如何判断中文字节的前后字节?
一段由中文和英文(或数字)组成的GBK字节文件,从中间截取时,怎么判断一个字节是中文的一半,又怎么判断是中文的前一个字节还是后一个字节?
GBK 亦采用双字节表示,总体编码范围为 8140-FEFE,首字节在 81-FE 之间,尾字节在 40-FE 之间,剔除 xx7F 一条线。
如何判断是中文的一半,我已经会解决了,请求判断出中文的前后字节。
运行结果如下: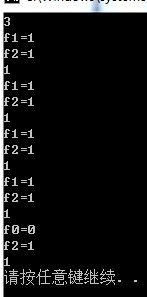
这说明_ismbblead(gbk[i])和_ismbbtrail(gbk[i])对于中文的前后字节的判断是一样的。
那么对于“一段由中文和英文(或数字)组成的GBK字节文件,从中间截取时,怎么判断一个字节是中文的一半,又怎么判断是中文的前一个字节还是后一个字节?”这个问题还是无法解决。所以……嘿嘿,还得请你帮帮忙。
谢谢!!
我从中间截取的话,会先跳过所有_ismbblead(gbk[i])或_ismbbtrail(gbk[i])的字节,直到遇到换行符或半角字符,然后再开始截取。
//GBK汉字内码范围(不包括A1xx~A9xx的标点符号英文字母特殊符号等)
//区码 ,位码
//81-A0 ,40-7E 80-FE
//AA-AF ,40-7E 80-A0
//B0-D6 ,40-7E 80-FE
//D7 ,40-7E 80-F9
//D8-F7 ,40-7E 80-FE
//F8-FE ,40-7E 80-A0
[解决办法]
我从中间截取的话,会先跳过所有_ismbblead(gbk[i])或_ismbbtrail(gbk[i])的字节,直到遇到换行符或半角字符,然后再开始截取。
这就是终极解决方案。
你信不信?反正我信了!
[解决办法]
我打算从中间某个位置截取的话,会先从要截取的位置开始,往后跳过所有_ismbblead(gbk[i])或_ismbbtrail(gbk[i])的字节,直到遇到换行符或非_ismbbtrail(gbk[i])的半角字符,然后实际从此位置截取。
这就是终极解决方案。
你信不信?反正我信了!
[解决办法]
#include <stdio.h>
#include <string.h>
#include <mbstring.h>
#include <mbctype.h>
#include <locale.h>
void split_hz(char *hz,int len,char **s,char **e) {
int i;
*s=hz;
if (len>(int)strlen(hz)) {
*e=hz+strlen(hz);
return;
}
for (i=len;hz[i];i++) {
if (!_ismbblead(hz[i]) && !_ismbbtrail(hz[i])) {
*e=hz+i;
return;
}
}
}
int main() {
char gbk[]="a汉b字c中华人民共和国\n汉b字c中华人民共和国\n汉字c中华d人民共和国\n";
size_t g;
char *s,*e;
setlocale(LC_ALL,"chs");
g=strlen(gbk)/2;
e=gbk;
split_hz(e,g,&s,&e);printf("1:[%.*s]\n",e-s,s);
split_hz(e,g,&s,&e);printf("2:[%.*s]\n",e-s,s);
printf("--------------------\n");
g=strlen(gbk)/4;
e=gbk;
split_hz(e,g,&s,&e);printf("1:[%.*s]\n",e-s,s);
split_hz(e,g,&s,&e);printf("2:[%.*s]\n",e-s,s);
split_hz(e,g,&s,&e);printf("3:[%.*s]\n",e-s,s);
split_hz(e,g,&s,&e);printf("4:[%.*s]\n",e-s,s);
return 0;
}
//1:[a汉b字c中华人民共和国
//汉b字c中华人民共和国]
//2:[
//汉字c中华d人民共和国
//]
//--------------------
//1:[a汉b字c中华人民共和国]
//2:[
//汉b字c中华人民共和国]
//3:[
//汉字c中华d人民共和国]
//4:[
//]
//