Google Protocol Buffer 的使用和原理
![]()
![]()
![]()
![]() 平均分 (共 27 个评分 )
平均分 (共 27 个评分 )
?
Msg1 是一个 helloworld 类的对象,set_id() 用来设置 id 的值。SerializeToOstream 将对象序列化后写入一个 fstream 流。
代码清单 3 列出了 reader 的主要代码。
清单 3. Reader
?
同样,Reader 声明类 helloworld 的对象 msg1,然后利用 ParseFromIstream 从一个 fstream 流中读取信息并反序列化。此后,ListMsg 中采用 get 方法读取消息的内部信息,并进行打印输出操作。
Total Time 指一个对象操作的整个时间,包括创建对象,将对象序列化为内存中的字节序列,然后再反序列化的整个过程。从测试结果可以看到 Protobuf 的成绩很好,感兴趣的读者可以自行到网站 http://code.google.com/p/thrift-protobuf-compare/wiki/Benchmarking上了解更详细的测试结果。
Import 类对象中包含三个主要的对象,分别为处理错误的 MultiFileErrorCollector 类,定义 .proto 文件源目录的 SourceTree 类。
下面还是通过实例说明这些类的关系和使用吧。
对于给定的 proto 文件,比如 lm.helloworld.proto,在程序中动态编译它只需要很少的一些代码。如代码清单 6 所示。
清单 6. 代码
类 FileDescriptor 表示一个编译后的 .proto 文件;类 Descriptor 对应该文件中的一个 Message;类 FieldDescriptor 描述一个 Message 中的一个具体 Field。
比如编译完 lm.helloworld.proto 之后,可以通过如下代码得到 lm.helloworld.id 的定义:
清单 7. 得到 lm.helloworld.id 的定义的代码
在 main() 函数内,生成 CommandLineInterface 的对象 cli,调用其 RegisterGenerator() 方法将新语言的后端代码生成器 yourG 对象注册给 cli 对象。然后调用 cli 的 Run() 方法即可。
这样生成的编译器和 protoc 的使用方法相同,接受同样的命令行参数,cli 将对用户输入的 .proto 进行词法语法等分析工作,最终生成一个语法树。该树的结构如图所示。
图 5. 语法树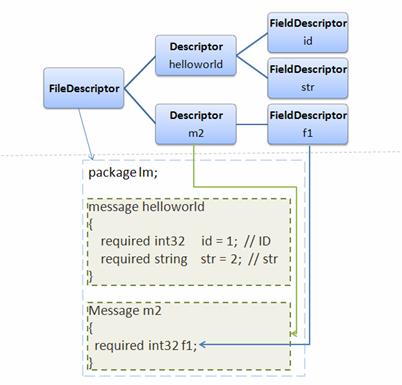
其根节点为一个 FileDescriptor 对象(请参考“动态编译”一节),并作为输入参数被传入 yourG 的 Generator() 方法。在这个方法内,您可以遍历语法树,然后生成对应的您所需要的代码。简单说来,要想实现一个新的 compiler,您只需要写一个 main 函数,和一个实现了方法 Generator() 的派生类即可。
在本文的下载附件中,有一个参考例子,将 .proto 文件编译生成 XML 的 compiler,可以作为参考。
消息经过序列化后会成为一个二进制数据流,该流中的数据为一系列的 Key-Value 对。如下图所示:
图 7. Message Buffer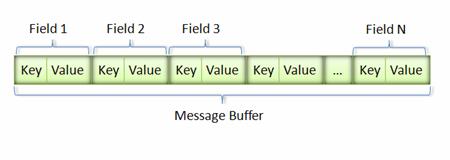
采用这种 Key-Pair 结构无需使用分隔符来分割不同的 Field。对于可选的 Field,如果消息中不存在该 field,那么在最终的 Message Buffer 中就没有该 field,这些特性都有助于节约消息本身的大小。
以代码清单 1 中的消息为例。假设我们生成如下的一个消息 Test1:
使用 zigzag 编码,绝对值小的数字,无论正负都可以采用较少的 byte 来表示,充分利用了 Varint 这种技术。
其他的数据类型,比如字符串等则采用类似数据库中的 varchar 的表示方法,即用一个 varint 表示长度,然后将其余部分紧跟在这个长度部分之后即可。
通过以上对 protobuf Encoding 方法的介绍,想必您也已经发现 protobuf 消息的内容小,适于网络传输。假如您对那些有关技术细节的描述缺乏耐心和兴趣,那么下面这个简单而直观的比较应该能给您更加深刻的印象。
对于代码清单 1 中的消息,用 Protobuf 序列化后的字节序列为:
整个解析过程需要 Protobuf 本身的框架代码和由 Protobuf 编译器生成的代码共同完成。Protobuf 提供了基类 Message 以及 Message_lite 作为通用的 Framework,,CodedInputStream 类,WireFormatLite 类等提供了对二进制数据的 decode 功能,从 5.1 节的分析来看,Protobuf 的解码可以通过几个简单的数学运算完成,无需复杂的词法语法分析,因此 ReadTag() 等方法都非常快。在这个调用路径上的其他类和方法都非常简单,感兴趣的读者可以自行阅读。相对于 XML 的解析过程,以上的流程图实在是非常简单吧?这也就是 Protobuf 效率高的第二个原因了。
回页首
结束语
往往了解越多,人们就会越觉得自己无知。我惶恐地发现自己竟然写了一篇关于序列化的文章,文中必然有许多想当然而自以为是的东西,还希望各位能够去伪存真,更希望真的高手能不吝赐教,给我来信。谢谢。
?
参考资料
学习
Google Protocol Buffer 的在线帮助 网页一些网友写的关于 Protobuf 的 Blog: hellobmw、 mailxxx。
在 developerWorks Linux 专区 寻找为 Linux 开发人员(包括 Linux 新手入门)准备的更多参考资料,查阅我们 最受欢迎的文章和教程。
在 developerWorks 上查阅所有 Linux 技巧 和 Linux 教程。
随时关注 developerWorks 技术活动和网络广播。
讨论
欢迎加入 My developerWorks 中文社区。关于作者
从事软件开发工作 10 年以上,爱好开源软件,目前从事数据库和数据仓库的开发工作。