决策树--从原理到实现
================================================================================
算算有相当一段时间没写blog了,主要是这学期作业比较多,而且我也没怎么学新的东西
接下来打算实现一个小的toy lib:DML,同时也回顾一下以前学到的东西
当然我只能保证代码的真确性,不能保证其效率啊~~~~~~
之后我会陆续添加进去很多代码,可以供大家学习的时候看,实际使用还是用其它的吧
================================================================================
一.引入决策树基本上是每一本机器学习入门书籍必讲的东西,其决策过程和平时我们的思维很相似,所以非常好理解,同时有一堆信息论的东西在里面,也算是一个入门应用,决策树也有回归和分类,但一般来说我们主要讲的是分类,方便理解嘛。
虽然说这是一个很简单的算法,但其实现其实还是有些烦人,因为其feature既有离散的,也有连续的,实现的时候要稍加注意
(不同特征的决策,图片来自【1】)
O-信息论的一些point: 首先看这里:http://blog.csdn.net/dark_scope/article/details/8459576 然后加入一个叫信息增益的东西: □.信息增益:(information gain) g(D,A) = H(D)-H(D|A) 表示了特征A使得数据集D的分类不确定性减少的程度 □.信息增益比:(information gain ratio) g‘(D,A)=g(D,A) / H(D) □.基尼指数:

 二.各种算法1.ID3
二.各种算法1.ID3ID3算法就是对各个feature信息计算信息增益,然后选择信息增益最大的feature作为决策点将数据分成两部分
然后再对这两部分分别生成决策树。
 图自【1】
图自【1】
2.C4.5
C4.5与ID3相比其实就是用信息增益比代替信息增益,应为信息增益有一个缺点:
信息增益选择属性时偏向选择取值多的属性
算法的整体过程其实与ID3差异不大:图自【2】

CART(classification and regression tree)的算法整体过程和上面的差异不大,然是CART的决策是二叉树的
每一个决策只能是“是”和“否”,换句话说,即使一个feature有多个可能取值,也只选择其中一个而把数据分类
两部分而不是多个,这里我们主要讲一下分类树,它用到的是基尼指数:
 图自【2】
图自【2】
好吧,其实我就想贴贴代码而已……本代码在https://github.com/justdark/dml/tree/master/dml/DT
纯属toy~~~~~实现的CART算法:
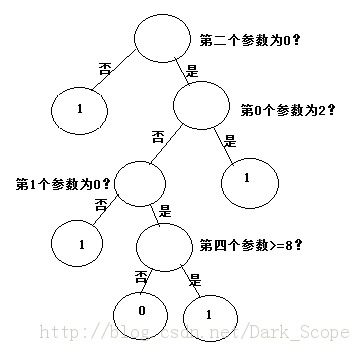
展示出来大概是这样:注意第四个参数是连续变量
四.reference 【1】:《机器学习》 -mitchell,卡耐基梅龙大学 【2】:《统计学习方法》-李航