内容等。不同类型的信息用不同的Field来表示,在本例子中,一共有两类信息进行了索引,一个是文件路径,一个是文件内容。其中FileReader的SRC_FILE就表示要索引的源文件。 IndexWriter调用函数addDocument将索引写到索引文件夹中。搜索过程如下: IndexReader将磁盘上的索引信息读入到内存,INDEX_DIR就是索引文件存放的位置。 创建IndexSearcher准备进行搜索。 创建Analyer用来对查询语句进行词法分析和语言处理。 创建QueryParser用来对查询语句进行语法分析。 QueryParser调用parser进行语法分析,形成查询语法树,放到Query中。 IndexSearcher调用search对查询语法树Query进行搜索,得到结果TopScoreDocCollector。以上便是Lucene API函数的简单调用。
然而当进入Lucene的源代码后,发现Lucene有很多包,关系错综复杂。
然而通过下图,我们不难发现,Lucene的各源码模块,都是对普通索引和搜索过程的一种实现。
此图是上一节介绍的全文检索的流程对应的Lucene实现的包结构。(参照http://www.lucene.com.cn/about.htm中文章《开放源代码的全文检索引擎Lucene》)
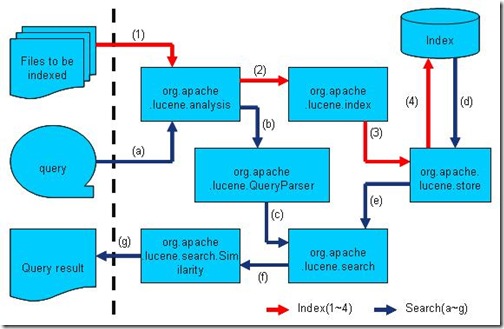
?
Lucene的analysis模块主要负责词法分析及语言处理而形成Term。 Lucene的index模块主要负责索引的创建,里面有IndexWriter。 Lucene的store模块主要负责索引的读写。 Lucene的QueryParser主要负责语法分析。 Lucene的search模块主要负责对索引的搜索。 Lucene的similarity模块主要负责对相关性打分的实现。了解了Lucene的整个结构,我们便可以开始Lucene的源码之旅了。
?
本文转载自http://www.cnblogs.com/forfuture1978/archive/2009/12/14/1623596.html
仅为自己学习所用。



