MapReduce 编程模型在日志分析方面的应用
简介
日志分析往往是商业智能的基础,而日益增长的日志信息条目使得大规模数据处理平台的出现成为必然。MapReduce 处理数据的有效性为日志分析提供了可靠的后盾。
本文将以对访问网页用户的日志进行分析,进而挖掘出用户兴趣点这一完整流程为例,详细解释 MapReduce 模型的对应实现,涵盖在 MapReduce 编程中对于特殊问题的处理技巧,比如机器学习算法、排序算法、索引机制、连接机制等。文章分三部分展开:首先介绍 MapReduce 编程模型,对其原理、对任务处理流程以及适用情况进行介绍;接下来描述了日志分析的例子 - 用户兴趣点挖掘的处理流程;最后对处理流程的几个模块分别进行了 MapReduce 的实现。本文的目的在于通过 MapReduce 在日志分析领域的具体实现,使读者对 MapReduce 对实际问题的处理有较为形象的认识。
?回页首
MapReduce 编程模型简介
随着信息化的进一步加深,在各个领域,如电信、交通、金融、零售、航天、医药等,数据量级都呈现快速增长趋势。如何高效并且无误地存储、分析、理解以及利用这些大规模数据,成为一个关键性问题。
为了应对大规模数据处理的难题,MapReduce 编程模型应运而生。Google 提出的这一模型,由于良好的易用性和可扩展性,得到了工业界和学术界的广泛支持。Hadoop,MapReduce 的开源实现,已经在 Yahoo!, Facebook, IBM, 百度 , 中国移动等多家单位中使用。
MapReduce 编程模型
MapReduce 以函数方式提供了 Map 和 Reduce 来进行分布式计算。Map 相对独立且并行运行,对存储系统中的文件按行处理,并产生键值(key/value)对。Reduce 以 Map 的输出作为输入,相同 key 的记录汇聚到同一 reduce,reduce 对这组记录进行操作,并产生新的数据集。所有 Reduce 任务的输出组成最终结果。形式化描述如下:
Map: (k1,v1) -> list(k2,v2)
Reduce:(k2,list(v2)) ->list(v3)
MapReduce 对任务的处理流程如图 1 所示。主要分为几步:
- 用户提交 MapReduce 程序至主控节点,主控节点将输入文件划分成若干分片(split)。主控节点 Master 和工作节点 worker 启动相应进程;
- 主控节点根据工作节点实际情况,进行 map 任务的分配;
- 被分配到 map 任务的节点读取文件的一个分片,按行进行 map 处理,将结果存在本地。结果分成 R 个分片进行存储,R 对应的是 Reduce 数目;
- Map 节点将存储文件的信息传递给 Master 主控节点,Master 指定 Reduce 任务运行节点,并告知数据获取节点信息;
- Reduce 节点根据 Master 传递的信息去 map 节点远程读取数据。因为 reduce 函数按分组进行处理,key 相同的记录被一同处理,在 reduce 节点正式处理前,对所有的记录按照 key 排序;
- Reduce 将处理结果写入到分布式文件系统中。
图 1 . MapReduce 处理流程图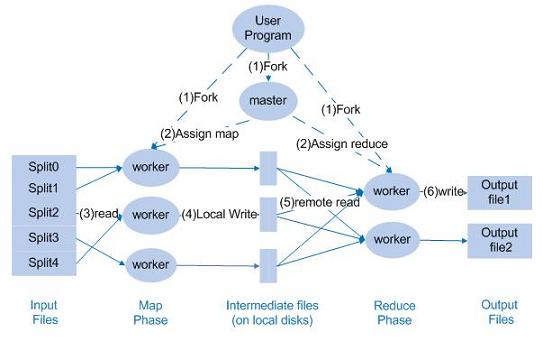 ?
?
MapReduce 适用情况
由于 MapReduce 编程模型是对输入按行顺次处理,它更适用于对批量数据进行处理。由于良好的可扩展性,MapReduce 尤其适用于对大规模数据的处理。
但是,对搜索等只是需要从大量数据中选取某几条特别的操作,MapReduce 相对于具有完善索引的系统而言,不再具有优势。因为它需要对每条数据进行匹配,并与搜索条件相匹配的数据提取出来。而如果采用索引系统,并不需要遍历所有的数据。
另外,由于每次操作需要遍历所有数据,MapReduce 并不适用于需要实时响应的系统。相反地,对于搜索引擎的预处理工作比如网页爬虫、数据清洗,以及日志分析等实时性要求不高的后台处理工作,MapReduce 编程模型是足以胜任的。
?回页首
日志分析应用
互联网或者大型应用系统中,日志的产生和记录是非常重要的事情。日志分析则是进行数据挖掘进而推进下一步工作的基础。比如,在购物网站,针对用户访问网页的信息,可以挖掘出用户的兴趣点,进而进行物品推荐;又比如,在应用系统中,通过分析用户对系统部件的使用情况,可以挖掘出该系统中的热点部件,进而采取相应的措施加强管理;典型地,对于一个医疗卫生系统,根据医生对不同病情开处方的日志记录,可以挖掘出某种病情和药品的对应关系,进而建立一个专家推荐系统等。
随着互联网行业的壮大和应用系统规模的扩充,记录相应信息的日志数量级也在急剧扩充。传统的单机版分析程序已经不能满足日志分析的需求,为此,大规模数据处理平台成为日志分析的理想平台。另一方面,日志分析并没有很高的实时性要求,MapReduce 编程模型由于易用性强、处理数据规模大,成为日志分析的利器。
本文下面部分会以用户访问网页日志为例,阐述如何利用 MapReduce 来分析日志,进而挖掘出相应信息。
?回页首
用户访问网页行为建模
一般而言 , 用户每访问网页时 , 系统日志中会存储一条记录 : 用户 + url + 访问时间。用户访问的一系列网页记录即是推断用户兴趣点的基础,即:用户 + urlSet。
如何根据用户访问的系列 URL 信息来推测用户兴趣点?一般而言,由以下几个步骤构成:
- 单一网页信息挖掘。根据 URL 得到网页内容信息,并对网页内容进行处理,得到代表此网页的几个关键词,一般要借助机器学习算法或者专家经验来攫取较有价值的词。
- 用户访问关键词信息汇总。汇总用户访问的各个 URL 中的所有关键词信息,进而得到用户关注的关键词列表。每个关键词均有不同权重,视该词在 URL 中出现的次数而定。
- 关键词扩展及归约。对用户关注关键词列表进行一定的扩展或归约操作,得到更加具有普遍意义的词信息,以更好地表征用户的兴趣点。
图 2 .用户兴趣挖掘流程图 ?
?单一网页信息挖掘
从 URL 得到该网页中有价值的词信息,首先要对 URL 进行重新爬取,以得到其对应的网页内容。从网页中提取关键词,则需要一定的算法支持。在一篇网页中,不同词因为在不同位置或者以不同的格式出现,对应影响程度也不同。比如,在网页的标题或者网页内容每一自然段段首或者段尾的词可能更为重要;在网页中有特定格式,比如加粗或者字体较大或者标记颜色的词可能更为重要。
而给定一个词,如何标记其重要性或者对网页的价值?可以将每个词用向量的形式来进行描述,向量中每一维度 d 表示不同的衡量标准,比如 TF(在该网页中出现的次数)、DF(在所有网页中出现的次数)、是否在标题中出现、是否在段首 / 段尾出现、是否在句首 / 句尾出现、颜色有无区别其它词、词的词性是名词 / 动词 / 形容词 / 助词,等等。形如 w = (v1, v2, v3, v4, … ),每个维度 v 对词是网页关键词的决定程度不同,这个影响因子可以通过机器学习算法训练而得。即:由事先指定关键词的网页来进行训练,得到特征权重。
得到特征权重后,对于网页中的每个词,可以通过 w = sum(vi*fi) 的方式来得到其作为关键词的比例。从网页中选取能代表其内容的几个词,应对所有计算出权重的词按权重从大到小依次排序,选取前几名或者大于某个阈值的词即可。
解决思路如图 3 所示。
图 3 .网页关键词挖掘流程图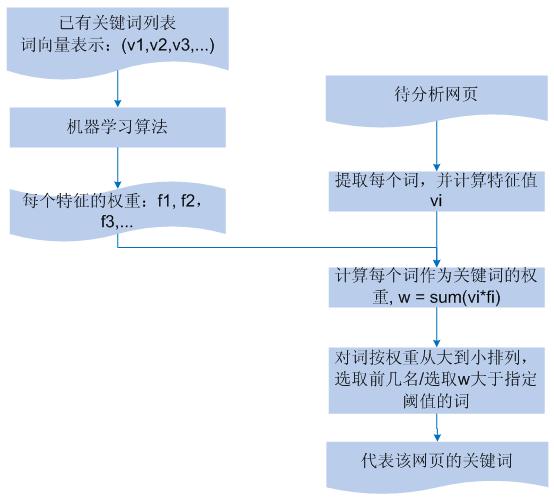 ?
?用户访问关键词汇总
得到每个网页的代表关键词后,对于用户访问的关键词,即可通过汇总用户访问的所有网页的关键词得到。简单而言,用户访问每个词的次数可以作为该词为用户关注词的权重。因为后面还要进行进一步的关键词扩展 / 归约,为防止数值过大的情况,可以对权重进行归一化。当然,也可以再加入其它策略,对词的权重进行进一步调整,比如通过黑名单或者词的共现频率等方式将垃圾词(对描述用户兴趣点无作用的词,比如“网易”、“淘宝”等)位置后调,此处不再详加展开。
关键词扩展及归约
- 关键词扩展
上一步得到的结果是用户在日志所记录的时间内访问的关键词汇总,而词与词之间往往是相互关联的。比如,用户访问了“篮球”这个词,那实际上该用户也很有可能对“球星”这个词感兴趣,因为“篮球”和“球星”两词存在一定关联。可以通过关键词扩展,推断出用户对“球星”一词也感兴趣。
如何得到两个词之间的相关度?一般而言,同时在一个网页元信息(meta)的 keyword 域里的词很大程度是相关的。因此,统计 meta 中词,就可以统计出来词与词的相关度信息。因为用户访问的词与词之间并不是孤立完全无关的,而是有一定关联的。把 meta 中词与词的相关性信息加入到用户对各个词的关注度中,可以更好地体现用户的关注方面。加入 meta 相关词信息后,便得到了更加精确的用户对词的关注度列表。
网页 meta 中 keyword 区域放置的往往是该网页的分类信息 ( 导航类网页 ),或者是该网页的关键词(正文类网页)。如果是前者,meta 中的词往往相关度较大。而不同网站的 meta 内容是什么,是由网站的编辑决定的。所以把不同网站的 meta 里面共现的词提取出来并汇总到一起,其实是汇聚了各个网站编辑们的集体智慧。这些词的共现信息应该能够很好地表现出词与词之间的相关性。如果两个词总在一起出现,它们极有可能是相关的。
具体流程为:首先,统计 meta 中共同出现的词对以及它们共同出现的次数;然后,统计这些共现的词对中的词每个词出现的次数;最后,应用公式进行共现频率的计算,得到的就是词与词之间的相关度。计算公式为
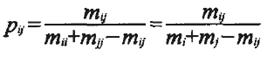 ?
?其中,pij表示词 i 和词 j 的相关度,mi、mj、mij分别表示词 i、词 j 以及词 i 和 j 共同在网页元信息(meta)的 keyword 中出现的次数。
图 4 .用户访问关键词扩展流程图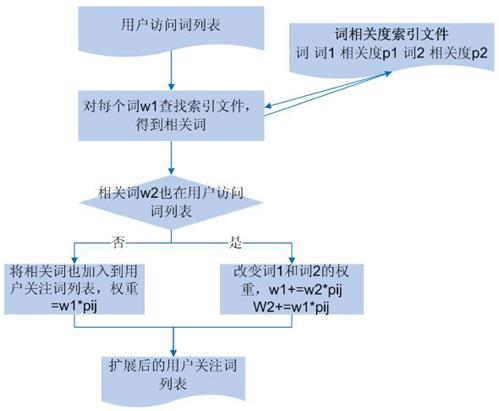 ?
?图 4 描述了将词之间的相关度加入用户访问关键词列表中的流程:首先得到所有词对之间的相关度信息,并以索引形式存储;然后,对之前得到的用户访问关键词列表中的每个词,查找索引得到相关的词,如果该词未被用户访问过,直接将其加入到用户访问列表中;否则,对两个词的权重都需进行调整。
- 关键词归约
与关键词扩展相对应的是关键词归约。用户访问的网页中挖掘出的关键词往往是具体的,比如用户关注的网页中提取出的词是“足球”、“篮球”,而这些词在划分的时候都属于体育类,通过关键词归约,可以推测出该用户对”体育”比较感兴趣。
而分类标准应该如何获得呢?在各大门户网站如新浪、网易的首页,都有诸如天气、新闻、教育、军事等各大类,在每一大类里又有各小类;在淘宝、易趣等网上交易平台,更是有对商品的多级详细分类。关键词归约,就是根据用户访问的关键词追溯到用户对哪些类别的内容感兴趣。
无论是关键词扩展还是归约,都会得到更加精确的用户访问关键词列表,对所有词按权重由大到小进行排列,描述的即是用户的兴趣点。
?回页首
MapReduce 对用户兴趣挖掘的实现
上一部分介绍了用户兴趣点挖掘的流程,本部分将针对各个模块进行 MapReduce 的实现。整个应用的输入是用户访问网页记录组成的文件,文件每行表示用户访问网页的一条记录,形为:
“用户 URL”。期望输出为用户的兴趣点文件,文件每行存储每个用户的兴趣点,形为:
“用户 词 1 权重 1 词 2 权重 2 词 3 权重 3 ”。
下面会对三个步骤分别讲解 MapReduce 实现。
单一网页信息挖掘
单一网页信息挖掘的目的是选取出网页中相对重要的关键词。策略为每个词赋予权重,并选取权重较大的词。词的权重获取公式 v = sum(vi*fi) 由两部分决定:该词在每个特征上的取值和该特征的权重。
每个特征的权重,可由训练得到,输入为给出关键词的系列网页。特征权重训练通常有特定的算法,比如 SCGIS 算法,因为训练集相对于整体的输入集较小,而算法通常也较复杂,并不适合并行化,可在 MapReduce 任务开始之前进行特征权重训练。
而词在每个特征维度上对应的取值,视特征的不同,难易程度也不同。比如词的出现位置、大小写、词性等,在对网页进行扫描时,可以立即获得。而 TF( 词在网页中出现的次数 )、DF(词在所有网页中出现的次数)等特征并不能随词出现时立即获取,但由于每个词处理的程序都相同,所以可以使用 MapReduce 编程模型并行化。下面进行具体讲述。
单一网页信息挖掘部分的 MapReduce 流程如图 5 所示。
图 5.MapReduce 实现单一网页信息挖掘 ?
?- TF 词在网页中出现次数信息统计
Map:输入为用户 +url 列表,对于单条记录,进行 url 爬虫和分词,得到用户访问的该网页中包含所有词的信息。每遇到一个词,Map 进行一次输出,key 为用户 + 网页 + 词,value 为 1。当然,此时 Map 还可以统计其它信息,比如词性(名词 / 动词)等,为简化描述,此处不再详加展开。
Reduce:Map 输出结果中 key 相同的汇聚到一起,Reduce 对每组统计其包含记录条数,将用户 + 网页 + 词仍然作为 key 进行输出,将每组中记录条数作为 value 进行输出。
这样,Reduce 的输出结果文件每行对应记录为“ 用户 + 网页 + 词 词的 TF”。
清单 1. MapReduce 统计 TF?
- 网页关键词计算
获得 DF 信息后,即可在一个新的 Map 过程中对网页中每个词计算其权重,即成为网页关键词的概率,此处可以指定一个阈值,若概率大于该阈值,认为该词可以代表网页,将其输出;否则忽略。
清单 5. Map 计算网页关键词用户访问关键词汇总
在用户关键词汇总模块,一共需要两个完整的 Reduce,流程图如图 6 所示。
图 6.MapReduce 实现用户关键词汇总 ?
?- 用户访问词次数汇总
经过单一网页信息挖掘模块的处理,对每个网页处理完毕,输出的记录形为“用户 + 网页关键词”,所以只需经过一个 Reduce 就能统计出用户访问每个词的次数。为方便后续对每个用户的关注词进行汇总处理,本 Reduce 的输出 key 为用户,value 为词 + 用户访问该词的次数。
- 用户访问词按次数排序
第二个 Reduce 的输入为第一个 Reduce 的输出,在本 Reduce 中,同一用户访问的词会被汇聚到一起,为了更好地描述用户的兴趣点,应对所有词按访问次数进行从大到小进行排序,可以通过 Reduce 内部对成熟排序算法,比如快速排序的调用来实现。
- 词权重归一化
因为不同词的访问次数可能差距较大,比如最常见词访问 20 次,而次常见词可能访问 10 次,如此大的差距并不利于对词权重的进一步调整。所以采用数据挖掘领域常见的归一化策略来对词权重进行调整,将其调整到 [0,1] 区间内。最简单的策略是将最常见词的访问次数去除访问每个词的次数。Weight(w)=Times(w)/Times(MAX)。这个权重归一化的过程同样可以在第二个 Reduce 过程中完成。
清单 6. 两个 Reduce 汇总用户访问关键词关键词扩展及归约
关键词扩展和归约对用户访问词列表进行的两个不同方向的调整,本节详细介绍一个方向,对关键词扩展进行展开。
- 词与词相关度信息获取
关键词扩展的关键是得到词与词的相关度,并基于此相关度对用户访问词列表进行调整。词与词之间相关度的计算公式已在前面小节列出。
?
图 7 .MapReduce 实现词与词相关度计算 ?
?图 7 展示了 MapReduce 计算 pij的流程。
- 统计词对共现次数
Map:以用户访问 url 信息为输入,在 Map 内部进行网页爬虫,并只爬取网页的 meta 中 keyword 域的词信息,每个网页中对应的词两两组成词对进行输出,词对中第一个词的拼音序 / 字母序要优于第二个词。输出 key 为词 1+ 词 2,value 为 1。
Reduce 统计词 i 和词 j 共同出现的次数 mij,在 Reduce 内部统计每组包含记录的数目,仍然以词 1+ 词 2 作为 key,将共现次数作为 value 进行输出。
清单 7. 词与词相关度计算 -1 (词对共现次数统计)?
- 第 1 个 map-reduce 合并单个词次数文件和词对次数文件。
Map 输入来自两个不同文件:单个词次数文件和词对共现次数文件。Map 内部对来自两个文件的记录进行不同操作,最后拼成相同格式进行输出。输出的 key 为单个词,value 形如 “第二个词 + 共现次数 \t 单个词次数”。没有的部分,以空字符补齐。这样,对于第一种情况,value 中以 \t 相隔的第一部分就是空字符;而对于第二种情况,value 中以 \t 相隔的第二部分为空字符。
Reduce 遍历迭代器中记录,对第一部分为空字符的,将 key 词对应次数提取出来,否则,记录对应的是与该词相关的其他词及共现次数信息,把这些信息放到一个数组。遍历完毕,对数组中每个元素,进行输出,输出 key 为词 1+ 词 2+ 共现次数 ( 字典序在前的词在前 ),value 为 Reduce 输入 key 词(词 1 或者词 2)的次数信息。
清单 10. 词与词相关度计算 -2 (拼成统一格式)?
获得词对相关度后,即可以对用户访问关键词列表进行扩展。如图 9 所示,只需一个 Map 即可完成操作。Map 以用户访问词列表为输入,key 为用户,value 为关键词列表。对于关键词列表中的每个词 A,都会查找词相关度索引文件,得到与词 A 相关的词列表 AL。遍历 AL,如果 AL中的词 B 也被用户访问过,那么要将用户访问词 B 的值× A 和 B 的相关度的结果加入到 A 的旧值上;如果 AL中的词 C 用户没有访问过,则要把词 C 加入到用户访问词列表中,并将词 A 的旧值× A 和 C 的相关度加入到词 C 值上。Map 的输出 key 仍为用户,value 为用户访问的词列表及对应的新的关注度值。
清单 13. Map 实现关键词扩展?
回页首
结束语
MapReduce 编程模型由于其强大的计算能力、良好的可扩展性和易用性,在工业界和学术界得到了广泛使用。对大规模数据批量处理的特点,使得 MapReduce 尤其适用于日志分析类应用。MapReduce 编程模型的基础是 Map 和 Reduce 函数,如何将应用全部或者部分转换到这两类计算模式,即将应用并行化,是有一定技巧的。本文对用户兴趣点挖掘应用进行 MapReduce 的实现,除在数据挖掘领域提出见解,MapReduce 的实现方式也为用户进行应用并行化提供了参考。
?
?
https://www.ibm.com/developerworks/cn/java/java-lo-mapreduce/
- 第 1 个 map-reduce 合并单个词次数文件和词对次数文件。
- 统计词对共现次数
- 词与词相关度信息获取
- 词权重归一化
- 用户访问词按次数排序
- 用户访问词次数汇总
- 网页关键词计算
- TF 词在网页中出现次数信息统计
- 关键词归约
- 关键词扩展
 ?
? ?
?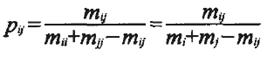 ?
? ?
? ?
? ?
? ?
?