What is the difference between L1 and L2 regularization?
今天讨论班一个师姐讲到L1 norm还有L2 norm 的regularization问题,还有晚上和一个同学也讨论到这个问题,具体什么时候用L1,什么时候用L2,论文上写道一般当成分中有几个成分是principle factor的时候我们会使用L1 norm penalty,但是为什么L1会有这个效果。
一个网上的讨论:
http://www.quora.com/Machine-Learning/What-is-the-difference-between-L1-and-L2-regularization
发现这个网站不错,经常讨论一些机器学习相关的问题。
There are many ways to understand the need for and approaches to regularization. I won't attempt to summarize the ideas here, but you should explore statistics or machine learning literature to get a high-level view. In particular, you can view regularization as a prior on the distribution from which your data is drawn (most famously Gaussian for least-squares), as a way to punish high values in regression coefficients, and so on. I prefer a more naive but somewhat more understandable (for me!) viewpoint.
Let's say you wish to solve the linear problem ![]() . Here,
. Here, ![]() is a matrix and
is a matrix and ![]() is a vector. We spend lots of time in linear algebra worrying about the exactly-and over-determined cases, in which
is a vector. We spend lots of time in linear algebra worrying about the exactly-and over-determined cases, in which ![]() is at least as tall as it is wide, but instead let's assume the system is under-determined, e.g.
is at least as tall as it is wide, but instead let's assume the system is under-determined, e.g. ![]() is wider than it is tall, in which case there generally exist infinitely many solutions to the problem at hand.
is wider than it is tall, in which case there generally exist infinitely many solutions to the problem at hand.
This case is troublesome, because there are multiple possible ![]() 's you might want to recover. To choose one, we can solve the following optimization problem:
's you might want to recover. To choose one, we can solve the following optimization problem:
MINIMIZEWITH RESPECT TO
This is called the least-norm solution. In many ways, it says "In the absence of any other information, I might as well make
But there's one thing I've neglected in the notation above: The norm
In particular, consider the vectors
 and
and 
 and
and ^2+(0)^2}=1") So, the two vectors are equivalent with respect to the L1 norm but different with respect to the L2 norm. This is because squaring a number punishes large values more than it punishes small values.
So, the two vectors are equivalent with respect to the L1 norm but different with respect to the L2 norm. This is because squaring a number punishes large values more than it punishes small values.
Thus, solving the minimization problem above with (so-called "Tikhonov regularization") really wants small values in all slots of
(so-called "Tikhonov regularization") really wants small values in all slots of  , whereas solving the L1 version doesn't care if it puts all the large values into a single slot of .
, whereas solving the L1 version doesn't care if it puts all the large values into a single slot of .
Practically speaking, we can see L2 regularization spreads error throughout the vector, whereas L1 is happy (in many cases) with a sparse , meaning that some values in are exactly zero while others may be relatively large. The former case is sufficient and indeed suitable for a variety of statistical problems, but the latter is gaining traction through the field of compressive sensing. From a non-rigorous standpoint, compressive sensing assumes not that observations come from Gaussian-distributed sources about ground truth but rather that sparse or simple solutions to equations are preferable or more likely (the "Occam's Razor" approach).Practically, I think the biggest reasons for regularization are 1) to avoid overfitting by not generating high coefficients for predictors that are sparse. 2) to stabilize the estimates especially when there's collinearity in the data.
1) is inherent in the regularization framework. Since there are two forces pulling each other in the objective function, if there's no meaningful loss reduction, the increased penalty from the regularization term wouldn't improve the overall objective function. This is a great property since a lot of noise would be automatically filtered out from the model.
To give you an example for 2), if you have two predictors that have same values, if you just run a regression algorithm on it since the data matrix is singular, your beta coefficients will be Inf if you try to do a straight matrix inversion. But if you add a very small regularization lambda to it, you will get stable beta coefficients with the coefficient values evenly divided between the equivalent two variables.
For the difference between L1 and L2, the following graph demonstrates why people bother to have L1 since L2 has such an elegant analytical solution and is so computationally straightforward. Regularized regression can also be represented as a constrained regression problem (since they are Lagrangian equivalent). In Graph (a), the black square represents the feasible region of of the L1 regularization while graph (b) represents the feasible region for L2 regularization. The contours in the plots represent different loss values (for the unconstrained regression model ). The feasible point that minimizes the loss is more likely to happen on the coordinates on graph (a) than on graph (b) since graph (a) is more angular. This effect amplifies when your number of coefficients increases, i.e. from 2 to 200.
The implication of this is that the L1 regularization gives you sparse estimates. Namely, in a high dimensional space, you got mostly zeros and a small number of non-zero coefficients. This is huge since it incorporates variable selection to the modeling problem. In addition, if you have to score a large sample with your model, you can have a lot of computational savings since you don't have to compute features(predictors) whose coefficient is 0. I personally think L1 regularization is one of the most beautiful things in machine learning and convex optimization. It is indeed widely used in bioinformatics and large scale machine learning for companies like Facebook, Yahoo, Google and Microsoft.When you have lots of parameters but not enough data points, regression can overfit. For example, you might find that logistic regression proposing a model fully confident that all patients on one side of the hyperplane will die with 100% probability and the ones on the other side will live with 100% probability.
Now, we all know that this is unlikely. In fact, it's pretty rare that you'd ever have an effect even as strong as smoking. Such egregiously confident predictions are associated with high values of regression coefficients. Thus, regularization is about incorporating what we know about regression and data on top of what's actually in the available data: often as simple as indicating that high coefficient values need a lot of data to be acceptable.
The Bayesian regularization paradigm assumes what a typical regression problem should be like - and then mathematically fuses the prior expectations with what's fit from the data: understanding that there are a number of models that could all explain the observed data. Other paradigms involve ad-hoc algorithms or estimators that are computationally efficient, sometimes have bounds on their performance, but it's less of a priority to seek a simple unifying theory of what's actually going on. Bayesians are happy to employ efficient ad-hoc algorithms understanding that they are approximations to the general theory.
Two popular regularization methods are L1 and L2. If you're familiar with Bayesian statistics: L1 usually corresponds to setting a Laplacean prior on the regression coefficients - and picking a maximum a posteriori hypothesis. L2 similarly corresponds to Gaussian prior. As one moves away from zero, the probability for such a coefficient grows progressively smaller.As you can see, L1/Laplace tends to tolerate both large values as well as very small values of coefficients more than L2/Gaussian (tails).
Regularization works by adding the penalty associated with the coefficient values to the error of the hypothesis. This way, an accurate hypothesis with unlikely coefficients would be penalized whila a somewhat less accurate but more conservative hypothesis with low coefficients would not be penalized as much.
For more information and evaluations, see http://www.stat.columbia.edu/~ge... - I personally prefer Cauchy priors, which correspond to log(1+L2) penalty/regularization terms. Justin Solomon has a great answer on the difference between L1 and L2 norms and the implications for regularization.
?1 vs ?2 for signal estimation:
Here is what a signal that is sparse or approximately sparse i.e. that belongs to the ell-1 ball looks like. It becomes extremely unlikely that an ?2 penalty can recover a sparse signal since very few solutions of such a cost function are truly sparse. ?1penalties on the other hand are great for recovering truly sparse signals, as they are computationally tractable but still capable of recovering the exact sparse solution.?2 penalization is preferable for data that is not at all sparse, i.e. where you do not expect regression coefficients to show a decaying property. In such cases, incorrectly using an ?1 penalty for non-sparse data will give you give you a large estimation error.
Figure: ?p ball. As the value of p decreases, the size of the corresponding ?p space also decreases. This can be seen visually when comparing the the size of the spaces of signals, in three dimensions, for which the ?p norm is less than or equal to one. The volume of these ?p “balls” decreases with p. [2]
?1 vs ?2 for prediction:
Typically ridge or ?2 penalties are much better for minimizing prediction error rather than ?1 penalties. The reason for this is that when two predictors are highly correlated, ?1 regularizer will simply pick one of the two predictors. In contrast, the?2 regularizer will keep both of them and jointly shrink the corresponding coefficients a little bit. Thus, while the ?1 penalty can certainly reduce overfitting, you may also experience a loss in predictive power.
A Clarification on ?1-regularization for Exact Sparse Signal Recovery:
However I want to comment on a frequently used analogy that ?1-regularization is *equivalent* to MAP estimation using Laplacian priors. The notion of equivalence here is very subtle.
Remember if the true signal is sparse its coefficients have exactly non-zeros or and approximately sparse if really large coefficients and with the rest of the coefficients decaying to zero quickly. ?1 regularization doesn't merely encourage sparse solutions, but is capable of exactly recovering a signal that is sparse.
non-zeros or and approximately sparse if really large coefficients and with the rest of the coefficients decaying to zero quickly. ?1 regularization doesn't merely encourage sparse solutions, but is capable of exactly recovering a signal that is sparse.
Between 1999-2005, many exciting results in statistics and signal processing [3-6] demonstrated that if the underlying signal was extremely sparse and the design matrix satisfied certain conditions the solution to ?1-regularized objective would coincide with the ?0-regularized (best subset selection) objective, despite having an overall under-determined and high dimensional problem. This would not be possible with ?2 regularization.
An analogous question when performing MAP estimation using laplacian priors would be,
"What class of signals does such a cost function recover accurately ?"
The bottom line here is that geometric intuition that ?1-regularization is *like* laplacian regularized MAP does not mean that laplacian distributions can be used to describe sparse or compressible signals.
A recent paper by Gribonval, et al. [1] demonstrated the followingmany distributions revolving around
maximum a posteriori (MAP) interpretation of sparse regularized
estimators are in fact incompressible, in the limit of large problem
sizes. We especially highlight the Laplace distribution and ?1
regularized estimators such as the Lasso and Basis Pursuit
denoising. We rigorously disprove the myth that the success of
?1 minimization for compressed sensing image reconstruction
is a simple corollary of a Laplace model of images combined
with Bayesian MAP estimation, and show that in fact quite the
reverse is true.
This paper [1] proves that many instances of signals drawn from a laplacian distribution are simply not sparse enough to be good candidates for l1 like recovery. In fact such signals are better estimated using ordinary least squares! An illustration of Fig. 4 from the paper is provided below.
Update: All the theoretical results show that sparse or approximately sparse signals can be recovered effectively by minimizing an ?1-regularized cost function. But you cannot assume that just because laplacian priors have a "sparsifying" property when used in a cost function that one can use the same distribution as a generative model for the signal.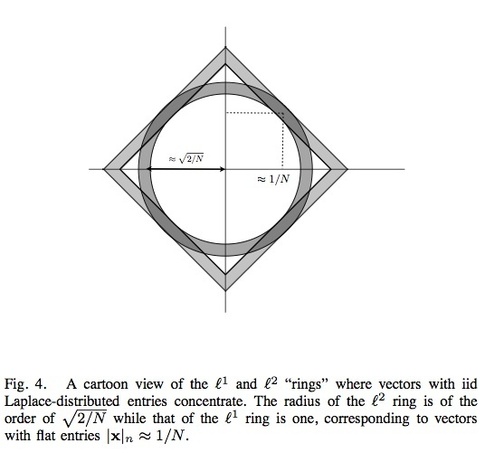 Aleks Jakulin pointed in the comments, that it is not a standard assumption in Bayesian statistics to assume that the data is drawn from the prior. While this maybe true, this result was an important clarification for quasi-bayesians who strongly care about the equivalence of ?0-?1 solutions in signal processing and communication theory—That the theoretical results for exact recovery of sparse signals do not apply if you assume that the geometric intuition of the compressible signal belonging to the l1-ball (see below) is equivalent to probabilistic or generative model interpretation that the signal as iid laplacian.
Aleks Jakulin pointed in the comments, that it is not a standard assumption in Bayesian statistics to assume that the data is drawn from the prior. While this maybe true, this result was an important clarification for quasi-bayesians who strongly care about the equivalence of ?0-?1 solutions in signal processing and communication theory—That the theoretical results for exact recovery of sparse signals do not apply if you assume that the geometric intuition of the compressible signal belonging to the l1-ball (see below) is equivalent to probabilistic or generative model interpretation that the signal as iid laplacian.
[1] http://arxiv.org/pdf/1102.1249v3...
[2] Compressible signals
[3] Compressed sensing
[4]Uncertainty principles and ideal atomic decomposition
[5]Robust uncertainty principles: exact signal reconstruction from highly incomplete frequency information
 Aleks Jakulin pointed in the comments, that it is not a standard assumption in Bayesian statistics to assume that the data is drawn from the prior. While this maybe true, this result was an important clarification for quasi-bayesians who strongly care about the equivalence of ?0-?1 solutions in signal processing and communication theory—That the theoretical results for exact recovery of sparse signals do not apply if you assume that the geometric intuition of the compressible signal belonging to the l1-ball (see below) is equivalent to probabilistic or generative model interpretation that the signal as iid laplacian.
Aleks Jakulin pointed in the comments, that it is not a standard assumption in Bayesian statistics to assume that the data is drawn from the prior. While this maybe true, this result was an important clarification for quasi-bayesians who strongly care about the equivalence of ?0-?1 solutions in signal processing and communication theory—That the theoretical results for exact recovery of sparse signals do not apply if you assume that the geometric intuition of the compressible signal belonging to the l1-ball (see below) is equivalent to probabilistic or generative model interpretation that the signal as iid laplacian.