SolrCloud相关资料
?Solr4.2?Solr4.3
)
整个升级主要参考SolrCloud这篇文档。
- 添加/get handler:
<requestHandler name="/get" />
solr.xml保持默认:
<cores adminPath="/admin/cores"
- DistributedUpdateProcessor会自动添加到update链里,但是你也可以手动添加:
<updateRequestProcessorChain name="sample"> <processor /> <processor /> </updateRequestProcessorChain>
- solr.DisMaxRequestHandler相关handler需要删除。
- solr.AnalysisRequestHandler相关handler需要删除。
设定了两个collection: test1和test2,他们的配置分别在$solr.solr.home/test1和$solr.solr.home/test2目录下。
2. 当第一次创建集群的时候,第一个节点启动后会等待其他节点启动,因为要组成一个shard集群,必须至少有numShards个节点启动。
3. 其他节点启动无需传入-Dbootstrap_conf=true和-DnumShards:
java $JVM_ARGS -DzkHost=$ZK_SERVERS -DzkClientTimeout=$ZK_TIMEOUT -Dsolr.solr.home=$BASE_DIR -jar $BASE_DIR/start.jar 2>&1 >>$BASE_DIR/logs/solr.log &
只需zookeeper相关参数就够了。
4. 更健壮的启动脚本应该将solr作为daemon service开机启动。
?
基本可以用上面这幅图来概述,这是一个拥有4个Solr节点的集群,索引分布在两个Shard里面,每个Shard包含两个Solr节点,一个是Leader节点,一个是Replica节点,此外集群中有一个负责维护集群状态信息的Overseer节点,它是一个总控制器。集群的所有状态信息都放在Zookeeper集群中统一维护。从图中还可以看到,任何一个节点都可以接收索引更新的请求,然后再将这个请求转发到文档所应该属于的那个Shard的Leader节点,Leader节点更新结束完成,最后将版本号和文档转发给同属于一个Shard的replicas节点。
下面我们来看一个简单的SolrCloud集群的配置过程。
首先去https://builds.apache.org/job/Solr-trunk/lastSuccessfulBuild/artifact/artifacts/下载Solr4.0的源码和二进制包,注意Solr4.0现在还在开发中,因此这里是Nightly Build版本。
示例1,简单的包含2个Shard的集群
这个示例中,我们把一个collection的索引数据分布到两个shard上去,步骤如下:
为了弄2个solr服务器,我们拷贝一份example目录
cd?example
java?-Dbootstrap_confdir=./solr/conf?-Dcollection.configName=myconf?-DzkRun?-DzkHost=localhost:9983,localhost:8574,localhost:9900?-DnumShards=2?-jar?start.jar
cd?example2
java?-Djetty.port=7574?-DzkRun?-DzkHost=localhost:9983,localhost:8574,localhost:9900?-jar?start.jar
cd?exampleB
java?-Djetty.port=8900?-DzkRun?-DzkHost=localhost:9983,localhost:8574,localhost:9900?-jar?start.jar
cd?example2B
java?-Djetty.port=7500?-DzkHost=localhost:9983,localhost:8574,localhost:9900?-jar?start.jar
????if?(zkRun?!=?null)?{
??????zkServer?=?new?SolrZkServer(zkRun,?zookeeperHost,?solrHome,?hostPort);
??????zkServer.parseConfig();
??????zkServer.start();
??????
??????//?set?client?from?server?config?if?not?already?set
??????if?(zookeeperHost?==?null)?{
????????zookeeperHost?=?zkServer.getClientString();
??????}
}
????if?(zkProps?==?null)?{
??????zkProps?=?new?SolrZkServerProps();
??????//?set?default?data?dir
??????//?TODO:?use?something?based?on?IP+port?????support?ensemble?all?from?same?solr?home?
??????zkProps.setDataDir(solrHome?+?'/'?+?"zoo_data");
??????zkProps.zkRun?=?zkRun;
??????zkProps.solrPort?=?solrPort;
}
tickTime=2000
dataDir=/var/zookeeper/
clientPort=2181
initLimit=5
syncLimit=2
server.1=zoo1:2888:3888
server.2=zoo2:2888:3888
server.3=zoo3:2888:3888
注意,server.x这些行就指明了zookeeper集群所包含的机器名称,每台Zookeeper服务器会使用3个端口来进行工作,其中第一个端口(端口1)用来做运行期间server间的通信,第二个端口(端口2)用来做leader election,另外还有一个端口(端口0)负责接收客户端请求。那么一台机器怎样确定自己是谁呢?这是通过dataDir目录下的myid文本文件确定。myid文件只包含一个数字,内容就是所在Server的ID:QuorumPeerConfig.myid。
1)?准备好集群所需要的配置信息后,就可以启动Zookeeper集群了。启动时是生成一个Zookeeper服务器线程,根据配置信息来决定是单机还是集群模式,如果是单机模式,则生成ZooKeeperServerMain对象并启动,如果是集群模式,则使用QuorumPeerMain对象启动。最后将服务器线程设置为Daemon模式,就完成了Zookeeper服务器的启动工作了。
????public?void?start()?{
????????zkThread?=?new?Thread()?{
????????????@Override
????????????public?void?run()?{
????????????????try?{
????????????????????if?(zkProps.getServers().size()?>?1)?{//zk集群
????????????????????????QuorumPeerMain?zkServer?=?new?QuorumPeerMain();
????????????????????????zkServer.runFromConfig(zkProps);
????????????????????????if?(logger.isInfoEnabled())?{
????????????????????????????logger.info("启动zk服务器集群成功");
????????????????????????}
????????????????????}?else?{//单机zk
????????????????????????ServerConfig?sc?=?new?ServerConfig();
????????????????????????sc.readFrom(zkProps);
????????????????????????ZooKeeperServerMain?zkServer?=?new?ZooKeeperServerMain();
????????????????????????zkServer.runFromConfig(sc);
????????????????????????if?(logger.isInfoEnabled())?{
????????????????????????????logger.info("启动单机zk服务器成功");
????????????????????????}
????????????????????}
????????????????????logger.info("ZooKeeper?Server?exited.");
????????????????}?catch?(Throwable?e)?{
????????????????????logger.error("ZooKeeper?Server?ERROR",?e);
????????????????????throw?new?SolrException(SolrException.ErrorCode.SERVER_ERROR,?e);????????????????????
????????????????}
????????????}
????????};
????????if?(zkProps.getServers().size()?>?1)?{
????????????logger.info("STARTING?EMBEDDED?ENSEMBLE?ZOOKEEPER?SERVER?at?port?"?+?zkProps.getClientPortAddress().getPort());
????????}?else?{
????????????logger.info("STARTING?EMBEDDED?STANDALONE?ZOOKEEPER?SERVER?at?port?"?+?zkProps.getClientPortAddress().getPort());????????????
????????}
????????
????????zkThread.setDaemon(true);
????????zkThread.start();
????????try?{
????????????Thread.sleep(500);?//?pause?for?ZooKeeper?to?start
????????}?catch?(Exception?e)?{
????????????logger.error("STARTING?ZOOKEEPER",?e);
????????}
????}为了验证集群是否启动成功,可以使用Zookeeper提供的命令行工具进行验证,进入bin目录下,运行:
??public?SolrZkClient(String?zkServerAddress,?int?zkClientTimeout,
??????ZkClientConnectionStrategy?strat,?final?OnReconnect?onReconnect,?int?clientConnectTimeout)?throws?InterruptedException,
??????TimeoutException,?IOException?{
????connManager?=?new?ConnectionManager("ZooKeeperConnection?Watcher:"
????????+?zkServerAddress,?this,?zkServerAddress,?zkClientTimeout,?strat,?onReconnect);
????strat.connect(zkServerAddress,?zkClientTimeout,?connManager,
????????new?ZkUpdate()?{
??????????@Override
??????????public?void?update(SolrZooKeeper?zooKeeper)?{
????????????SolrZooKeeper?oldKeeper?=?keeper;
????????????keeper?=?zooKeeper;
????????????if?(oldKeeper?!=?null)?{
??????????????try?{
????????????????oldKeeper.close();
??????????????}?catch?(InterruptedException?e)?{
????????????????//?Restore?the?interrupted?status
????????????????Thread.currentThread().interrupt();
????????????????log.error("",?e);
????????????????throw?new?ZooKeeperException(SolrException.ErrorCode.SERVER_ERROR,
????????????????????"",?e);
??????????????}
????????????}
??????????}
????????});
????connManager.waitForConnected(clientConnectTimeout);
????numOpens.incrementAndGet();
??}值得注意的是,构造函数中生成的ZkUpdate匿名类对象,它的update方法会被调用,
在这个方法里,会首先将已有的老的SolrZooKeeperg关闭掉,然后放置上一个新的SolrZooKeeper。做好这些准备工作以后,就会去连接Zookeeper服务器集群,
connManager.waitForConnected(clientConnectTimeout);//连接zk服务器集群,默认30秒超时时间
其实具体的连接动作是new SolrZooKeeper(serverAddress, timeout, watcher)引发的,上面那句代码只是在等待指定时间,看是否已经连接上。
如果连接Zookeeper服务器集群成功,那么就可以进行Zookeeper的常规操作了:
1)?是否已经连接
??public?Stat?exists(final?String?path,?final?Watcher?watcher,?boolean?retryOnConnLoss)?throws?KeeperException,?InterruptedException?{
????if?(retryOnConnLoss)?{
??????return?zkCmdExecutor.retryOperation(new?ZkOperation()?{
????????@Override
????????public?Stat?execute()?throws?KeeperException,?InterruptedException?{
??????????return?keeper.exists(path,?watcher);
????????}
??????});
????}?else?{
??????return?keeper.exists(path,?watcher);
????}
??}3)?创建一个Znode节点
??public?String?create(final?String?path,?final?byte?data[],?final?List<ACL>?acl,?final?CreateMode?createMode,?boolean?retryOnConnLoss)?throws?KeeperException,?InterruptedException?{
????if?(retryOnConnLoss)?{
??????return?zkCmdExecutor.retryOperation(new?ZkOperation()?{
????????@Override
????????public?String?execute()?throws?KeeperException,?InterruptedException?{
??????????return?keeper.create(path,?data,?acl,?createMode);
????????}
??????});
????}?else?{
??????return?keeper.create(path,?data,?acl,?createMode);
????}
??}??public?List<String>?getChildren(final?String?path,?final?Watcher?watcher,?boolean?retryOnConnLoss)?throws?KeeperException,?InterruptedException?{
????if?(retryOnConnLoss)?{
??????return?zkCmdExecutor.retryOperation(new?ZkOperation()?{
????????@Override
????????public?List<String>?execute()?throws?KeeperException,?InterruptedException?{
??????????return?keeper.getChildren(path,?watcher);
????????}
??????});
????}?else?{
??????return?keeper.getChildren(path,?watcher);
????}
??}
5)?获取指定Znode上附加的数据
??public?byte[]?getData(final?String?path,?final?Watcher?watcher,?final?Stat?stat,?boolean?retryOnConnLoss)?throws?KeeperException,?InterruptedException?{
????if?(retryOnConnLoss)?{
??????return?zkCmdExecutor.retryOperation(new?ZkOperation()?{
????????@Override
????????public?byte[]?execute()?throws?KeeperException,?InterruptedException?{
??????????return?keeper.getData(path,?watcher,?stat);
????????}
??????});
????}?else?{
??????return?keeper.getData(path,?watcher,?stat);
????}
??}??public?Stat?setData(final?String?path,?final?byte?data[],?final?int?version,?boolean?retryOnConnLoss)?throws?KeeperException,?InterruptedException?{
????if?(retryOnConnLoss)?{
??????return?zkCmdExecutor.retryOperation(new?ZkOperation()?{
????????@Override
????????public?Stat?execute()?throws?KeeperException,?InterruptedException?{
??????????return?keeper.setData(path,?data,?version);
????????}
??????});
????}?else?{
??????return?keeper.setData(path,?data,?version);
????}
??}
7)?创建路径
??public?void?makePath(String?path,?byte[]?data,?CreateMode?createMode,?Watcher?watcher,?boolean?failOnExists,?boolean?retryOnConnLoss)?throws?KeeperException,?InterruptedException?{
????if?(log.isInfoEnabled())?{
??????log.info("makePath:?"?+?path);
????}
????boolean?retry?=?true;
????
????if?(path.startsWith("/"))?{
??????path?=?path.substring(1,?path.length());
????}
????String[]?paths?=?path.split("/");
????StringBuilder?sbPath?=?new?StringBuilder();
????for?(int?i?=?0;?i?<?paths.length;?i++)?{
??????byte[]?bytes?=?null;
??????String?pathPiece?=?paths[i];
??????sbPath.append("/"?+?pathPiece);
??????final?String?currentPath?=?sbPath.toString();
??????Object?exists?=?exists(currentPath,?watcher,?retryOnConnLoss);
??????if?(exists?==?null?||?((i?==?paths.length?-1)?&&?failOnExists))?{
????????CreateMode?mode?=?CreateMode.PERSISTENT;
????????if?(i?==?paths.length?-?1)?{
??????????mode?=?createMode;
??????????bytes?=?data;
??????????if?(!retryOnConnLoss)?retry?=?false;
????????}
????????try?{
??????????if?(retry)?{
????????????final?CreateMode?finalMode?=?mode;
????????????final?byte[]?finalBytes?=?bytes;
????????????zkCmdExecutor.retryOperation(new?ZkOperation()?{
??????????????@Override
??????????????public?Object?execute()?throws?KeeperException,?InterruptedException?{
????????????????keeper.create(currentPath,?finalBytes,?ZooDefs.Ids.OPEN_ACL_UNSAFE,?finalMode);
????????????????return?null;
??????????????}
????????????});
??????????}?else?{
????????????keeper.create(currentPath,?bytes,?ZooDefs.Ids.OPEN_ACL_UNSAFE,?mode);
??????????}
????????}?catch?(NodeExistsException?e)?{
??????????
??????????if?(!failOnExists)?{
????????????//?TODO:?version???for?now,?don't?worry?about?race
????????????setData(currentPath,?data,?-1,?retryOnConnLoss);
????????????//?set?new?watch
????????????exists(currentPath,?watcher,?retryOnConnLoss);
????????????return;
??????????}
??????????
??????????//?ignore?unless?it's?the?last?node?in?the?path
??????????if?(i?==?paths.length?-?1)?{
????????????throw?e;
??????????}
????????}
????????if(i?==?paths.length?-1)?{
??????????//?set?new?watch
??????????exists(currentPath,?watcher,?retryOnConnLoss);
????????}
??????}?else?if?(i?==?paths.length?-?1)?{
????????//?TODO:?version???for?now,?don't?worry?about?race
????????setData(currentPath,?data,?-1,?retryOnConnLoss);
????????//?set?new?watch
????????exists(currentPath,?watcher,?retryOnConnLoss);
??????}
????}
??}8)?删除指定Znode
??public?void?delete(final?String?path,?final?int?version,?boolean?retryOnConnLoss)?throws?InterruptedException,?KeeperException?{
????if?(retryOnConnLoss)?{
??????zkCmdExecutor.retryOperation(new?ZkOperation()?{
????????@Override
????????public?Stat?execute()?throws?KeeperException,?InterruptedException?{
??????????keeper.delete(path,?version);
??????????return?null;
????????}
??????});
????}?else?{
??????keeper.delete(path,?version);
????}
??}??public?synchronized?void?process(WatchedEvent?event)?{
????if?(log.isInfoEnabled())?{
??????log.info("Watcher?"?+?this?+?"?name:"?+?name?+?"?got?event?"?+?event?+?"?path:"?+?event.getPath()?+?"?type:"?+?event.getType());
????}
????state?=?event.getState();
????if?(state?==?KeeperState.SyncConnected)?{
??????connected?=?true;
??????clientConnected.countDown();
????}?else?if?(state?==?KeeperState.Expired)?{
??????connected?=?false;
??????log.info("Attempting?to?reconnect?to?recover?relationship?with?ZooKeeper...");
??????//尝试重新连接zk服务器
??????try?{
????????connectionStrategy.reconnect(zkServerAddress,?zkClientTimeout,?this,
????????????new?ZkClientConnectionStrategy.ZkUpdate()?{
??????????????@Override
??????????????public?void?update(SolrZooKeeper?keeper)?throws?InterruptedException,?TimeoutException,?IOException?{
????????????????synchronized?(connectionStrategy)?{
??????????????????waitForConnected(SolrZkClient.DEFAULT_CLIENT_CONNECT_TIMEOUT);
??????????????????client.updateKeeper(keeper);
??????????????????if?(onReconnect?!=?null)?{
????????????????????onReconnect.command();
??????????????????}
??????????????????synchronized?(ConnectionManager.this)?{
????????????????????ConnectionManager.this.connected?=?true;
??????????????????}
????????????????}
????????????????
??????????????}
????????????});
??????}?catch?(Exception?e)?{
????????SolrException.log(log,?"",?e);
??????}
??????log.info("Connected:"?+?connected);
????}?else?if?(state?==?KeeperState.Disconnected)?{
??????connected?=?false;
????}?else?{
??????connected?=?false;
????}
????notifyAll();
??}
?
?
作者:洞庭散人
出处:http://phinecos.cnblogs.com/
?????在上一篇中介绍了连接Zookeeper集群的方法,这一篇将围绕一个有趣的话题---来展开,这就是Replication(索引复制),关于Solr Replication的详细介绍,可以参考http://wiki.apache.org/solr/SolrReplication。
?????????在开始这个话题之前,先从我最近在应用中引入solr的master/slave架构时,遇到的一个让我困扰的实际问题。
应用场景简单描述如下:
1)首先master节点下载索引分片,然后创建配置文件,加入master节点的replication配置片段,再对索引分片进行合并(关于mergeIndex,可以参考http://wiki.apache.org/solr/MergingSolrIndexes),然后利用上述配置文件和索引数据去创建一个solr核。
2)slave节点创建配置文件,加入slave节点的replication配置片段,创建一个空的solr核,等待从master节点进行索引数据同步
出现的问题:slave节点没有从master节点同步到数据。
问题分析:
1)首先检查master节点,获取最新的可复制索引的版本号,
http://master_host:port/solr/replication?command=indexversion
发现返回的索引版本号是0,这说明mater节点根本没有触发replication动作,
2)为了确认上述判断,在slave节点上进一步查看replication的详细信息
http://slave_host:port/solr/replication?command=details
发现确实如此,尽管master节点的索引版本号和slave节点的索引版本号不一致,但索引却没有同步过来,再分别查看master节点和slave节点的日志,发现索引复制动作确实没有开始。
综上所述,确实是master节点没有触发索引复制动作,那究竟是为何呢?先将原因摆出来,后面会通过源码的分析来加以说明。
原因:solr合并索引时,不管你是通过mergeindexes的http命令,还是调用底层lucene的IndexWriter,记得最后一定要提交一个commit,否则,不仅索引不仅不会对查询可见,更是对于master/slave架构的solr集群来说,master节点的replication动作不会触发,因为indexversion没有感知到变化。
?????????好了,下面开始对Solr的Replication的分析。
???????? Solr容器在加载solr核的时候,会对已经注册的各个实现SolrCoreAware接口的Handler进行回调,调用其inform方法。
?????????对于ReplicationHandler来说,就是在这里对自己是属于master节点还是slave节点进行判断,若是slave节点,则创建一个SnapPuller对象,定时负责从master节点主动拉索引数据下来;若是master节点,则只设置相应的参数。
??public?void?inform(SolrCore?core)?{
????this.core?=?core;
????registerFileStreamResponseWriter();
????registerCloseHook();
????NamedList?slave?=?(NamedList)?initArgs.get("slave");
????boolean?enableSlave?=?isEnabled(?slave?);
????if?(enableSlave)?{
??????tempSnapPuller?=?snapPuller?=?new?SnapPuller(slave,?this,?core);
??????isSlave?=?true;
????}
????NamedList?master?=?(NamedList)?initArgs.get("master");
????boolean?enableMaster?=?isEnabled(?master?);
????
????if?(!enableSlave?&&?!enableMaster)?{
??????enableMaster?=?true;
??????master?=?new?NamedList<Object>();
????}
????
????if?(enableMaster)?{
??????includeConfFiles?=?(String)?master.get(CONF_FILES);
??????if?(includeConfFiles?!=?null?&&?includeConfFiles.trim().length()?>?0)?{
????????List<String>?files?=?Arrays.asList(includeConfFiles.split(","));
????????for?(String?file?:?files)?{
??????????if?(file.trim().length()?==?0)?continue;
??????????String[]?strs?=?file.split(":");
??????????//?if?there?is?an?alias?add?it?or?it?is?null
??????????confFileNameAlias.add(strs[0],?strs.length?>?1???strs[1]?:?null);
????????}
????????LOG.info("Replication?enabled?for?following?config?files:?"?+?includeConfFiles);
??????}
??????List?backup?=?master.getAll("backupAfter");
??????boolean?backupOnCommit?=?backup.contains("commit");
??????boolean?backupOnOptimize?=?!backupOnCommit?&&?backup.contains("optimize");
??????List?replicateAfter?=?master.getAll(REPLICATE_AFTER);
??????replicateOnCommit?=?replicateAfter.contains("commit");
??????replicateOnOptimize?=?!replicateOnCommit?&&?replicateAfter.contains("optimize");
??????if?(!replicateOnCommit?&&?!?replicateOnOptimize)?{
????????replicateOnCommit?=?true;
??????}
??????
??????//?if?we?only?want?to?replicate?on?optimize,?we?need?the?deletion?policy?to
??????//?save?the?last?optimized?commit?point.
??????if?(replicateOnOptimize)?{
????????IndexDeletionPolicyWrapper?wrapper?=?core.getDeletionPolicy();
????????IndexDeletionPolicy?policy?=?wrapper?==?null???null?:?wrapper.getWrappedDeletionPolicy();
????????if?(policy?instanceof?SolrDeletionPolicy)?{
??????????SolrDeletionPolicy?solrPolicy?=?(SolrDeletionPolicy)policy;
??????????if?(solrPolicy.getMaxOptimizedCommitsToKeep()?<?1)?{
????????????solrPolicy.setMaxOptimizedCommitsToKeep(1);
??????????}
????????}?else?{
??????????LOG.warn("Replication?can't?call?setMaxOptimizedCommitsToKeep?on?"?+?policy);
????????}
??????}
??????if?(replicateOnOptimize?||?backupOnOptimize)?{
????????core.getUpdateHandler().registerOptimizeCallback(getEventListener(backupOnOptimize,?replicateOnOptimize));
??????}
??????if?(replicateOnCommit?||?backupOnCommit)?{
????????replicateOnCommit?=?true;
????????core.getUpdateHandler().registerCommitCallback(getEventListener(backupOnCommit,?replicateOnCommit));
??????}
??????if?(replicateAfter.contains("startup"))?{
????????replicateOnStart?=?true;
????????RefCounted<SolrIndexSearcher>?s?=?core.getNewestSearcher(false);
????????try?{
??????????DirectoryReader?reader?=?s==null???null?:?s.get().getIndexReader();
??????????if?(reader!=null?&&?reader.getIndexCommit()?!=?null?&&?reader.getIndexCommit().getGeneration()?!=?1L)?{
????????????try?{
??????????????if(replicateOnOptimize){
????????????????Collection<IndexCommit>?commits?=?DirectoryReader.listCommits(reader.directory());
????????????????for?(IndexCommit?ic?:?commits)?{
??????????????????if(ic.getSegmentCount()?==?1){
????????????????????if(indexCommitPoint?==?null?||?indexCommitPoint.getGeneration()?<?ic.getGeneration())?indexCommitPoint?=?ic;
??????????????????}
????????????????}
??????????????}?else{
????????????????indexCommitPoint?=?reader.getIndexCommit();
??????????????}
????????????}?finally?{
??????????????//?We?don't?need?to?save?commit?points?for?replication,?the?SolrDeletionPolicy
??????????????//?always?saves?the?last?commit?point?(and?the?last?optimized?commit?point,?if?needed)
??????????????/***
??????????????if(indexCommitPoint?!=?null){
????????????????core.getDeletionPolicy().saveCommitPoint(indexCommitPoint.getGeneration());
??????????????}
??????????????***/
????????????}
??????????}
??????????//?reboot?the?writer?on?the?new?index
??????????core.getUpdateHandler().newIndexWriter();
????????}?catch?(IOException?e)?{
??????????LOG.warn("Unable?to?get?IndexCommit?on?startup",?e);
????????}?finally?{
??????????if?(s!=null)?s.decref();
????????}
??????}
??????String?reserve?=?(String)?master.get(RESERVE);
??????if?(reserve?!=?null?&&?!reserve.trim().equals(""))?{
????????reserveCommitDuration?=?SnapPuller.readInterval(reserve);
??????}
??????LOG.info("Commits?will?be?reserved?for??"?+?reserveCommitDuration);
??????isMaster?=?true;
????}}?
????? lock = lockFactory.makeLock(directoryName + ".lock");
????? if (lock.isLocked()) return;
????? snapShotDir = new File(snapDir, directoryName);
????? if (!snapShotDir.mkdir()) {
??????? LOG.warn("Unable to create snapshot directory: " + snapShotDir.getAbsolutePath());
??????? return;
????? }
????? Collection<String> files = indexCommit.getFileNames();
????? FileCopier fileCopier = new FileCopier(solrCore.getDeletionPolicy(), indexCommit);
????? fileCopier.copyFiles(files, snapShotDir);
?
????? details.add("fileCount", files.size());
????? details.add("status", "success");
??????details.add("snapshotCompletedAt", new Date().toString());
??? } catch (Exception e) {
????? SnapPuller.delTree(snapShotDir);
????? LOG.error("Exception while creating snapshot", e);
??????details.add("snapShootException", e.getMessage());
??? } finally {
??????replicationHandler.core.getDeletionPolicy().releaseCommitPoint(indexCommit.getVersion());??
????? replicationHandler.snapShootDetails = details;
????? if (lock != null) {
??????? try {
????????? lock.release();
??????? } catch (IOException e) {
????????? LOG.error("Unable to release snapshoot lock: " + directoryName + ".lock");
??????? }
????? }
??? }
??}
3)fetchindex。响应来自slave节点的取索引文件的请求,会启动一个线程来实现索引文件的获取。
????? String masterUrl = solrParams.get(MASTER_URL);
????? if (!isSlave && masterUrl == null) {
??????? rsp.add(STATUS,ERR_STATUS);
??????? rsp.add("message","No slave configured or no 'masterUrl' Specified");
??????? return;
????? }
????? final SolrParams paramsCopy = new ModifiableSolrParams(solrParams);
????? new Thread() {
??????? @Override
??????? public void run() {
????????? doFetch(paramsCopy);
??????? }
????? }.start();
????? rsp.add(STATUS, OK_STATUS);
具体的获取动作是通过SnapPuller对象来实现的,首先尝试获取pull对象锁,如果请求锁失败,则说明还有取索引数据动作未结束,如果请求锁成功,就调用SnapPuller对象的fetchLatestIndex方法来取最新的索引数据。
?void doFetch(SolrParams solrParams) {
??? String masterUrl = solrParams == null ? null : solrParams.get(MASTER_URL);
??? if (!snapPullLock.tryLock())
????? return;
??? try {
????? tempSnapPuller = snapPuller;
????? if (masterUrl != null) {
??????? NamedList<Object> nl = solrParams.toNamedList();
??????? nl.remove(SnapPuller.POLL_INTERVAL);
??????? tempSnapPuller = new SnapPuller(nl, this, core);
????? }
????? tempSnapPuller.fetchLatestIndex(core);
??? } catch (Exception e) {
????? LOG.error("SnapPull failed ", e);
??? } finally {
????? tempSnapPuller = snapPuller;
????? snapPullLock.unlock();
??? }
?}
最后真正的取索引数据过程,首先,若mastet节点的indexversion为0,则说明master节点根本没有提供可供复制的索引数据,若master节点和slave节点的indexversion相同,则说明slave节点目前与master节点索引数据状态保持一致,无需同步。若两者的indexversion不同,则开始索引复制过程,首先从master节点上下载指定索引版本号的索引文件列表,然后创建一个索引文件同步服务线程来完成同并工作。
这里需要区分的是,如果master节点的年代比slave节点要老,那就说明两者已经不相容,此时slave节点需要新建一个索引目录,再从master节点做一次全量索引复制。还需要注意的一点是,索引同步也是可以同步配置文件的,若配置文件发生变化,则需要对solr核进行一次reload操作。最对了,还有,和文章开头一样,?slave节点同步完数据后,别忘了做一次commit操作,以便刷新自己的索引提交点到最新的状态。最后,关闭并等待同步服务线程结束。此外,具体的取索引文件是通过FileFetcher对象来完成。
?boolean fetchLatestIndex(SolrCore core) throws IOException {
??? replicationStartTime = System.currentTimeMillis();
??? try {
????? //get the current 'replicateable' index version in the master
????? NamedList response = null;
????? try {
??????? response = getLatestVersion();
????? } catch (Exception e) {
??????? LOG.error("Master at: " + masterUrl + " is not available. Index fetch failed. Exception: " + e.getMessage());
??????? return false;
????? }
????? long latestVersion = (Long) response.get(CMD_INDEX_VERSION);
????? long latestGeneration = (Long) response.get(GENERATION);
????? if (latestVersion == 0L) {
??????? //there is nothing to be replicated
??????? return false;
????? }
????? IndexCommit commit;
????? RefCounted<SolrIndexSearcher> searcherRefCounted = null;
????? try {
??????? searcherRefCounted = core.getNewestSearcher(false);
??????? commit = searcherRefCounted.get().getReader().getIndexCommit();
????? } finally {
??????? if (searcherRefCounted != null)
????????? searcherRefCounted.decref();
????? }
????? if (commit.getVersion() == latestVersion && commit.getGeneration() == latestGeneration) {
??????? //master and slave are alsready in sync just return
??????? LOG.info("Slave in sync with master.");
??????? return false;
????? }
????? LOG.info("Master's version: " + latestVersion + ", generation: " + latestGeneration);
????? LOG.info("Slave's version: " + commit.getVersion() + ", generation: " + commit.getGeneration());
????? LOG.info("Starting replication process");
????? // get the list of files first
????? fetchFileList(latestVersion);
????? // this can happen if the commit point is deleted before we fetch the file list.
????? if(filesToDownload.isEmpty()) return false;
????? LOG.info("Number of files in latest index in master: " + filesToDownload.size());
?
????? // Create the sync service
????? fsyncService = Executors.newSingleThreadExecutor();
????? // use a synchronized list because the list is read by other threads (to show details)
????? filesDownloaded = Collections.synchronizedList(new ArrayList<Map<String, Object>>());
????? // if the generateion of master is older than that of the slave , it means they are not compatible to be copied
????? // then a new index direcory to be created and all the files need to be copied
????? boolean isFullCopyNeeded = commit.getGeneration() >= latestGeneration;
????? File tmpIndexDir = createTempindexDir(core);
????? if (isIndexStale())
??????? isFullCopyNeeded = true;
????? successfulInstall = false;
????? boolean deleteTmpIdxDir = true;
????? File indexDir = null ;
????? try {
??????? indexDir = new File(core.getIndexDir());
?? ?????downloadIndexFiles(isFullCopyNeeded, tmpIndexDir, latestVersion);
??????? LOG.info("Total time taken for download : " + ((System.currentTimeMillis() - replicationStartTime) / 1000) + " secs");
??????? Collection<Map<String, Object>> modifiedConfFiles = getModifiedConfFiles(confFilesToDownload);
??????? if (!modifiedConfFiles.isEmpty()) {
??????????downloadConfFiles(confFilesToDownload, latestVersion);
????????? if (isFullCopyNeeded) {
??????????? successfulInstall = modifyIndexProps(tmpIndexDir.getName());
??????????? deleteTmpIdxDir =?false;
????????? } else {
??????????? successfulInstall = copyIndexFiles(tmpIndexDir, indexDir);
????????? }
????????? if (successfulInstall) {
??????? ????LOG.info("Configuration files are modified, core will be reloaded");
????????????logReplicationTimeAndConfFiles(modifiedConfFiles, successfulInstall);//write to a file time of replication and conf files.
??????????? reloadCore();
????????? }
??????? } else {
????????? terminateAndWaitFsyncService();
????????? if (isFullCopyNeeded) {
??????????? successfulInstall = modifyIndexProps(tmpIndexDir.getName());
??????????? deleteTmpIdxDir =?false;
????????? } else {
??????????? successfulInstall = copyIndexFiles(tmpIndexDir, indexDir);
????????? }
????????? if (successfulInstall) {
????????????logReplicationTimeAndConfFiles(modifiedConfFiles, successfulInstall);
??????????? doCommit();
????????? }
??????? }
??????? replicationStartTime = 0;
??????? return successfulInstall;
????? } catch (ReplicationHandlerException e) {
??????? LOG.error("User aborted Replication");
????? } catch (SolrException e) {
??????? throw e;
????? } catch (Exception e) {
??????? throw new SolrException(SolrException.ErrorCode.SERVER_ERROR, "Index fetch failed : ", e);
????? } finally {
??????? if (deleteTmpIdxDir) delTree(tmpIndexDir);
??????? else delTree(indexDir);
????? }
????? return successfulInstall;
??? } finally {
????? if (!successfulInstall) {
??????? logReplicationTimeAndConfFiles(null, successfulInstall);
????? }
????? filesToDownload = filesDownloaded = confFilesDownloaded = confFilesToDownload = null;
????? replicationStartTime = 0;
????? fileFetcher = null;
????? if (fsyncService != null && !fsyncService.isShutdown()) fsyncService.shutdownNow();
????? fsyncService = null;
????? stop = false;
????? fsyncException = null;
??? }
?}?
作者:洞庭散人
出处:http://phinecos.cnblogs.com/
- 添加/get handler:
<requestHandler name="/get" />
solr.xml保持默认:
<cores adminPath="/admin/cores"
- DistributedUpdateProcessor会自动添加到update链里,但是你也可以手动添加:
<updateRequestProcessorChain name="sample"> <processor /> <processor /> </updateRequestProcessorChain>
- solr.DisMaxRequestHandler相关handler需要删除。
- solr.AnalysisRequestHandler相关handler需要删除。
设定了两个collection: test1和test2,他们的配置分别在$solr.solr.home/test1和$solr.solr.home/test2目录下。
2. 当第一次创建集群的时候,第一个节点启动后会等待其他节点启动,因为要组成一个shard集群,必须至少有numShards个节点启动。
3. 其他节点启动无需传入-Dbootstrap_conf=true和-DnumShards:
java $JVM_ARGS -DzkHost=$ZK_SERVERS -DzkClientTimeout=$ZK_TIMEOUT -Dsolr.solr.home=$BASE_DIR -jar $BASE_DIR/start.jar 2>&1 >>$BASE_DIR/logs/solr.log &
只需zookeeper相关参数就够了。
4. 更健壮的启动脚本应该将solr作为daemon service开机启动。
?
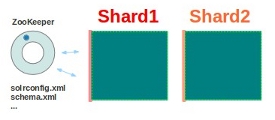
基本可以用上面这幅图来概述,这是一个拥有4个Solr节点的集群,索引分布在两个Shard里面,每个Shard包含两个Solr节点,一个是Leader节点,一个是Replica节点,此外集群中有一个负责维护集群状态信息的Overseer节点,它是一个总控制器。集群的所有状态信息都放在Zookeeper集群中统一维护。从图中还可以看到,任何一个节点都可以接收索引更新的请求,然后再将这个请求转发到文档所应该属于的那个Shard的Leader节点,Leader节点更新结束完成,最后将版本号和文档转发给同属于一个Shard的replicas节点。
下面我们来看一个简单的SolrCloud集群的配置过程。
首先去https://builds.apache.org/job/Solr-trunk/lastSuccessfulBuild/artifact/artifacts/下载Solr4.0的源码和二进制包,注意Solr4.0现在还在开发中,因此这里是Nightly Build版本。
示例1,简单的包含2个Shard的集群
这个示例中,我们把一个collection的索引数据分布到两个shard上去,步骤如下:
为了弄2个solr服务器,我们拷贝一份example目录
cd?example
java?-Dbootstrap_confdir=./solr/conf?-Dcollection.configName=myconf?-DzkRun?-DzkHost=localhost:9983,localhost:8574,localhost:9900?-DnumShards=2?-jar?start.jar
cd?example2
java?-Djetty.port=7574?-DzkRun?-DzkHost=localhost:9983,localhost:8574,localhost:9900?-jar?start.jar
cd?exampleB
java?-Djetty.port=8900?-DzkRun?-DzkHost=localhost:9983,localhost:8574,localhost:9900?-jar?start.jar
cd?example2B
java?-Djetty.port=7500?-DzkHost=localhost:9983,localhost:8574,localhost:9900?-jar?start.jar????if?(zkRun?!=?null)?{
??????zkServer?=?new?SolrZkServer(zkRun,?zookeeperHost,?solrHome,?hostPort);
??????zkServer.parseConfig();
??????zkServer.start();
??????
??????//?set?client?from?server?config?if?not?already?set
??????if?(zookeeperHost?==?null)?{
????????zookeeperHost?=?zkServer.getClientString();
??????}
}????if?(zkProps?==?null)?{
??????zkProps?=?new?SolrZkServerProps();
??????//?set?default?data?dir
??????//?TODO:?use?something?based?on?IP+port?????support?ensemble?all?from?same?solr?home?
??????zkProps.setDataDir(solrHome?+?'/'?+?"zoo_data");
??????zkProps.zkRun?=?zkRun;
??????zkProps.solrPort?=?solrPort;
}tickTime=2000
dataDir=/var/zookeeper/
clientPort=2181
initLimit=5
syncLimit=2
server.1=zoo1:2888:3888
server.2=zoo2:2888:3888
server.3=zoo3:2888:3888注意,server.x这些行就指明了zookeeper集群所包含的机器名称,每台Zookeeper服务器会使用3个端口来进行工作,其中第一个端口(端口1)用来做运行期间server间的通信,第二个端口(端口2)用来做leader election,另外还有一个端口(端口0)负责接收客户端请求。那么一台机器怎样确定自己是谁呢?这是通过dataDir目录下的myid文本文件确定。myid文件只包含一个数字,内容就是所在Server的ID:QuorumPeerConfig.myid。
1)?准备好集群所需要的配置信息后,就可以启动Zookeeper集群了。启动时是生成一个Zookeeper服务器线程,根据配置信息来决定是单机还是集群模式,如果是单机模式,则生成ZooKeeperServerMain对象并启动,如果是集群模式,则使用QuorumPeerMain对象启动。最后将服务器线程设置为Daemon模式,就完成了Zookeeper服务器的启动工作了。
????public?void?start()?{
????????zkThread?=?new?Thread()?{
????????????@Override
????????????public?void?run()?{
????????????????try?{
????????????????????if?(zkProps.getServers().size()?>?1)?{//zk集群
????????????????????????QuorumPeerMain?zkServer?=?new?QuorumPeerMain();
????????????????????????zkServer.runFromConfig(zkProps);
????????????????????????if?(logger.isInfoEnabled())?{
????????????????????????????logger.info("启动zk服务器集群成功");
????????????????????????}
????????????????????}?else?{//单机zk
????????????????????????ServerConfig?sc?=?new?ServerConfig();
????????????????????????sc.readFrom(zkProps);
????????????????????????ZooKeeperServerMain?zkServer?=?new?ZooKeeperServerMain();
????????????????????????zkServer.runFromConfig(sc);
????????????????????????if?(logger.isInfoEnabled())?{
????????????????????????????logger.info("启动单机zk服务器成功");
????????????????????????}
????????????????????}
????????????????????logger.info("ZooKeeper?Server?exited.");
????????????????}?catch?(Throwable?e)?{
????????????????????logger.error("ZooKeeper?Server?ERROR",?e);
????????????????????throw?new?SolrException(SolrException.ErrorCode.SERVER_ERROR,?e);????????????????????
????????????????}
????????????}
????????};
????????if?(zkProps.getServers().size()?>?1)?{
????????????logger.info("STARTING?EMBEDDED?ENSEMBLE?ZOOKEEPER?SERVER?at?port?"?+?zkProps.getClientPortAddress().getPort());
????????}?else?{
????????????logger.info("STARTING?EMBEDDED?STANDALONE?ZOOKEEPER?SERVER?at?port?"?+?zkProps.getClientPortAddress().getPort());????????????
????????}
????????
????????zkThread.setDaemon(true);
????????zkThread.start();
????????try?{
????????????Thread.sleep(500);?//?pause?for?ZooKeeper?to?start
????????}?catch?(Exception?e)?{
????????????logger.error("STARTING?ZOOKEEPER",?e);
????????}
????}为了验证集群是否启动成功,可以使用Zookeeper提供的命令行工具进行验证,进入bin目录下,运行:
??public?SolrZkClient(String?zkServerAddress,?int?zkClientTimeout,
??????ZkClientConnectionStrategy?strat,?final?OnReconnect?onReconnect,?int?clientConnectTimeout)?throws?InterruptedException,
??????TimeoutException,?IOException?{
????connManager?=?new?ConnectionManager("ZooKeeperConnection?Watcher:"
????????+?zkServerAddress,?this,?zkServerAddress,?zkClientTimeout,?strat,?onReconnect);
????strat.connect(zkServerAddress,?zkClientTimeout,?connManager,
????????new?ZkUpdate()?{
??????????@Override
??????????public?void?update(SolrZooKeeper?zooKeeper)?{
????????????SolrZooKeeper?oldKeeper?=?keeper;
????????????keeper?=?zooKeeper;
????????????if?(oldKeeper?!=?null)?{
??????????????try?{
????????????????oldKeeper.close();
??????????????}?catch?(InterruptedException?e)?{
????????????????//?Restore?the?interrupted?status
????????????????Thread.currentThread().interrupt();
????????????????log.error("",?e);
????????????????throw?new?ZooKeeperException(SolrException.ErrorCode.SERVER_ERROR,
????????????????????"",?e);
??????????????}
????????????}
??????????}
????????});
????connManager.waitForConnected(clientConnectTimeout);
????numOpens.incrementAndGet();
??}值得注意的是,构造函数中生成的ZkUpdate匿名类对象,它的update方法会被调用,
在这个方法里,会首先将已有的老的SolrZooKeeperg关闭掉,然后放置上一个新的SolrZooKeeper。做好这些准备工作以后,就会去连接Zookeeper服务器集群,
connManager.waitForConnected(clientConnectTimeout);//连接zk服务器集群,默认30秒超时时间
其实具体的连接动作是new SolrZooKeeper(serverAddress, timeout, watcher)引发的,上面那句代码只是在等待指定时间,看是否已经连接上。
如果连接Zookeeper服务器集群成功,那么就可以进行Zookeeper的常规操作了:
1)?是否已经连接
??public?Stat?exists(final?String?path,?final?Watcher?watcher,?boolean?retryOnConnLoss)?throws?KeeperException,?InterruptedException?{
????if?(retryOnConnLoss)?{
??????return?zkCmdExecutor.retryOperation(new?ZkOperation()?{
????????@Override
????????public?Stat?execute()?throws?KeeperException,?InterruptedException?{
??????????return?keeper.exists(path,?watcher);
????????}
??????});
????}?else?{
??????return?keeper.exists(path,?watcher);
????}
??}3)?创建一个Znode节点
??public?String?create(final?String?path,?final?byte?data[],?final?List<ACL>?acl,?final?CreateMode?createMode,?boolean?retryOnConnLoss)?throws?KeeperException,?InterruptedException?{
????if?(retryOnConnLoss)?{
??????return?zkCmdExecutor.retryOperation(new?ZkOperation()?{
????????@Override
????????public?String?execute()?throws?KeeperException,?InterruptedException?{
??????????return?keeper.create(path,?data,?acl,?createMode);
????????}
??????});
????}?else?{
??????return?keeper.create(path,?data,?acl,?createMode);
????}
??}??public?List<String>?getChildren(final?String?path,?final?Watcher?watcher,?boolean?retryOnConnLoss)?throws?KeeperException,?InterruptedException?{
????if?(retryOnConnLoss)?{
??????return?zkCmdExecutor.retryOperation(new?ZkOperation()?{
????????@Override
????????public?List<String>?execute()?throws?KeeperException,?InterruptedException?{
??????????return?keeper.getChildren(path,?watcher);
????????}
??????});
????}?else?{
??????return?keeper.getChildren(path,?watcher);
????}
??}5)?获取指定Znode上附加的数据
??public?byte[]?getData(final?String?path,?final?Watcher?watcher,?final?Stat?stat,?boolean?retryOnConnLoss)?throws?KeeperException,?InterruptedException?{
????if?(retryOnConnLoss)?{
??????return?zkCmdExecutor.retryOperation(new?ZkOperation()?{
????????@Override
????????public?byte[]?execute()?throws?KeeperException,?InterruptedException?{
??????????return?keeper.getData(path,?watcher,?stat);
????????}
??????});
????}?else?{
??????return?keeper.getData(path,?watcher,?stat);
????}
??}??public?Stat?setData(final?String?path,?final?byte?data[],?final?int?version,?boolean?retryOnConnLoss)?throws?KeeperException,?InterruptedException?{
????if?(retryOnConnLoss)?{
??????return?zkCmdExecutor.retryOperation(new?ZkOperation()?{
????????@Override
????????public?Stat?execute()?throws?KeeperException,?InterruptedException?{
??????????return?keeper.setData(path,?data,?version);
????????}
??????});
????}?else?{
??????return?keeper.setData(path,?data,?version);
????}
??}7)?创建路径
??public?void?makePath(String?path,?byte[]?data,?CreateMode?createMode,?Watcher?watcher,?boolean?failOnExists,?boolean?retryOnConnLoss)?throws?KeeperException,?InterruptedException?{
????if?(log.isInfoEnabled())?{
??????log.info("makePath:?"?+?path);
????}
????boolean?retry?=?true;
????
????if?(path.startsWith("/"))?{
??????path?=?path.substring(1,?path.length());
????}
????String[]?paths?=?path.split("/");
????StringBuilder?sbPath?=?new?StringBuilder();
????for?(int?i?=?0;?i?<?paths.length;?i++)?{
??????byte[]?bytes?=?null;
??????String?pathPiece?=?paths[i];
??????sbPath.append("/"?+?pathPiece);
??????final?String?currentPath?=?sbPath.toString();
??????Object?exists?=?exists(currentPath,?watcher,?retryOnConnLoss);
??????if?(exists?==?null?||?((i?==?paths.length?-1)?&&?failOnExists))?{
????????CreateMode?mode?=?CreateMode.PERSISTENT;
????????if?(i?==?paths.length?-?1)?{
??????????mode?=?createMode;
??????????bytes?=?data;
??????????if?(!retryOnConnLoss)?retry?=?false;
????????}
????????try?{
??????????if?(retry)?{
????????????final?CreateMode?finalMode?=?mode;
????????????final?byte[]?finalBytes?=?bytes;
????????????zkCmdExecutor.retryOperation(new?ZkOperation()?{
??????????????@Override
??????????????public?Object?execute()?throws?KeeperException,?InterruptedException?{
????????????????keeper.create(currentPath,?finalBytes,?ZooDefs.Ids.OPEN_ACL_UNSAFE,?finalMode);
????????????????return?null;
??????????????}
????????????});
??????????}?else?{
????????????keeper.create(currentPath,?bytes,?ZooDefs.Ids.OPEN_ACL_UNSAFE,?mode);
??????????}
????????}?catch?(NodeExistsException?e)?{
??????????
??????????if?(!failOnExists)?{
????????????//?TODO:?version???for?now,?don't?worry?about?race
????????????setData(currentPath,?data,?-1,?retryOnConnLoss);
????????????//?set?new?watch
????????????exists(currentPath,?watcher,?retryOnConnLoss);
????????????return;
??????????}
??????????
??????????//?ignore?unless?it's?the?last?node?in?the?path
??????????if?(i?==?paths.length?-?1)?{
????????????throw?e;
??????????}
????????}
????????if(i?==?paths.length?-1)?{
??????????//?set?new?watch
??????????exists(currentPath,?watcher,?retryOnConnLoss);
????????}
??????}?else?if?(i?==?paths.length?-?1)?{
????????//?TODO:?version???for?now,?don't?worry?about?race
????????setData(currentPath,?data,?-1,?retryOnConnLoss);
????????//?set?new?watch
????????exists(currentPath,?watcher,?retryOnConnLoss);
??????}
????}
??}8)?删除指定Znode
??public?void?delete(final?String?path,?final?int?version,?boolean?retryOnConnLoss)?throws?InterruptedException,?KeeperException?{
????if?(retryOnConnLoss)?{
??????zkCmdExecutor.retryOperation(new?ZkOperation()?{
????????@Override
????????public?Stat?execute()?throws?KeeperException,?InterruptedException?{
??????????keeper.delete(path,?version);
??????????return?null;
????????}
??????});
????}?else?{
??????keeper.delete(path,?version);
????}
??}??public?synchronized?void?process(WatchedEvent?event)?{
????if?(log.isInfoEnabled())?{
??????log.info("Watcher?"?+?this?+?"?name:"?+?name?+?"?got?event?"?+?event?+?"?path:"?+?event.getPath()?+?"?type:"?+?event.getType());
????}
????state?=?event.getState();
????if?(state?==?KeeperState.SyncConnected)?{
??????connected?=?true;
??????clientConnected.countDown();
????}?else?if?(state?==?KeeperState.Expired)?{
??????connected?=?false;
??????log.info("Attempting?to?reconnect?to?recover?relationship?with?ZooKeeper...");
??????//尝试重新连接zk服务器
??????try?{
????????connectionStrategy.reconnect(zkServerAddress,?zkClientTimeout,?this,
????????????new?ZkClientConnectionStrategy.ZkUpdate()?{
??????????????@Override
??????????????public?void?update(SolrZooKeeper?keeper)?throws?InterruptedException,?TimeoutException,?IOException?{
????????????????synchronized?(connectionStrategy)?{
??????????????????waitForConnected(SolrZkClient.DEFAULT_CLIENT_CONNECT_TIMEOUT);
??????????????????client.updateKeeper(keeper);
??????????????????if?(onReconnect?!=?null)?{
????????????????????onReconnect.command();
??????????????????}
??????????????????synchronized?(ConnectionManager.this)?{
????????????????????ConnectionManager.this.connected?=?true;
??????????????????}
????????????????}
????????????????
??????????????}
????????????});
??????}?catch?(Exception?e)?{
????????SolrException.log(log,?"",?e);
??????}
??????log.info("Connected:"?+?connected);
????}?else?if?(state?==?KeeperState.Disconnected)?{
??????connected?=?false;
????}?else?{
??????connected?=?false;
????}
????notifyAll();
??}?
?
作者:洞庭散人
出处:http://phinecos.cnblogs.com/
?????在上一篇中介绍了连接Zookeeper集群的方法,这一篇将围绕一个有趣的话题---来展开,这就是Replication(索引复制),关于Solr Replication的详细介绍,可以参考http://wiki.apache.org/solr/SolrReplication。
?????????在开始这个话题之前,先从我最近在应用中引入solr的master/slave架构时,遇到的一个让我困扰的实际问题。
应用场景简单描述如下:
1)首先master节点下载索引分片,然后创建配置文件,加入master节点的replication配置片段,再对索引分片进行合并(关于mergeIndex,可以参考http://wiki.apache.org/solr/MergingSolrIndexes),然后利用上述配置文件和索引数据去创建一个solr核。
2)slave节点创建配置文件,加入slave节点的replication配置片段,创建一个空的solr核,等待从master节点进行索引数据同步
出现的问题:slave节点没有从master节点同步到数据。
问题分析:
1)首先检查master节点,获取最新的可复制索引的版本号,
http://master_host:port/solr/replication?command=indexversion
发现返回的索引版本号是0,这说明mater节点根本没有触发replication动作,
2)为了确认上述判断,在slave节点上进一步查看replication的详细信息
http://slave_host:port/solr/replication?command=details
发现确实如此,尽管master节点的索引版本号和slave节点的索引版本号不一致,但索引却没有同步过来,再分别查看master节点和slave节点的日志,发现索引复制动作确实没有开始。
综上所述,确实是master节点没有触发索引复制动作,那究竟是为何呢?先将原因摆出来,后面会通过源码的分析来加以说明。
原因:solr合并索引时,不管你是通过mergeindexes的http命令,还是调用底层lucene的IndexWriter,记得最后一定要提交一个commit,否则,不仅索引不仅不会对查询可见,更是对于master/slave架构的solr集群来说,master节点的replication动作不会触发,因为indexversion没有感知到变化。
?????????好了,下面开始对Solr的Replication的分析。
???????? Solr容器在加载solr核的时候,会对已经注册的各个实现SolrCoreAware接口的Handler进行回调,调用其inform方法。
?????????对于ReplicationHandler来说,就是在这里对自己是属于master节点还是slave节点进行判断,若是slave节点,则创建一个SnapPuller对象,定时负责从master节点主动拉索引数据下来;若是master节点,则只设置相应的参数。
??public?void?inform(SolrCore?core)?{
????this.core?=?core;
????registerFileStreamResponseWriter();
????registerCloseHook();
????NamedList?slave?=?(NamedList)?initArgs.get("slave");
????boolean?enableSlave?=?isEnabled(?slave?);
????if?(enableSlave)?{
??????tempSnapPuller?=?snapPuller?=?new?SnapPuller(slave,?this,?core);
??????isSlave?=?true;
????}
????NamedList?master?=?(NamedList)?initArgs.get("master");
????boolean?enableMaster?=?isEnabled(?master?);
????
????if?(!enableSlave?&&?!enableMaster)?{
??????enableMaster?=?true;
??????master?=?new?NamedList<Object>();
????}
????
????if?(enableMaster)?{
??????includeConfFiles?=?(String)?master.get(CONF_FILES);
??????if?(includeConfFiles?!=?null?&&?includeConfFiles.trim().length()?>?0)?{
????????List<String>?files?=?Arrays.asList(includeConfFiles.split(","));
????????for?(String?file?:?files)?{
??????????if?(file.trim().length()?==?0)?continue;
??????????String[]?strs?=?file.split(":");
??????????//?if?there?is?an?alias?add?it?or?it?is?null
??????????confFileNameAlias.add(strs[0],?strs.length?>?1???strs[1]?:?null);
????????}
????????LOG.info("Replication?enabled?for?following?config?files:?"?+?includeConfFiles);
??????}
??????List?backup?=?master.getAll("backupAfter");
??????boolean?backupOnCommit?=?backup.contains("commit");
??????boolean?backupOnOptimize?=?!backupOnCommit?&&?backup.contains("optimize");
??????List?replicateAfter?=?master.getAll(REPLICATE_AFTER);
??????replicateOnCommit?=?replicateAfter.contains("commit");
??????replicateOnOptimize?=?!replicateOnCommit?&&?replicateAfter.contains("optimize");
??????if?(!replicateOnCommit?&&?!?replicateOnOptimize)?{
????????replicateOnCommit?=?true;
??????}
??????
??????//?if?we?only?want?to?replicate?on?optimize,?we?need?the?deletion?policy?to
??????//?save?the?last?optimized?commit?point.
??????if?(replicateOnOptimize)?{
????????IndexDeletionPolicyWrapper?wrapper?=?core.getDeletionPolicy();
????????IndexDeletionPolicy?policy?=?wrapper?==?null???null?:?wrapper.getWrappedDeletionPolicy();
????????if?(policy?instanceof?SolrDeletionPolicy)?{
??????????SolrDeletionPolicy?solrPolicy?=?(SolrDeletionPolicy)policy;
??????????if?(solrPolicy.getMaxOptimizedCommitsToKeep()?<?1)?{
????????????solrPolicy.setMaxOptimizedCommitsToKeep(1);
??????????}
????????}?else?{
??????????LOG.warn("Replication?can't?call?setMaxOptimizedCommitsToKeep?on?"?+?policy);
????????}
??????}
??????if?(replicateOnOptimize?||?backupOnOptimize)?{
????????core.getUpdateHandler().registerOptimizeCallback(getEventListener(backupOnOptimize,?replicateOnOptimize));
??????}
??????if?(replicateOnCommit?||?backupOnCommit)?{
????????replicateOnCommit?=?true;
????????core.getUpdateHandler().registerCommitCallback(getEventListener(backupOnCommit,?replicateOnCommit));
??????}
??????if?(replicateAfter.contains("startup"))?{
????????replicateOnStart?=?true;
????????RefCounted<SolrIndexSearcher>?s?=?core.getNewestSearcher(false);
????????try?{
??????????DirectoryReader?reader?=?s==null???null?:?s.get().getIndexReader();
??????????if?(reader!=null?&&?reader.getIndexCommit()?!=?null?&&?reader.getIndexCommit().getGeneration()?!=?1L)?{
????????????try?{
??????????????if(replicateOnOptimize){
????????????????Collection<IndexCommit>?commits?=?DirectoryReader.listCommits(reader.directory());
????????????????for?(IndexCommit?ic?:?commits)?{
??????????????????if(ic.getSegmentCount()?==?1){
????????????????????if(indexCommitPoint?==?null?||?indexCommitPoint.getGeneration()?<?ic.getGeneration())?indexCommitPoint?=?ic;
??????????????????}
????????????????}
??????????????}?else{
????????????????indexCommitPoint?=?reader.getIndexCommit();
??????????????}
????????????}?finally?{
??????????????//?We?don't?need?to?save?commit?points?for?replication,?the?SolrDeletionPolicy
??????????????//?always?saves?the?last?commit?point?(and?the?last?optimized?commit?point,?if?needed)
??????????????/***
??????????????if(indexCommitPoint?!=?null){
????????????????core.getDeletionPolicy().saveCommitPoint(indexCommitPoint.getGeneration());
??????????????}
??????????????***/
????????????}
??????????}
??????????//?reboot?the?writer?on?the?new?index
??????????core.getUpdateHandler().newIndexWriter();
????????}?catch?(IOException?e)?{
??????????LOG.warn("Unable?to?get?IndexCommit?on?startup",?e);
????????}?finally?{
??????????if?(s!=null)?s.decref();
????????}
??????}
??????String?reserve?=?(String)?master.get(RESERVE);
??????if?(reserve?!=?null?&&?!reserve.trim().equals(""))?{
????????reserveCommitDuration?=?SnapPuller.readInterval(reserve);
??????}
??????LOG.info("Commits?will?be?reserved?for??"?+?reserveCommitDuration);
??????isMaster?=?true;
????}}?
????? lock = lockFactory.makeLock(directoryName + ".lock");
????? if (lock.isLocked()) return;
????? snapShotDir = new File(snapDir, directoryName);
????? if (!snapShotDir.mkdir()) {
??????? LOG.warn("Unable to create snapshot directory: " + snapShotDir.getAbsolutePath());
??????? return;
????? }
????? Collection<String> files = indexCommit.getFileNames();
????? FileCopier fileCopier = new FileCopier(solrCore.getDeletionPolicy(), indexCommit);
????? fileCopier.copyFiles(files, snapShotDir);
?
????? details.add("fileCount", files.size());
????? details.add("status", "success");
??????details.add("snapshotCompletedAt", new Date().toString());
??? } catch (Exception e) {
????? SnapPuller.delTree(snapShotDir);
????? LOG.error("Exception while creating snapshot", e);
??????details.add("snapShootException", e.getMessage());
??? } finally {
??????replicationHandler.core.getDeletionPolicy().releaseCommitPoint(indexCommit.getVersion());??
????? replicationHandler.snapShootDetails = details;
????? if (lock != null) {
??????? try {
????????? lock.release();
??????? } catch (IOException e) {
????????? LOG.error("Unable to release snapshoot lock: " + directoryName + ".lock");
??????? }
????? }
??? }
??}
3)fetchindex。响应来自slave节点的取索引文件的请求,会启动一个线程来实现索引文件的获取。
????? String masterUrl = solrParams.get(MASTER_URL);
????? if (!isSlave && masterUrl == null) {
??????? rsp.add(STATUS,ERR_STATUS);
??????? rsp.add("message","No slave configured or no 'masterUrl' Specified");
??????? return;
????? }
????? final SolrParams paramsCopy = new ModifiableSolrParams(solrParams);
????? new Thread() {
??????? @Override
??????? public void run() {
????????? doFetch(paramsCopy);
??????? }
????? }.start();
????? rsp.add(STATUS, OK_STATUS);
具体的获取动作是通过SnapPuller对象来实现的,首先尝试获取pull对象锁,如果请求锁失败,则说明还有取索引数据动作未结束,如果请求锁成功,就调用SnapPuller对象的fetchLatestIndex方法来取最新的索引数据。
?void doFetch(SolrParams solrParams) {
??? String masterUrl = solrParams == null ? null : solrParams.get(MASTER_URL);
??? if (!snapPullLock.tryLock())
????? return;
??? try {
????? tempSnapPuller = snapPuller;
????? if (masterUrl != null) {
??????? NamedList<Object> nl = solrParams.toNamedList();
??????? nl.remove(SnapPuller.POLL_INTERVAL);
??????? tempSnapPuller = new SnapPuller(nl, this, core);
????? }
????? tempSnapPuller.fetchLatestIndex(core);
??? } catch (Exception e) {
????? LOG.error("SnapPull failed ", e);
??? } finally {
????? tempSnapPuller = snapPuller;
????? snapPullLock.unlock();
??? }
?}
最后真正的取索引数据过程,首先,若mastet节点的indexversion为0,则说明master节点根本没有提供可供复制的索引数据,若master节点和slave节点的indexversion相同,则说明slave节点目前与master节点索引数据状态保持一致,无需同步。若两者的indexversion不同,则开始索引复制过程,首先从master节点上下载指定索引版本号的索引文件列表,然后创建一个索引文件同步服务线程来完成同并工作。
这里需要区分的是,如果master节点的年代比slave节点要老,那就说明两者已经不相容,此时slave节点需要新建一个索引目录,再从master节点做一次全量索引复制。还需要注意的一点是,索引同步也是可以同步配置文件的,若配置文件发生变化,则需要对solr核进行一次reload操作。最对了,还有,和文章开头一样,?slave节点同步完数据后,别忘了做一次commit操作,以便刷新自己的索引提交点到最新的状态。最后,关闭并等待同步服务线程结束。此外,具体的取索引文件是通过FileFetcher对象来完成。
?boolean fetchLatestIndex(SolrCore core) throws IOException {
??? replicationStartTime = System.currentTimeMillis();
??? try {
????? //get the current 'replicateable' index version in the master
????? NamedList response = null;
????? try {
??????? response = getLatestVersion();
????? } catch (Exception e) {
??????? LOG.error("Master at: " + masterUrl + " is not available. Index fetch failed. Exception: " + e.getMessage());
??????? return false;
????? }
????? long latestVersion = (Long) response.get(CMD_INDEX_VERSION);
????? long latestGeneration = (Long) response.get(GENERATION);
????? if (latestVersion == 0L) {
??????? //there is nothing to be replicated
??????? return false;
????? }
????? IndexCommit commit;
????? RefCounted<SolrIndexSearcher> searcherRefCounted = null;
????? try {
??????? searcherRefCounted = core.getNewestSearcher(false);
??????? commit = searcherRefCounted.get().getReader().getIndexCommit();
????? } finally {
??????? if (searcherRefCounted != null)
????????? searcherRefCounted.decref();
????? }
????? if (commit.getVersion() == latestVersion && commit.getGeneration() == latestGeneration) {
??????? //master and slave are alsready in sync just return
??????? LOG.info("Slave in sync with master.");
??????? return false;
????? }
????? LOG.info("Master's version: " + latestVersion + ", generation: " + latestGeneration);
????? LOG.info("Slave's version: " + commit.getVersion() + ", generation: " + commit.getGeneration());
????? LOG.info("Starting replication process");
????? // get the list of files first
????? fetchFileList(latestVersion);
????? // this can happen if the commit point is deleted before we fetch the file list.
????? if(filesToDownload.isEmpty()) return false;
????? LOG.info("Number of files in latest index in master: " + filesToDownload.size());
?
????? // Create the sync service
????? fsyncService = Executors.newSingleThreadExecutor();
????? // use a synchronized list because the list is read by other threads (to show details)
????? filesDownloaded = Collections.synchronizedList(new ArrayList<Map<String, Object>>());
????? // if the generateion of master is older than that of the slave , it means they are not compatible to be copied
????? // then a new index direcory to be created and all the files need to be copied
????? boolean isFullCopyNeeded = commit.getGeneration() >= latestGeneration;
????? File tmpIndexDir = createTempindexDir(core);
????? if (isIndexStale())
??????? isFullCopyNeeded = true;
????? successfulInstall = false;
????? boolean deleteTmpIdxDir = true;
????? File indexDir = null ;
????? try {
??????? indexDir = new File(core.getIndexDir());
?? ?????downloadIndexFiles(isFullCopyNeeded, tmpIndexDir, latestVersion);
??????? LOG.info("Total time taken for download : " + ((System.currentTimeMillis() - replicationStartTime) / 1000) + " secs");
??????? Collection<Map<String, Object>> modifiedConfFiles = getModifiedConfFiles(confFilesToDownload);
??????? if (!modifiedConfFiles.isEmpty()) {
??????????downloadConfFiles(confFilesToDownload, latestVersion);
????????? if (isFullCopyNeeded) {
??????????? successfulInstall = modifyIndexProps(tmpIndexDir.getName());
??????????? deleteTmpIdxDir =?false;
????????? } else {
??????????? successfulInstall = copyIndexFiles(tmpIndexDir, indexDir);
????????? }
????????? if (successfulInstall) {
??????? ????LOG.info("Configuration files are modified, core will be reloaded");
????????????logReplicationTimeAndConfFiles(modifiedConfFiles, successfulInstall);//write to a file time of replication and conf files.
??????????? reloadCore();
????????? }
??????? } else {
????????? terminateAndWaitFsyncService();
????????? if (isFullCopyNeeded) {
??????????? successfulInstall = modifyIndexProps(tmpIndexDir.getName());
??????????? deleteTmpIdxDir =?false;
????????? } else {
??????????? successfulInstall = copyIndexFiles(tmpIndexDir, indexDir);
????????? }
????????? if (successfulInstall) {
????????????logReplicationTimeAndConfFiles(modifiedConfFiles, successfulInstall);
??????????? doCommit();
????????? }
??????? }
??????? replicationStartTime = 0;
??????? return successfulInstall;
????? } catch (ReplicationHandlerException e) {
??????? LOG.error("User aborted Replication");
????? } catch (SolrException e) {
??????? throw e;
????? } catch (Exception e) {
??????? throw new SolrException(SolrException.ErrorCode.SERVER_ERROR, "Index fetch failed : ", e);
????? } finally {
??????? if (deleteTmpIdxDir) delTree(tmpIndexDir);
??????? else delTree(indexDir);
????? }
????? return successfulInstall;
??? } finally {
????? if (!successfulInstall) {
??????? logReplicationTimeAndConfFiles(null, successfulInstall);
????? }
????? filesToDownload = filesDownloaded = confFilesDownloaded = confFilesToDownload = null;
????? replicationStartTime = 0;
????? fileFetcher = null;
????? if (fsyncService != null && !fsyncService.isShutdown()) fsyncService.shutdownNow();
????? fsyncService = null;
????? stop = false;
????? fsyncException = null;
??? }
?}?
作者:洞庭散人
出处:http://phinecos.cnblogs.com/
- DistributedUpdateProcessor会自动添加到update链里,但是你也可以手动添加:
