数据结构全攻略--攻破非线性结构的堡垒之哈弗曼树篇
上篇着重讨论了二叉排序树的一些性质,它其实是一种排序结构,按照中序遍历得到的是一种按照顺序排列好的线性结构。接下来将会着重讨论哈弗曼树。
一、满二叉树和完全二叉树
什么是满二叉树呢?抛开它的概念不说,从它的字面意思上也可以看出满二叉树是一种丰满的二叉树,它要求除叶子结点外的结点都包括左孩子和右孩子。如下图:
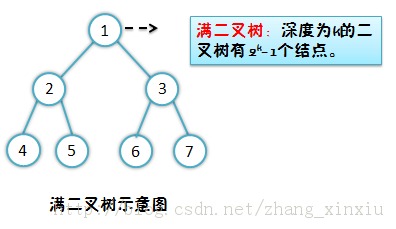
那完全二叉树是什么结构呢?我们看看下图:
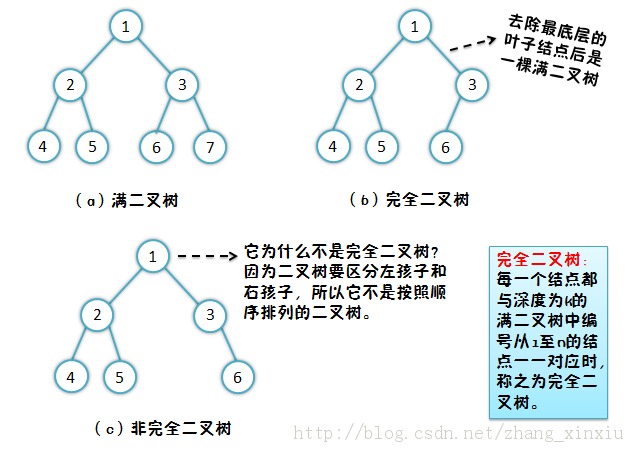
能从上图中看出满二叉树和完全二叉树的关系吗?
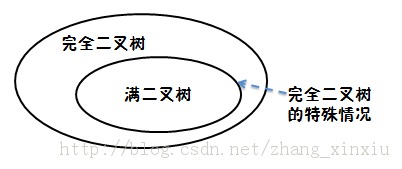
从上图中可以看出两种是包含的关系,完全二叉树中的特殊情况是一种满二叉树。对于完全二叉树和满二叉树的一些性质就不在细说,是一些很基础的东西,如果还不懂的可以去查书找到答案。
二、最优二叉树
为何引入最优二叉树,如何构建最优二叉树?这将是接下来讨论的重点。
首先,来看看最优二叉树的一些基本概念。
1、带权路径长度
结点=路径长度X结点的权值(结点所代表数值的大小);
树=所有结点带权路径长度的和。
最优二叉树就是一类带权路径长度最短的树,它又称为哈弗曼树。
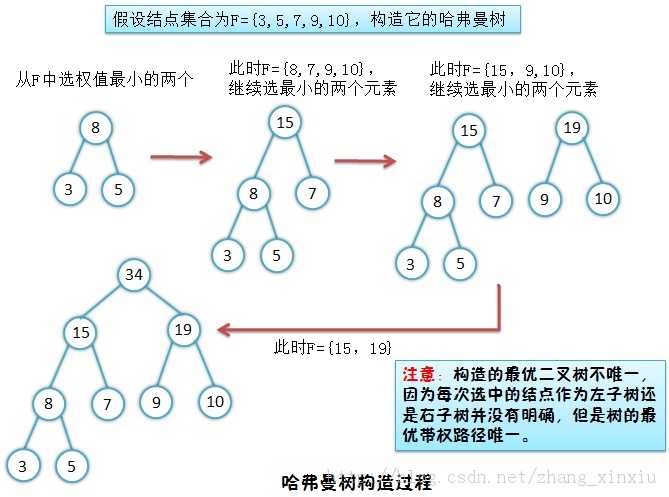
2、那如何构造哈弗曼树呢?
(1)假设有一组二叉树结点的集合F,首先在F中选取两棵权值最小的树作为左右子树构造一棵新的二叉树,置新构造二叉树的根结点的权值为其左右子树根结点的权值之和。
(2)从F中删除这两棵树,同时将新得到的二叉树加入到F中。
(3)重复(1)(2)步,直到F中只含一棵树时为止,这棵树便是最优二叉树。
最优二叉树创建算法:void createHTree(HuffmanTree HT,char *c,int *w,int n)/*数组c[0...n-1]和w[0..n-1]存放了n个字符及其概率,构造哈弗曼树HT*/{ int i, s1,s2;if(n<=1) return;for(int i;i<=n;i++){ /*根据n个权值构造n棵只有根结点的二叉树*/HT[i].ch=c[i-1];HT[i].weight=w[i-1];HT[i].parent=HT[i].lchild=HT[i].rchild=0;}/*for*/for(;i<2*n;++i){ /*初始化*/HT[i].parent=0;HT[i].lchild=0;HT[i].rchild=0;}/*for*/for(i=n+1;i<2*n;i++){/*从HT[1..i-1]中选择parent为0且weight最小的两棵树,其序号为s1和s2*/select(HT,i-1,s1,s2);HT[s1].parent=i;HT[s2].parent=i;HT[i].lchild=s1;HT[i].rchild=s2;HT[i].weight=HT[s1].weight+HT[s1].weight;}/*for*/}/*createHTree*/
哈弗曼编码是在哈弗曼树的基础上对哈弗曼树中的结点进行编码,把左子树的路径编码为0,右子树路径编码为1。

这种编码是为了提高通信效率,因为结点的访问频率不相同,如果采用等长编码的方法对通信原文进行编码,所得的电文的码串就会过长,不利于提高通信效率,因此希望缩短码串的长度。如果对每个字符设计长度不等的编码,且让电文中出现频率较高的字符采用尽可能短的编码,那么不但可以减少码串长度,同时也提高了通信效率,于是引入了哈弗曼编码。
最优二叉树进行译码算法:void Decoding(HuffmanTree HT,int n,char *buff)/*利用具有n个叶子结点的最优二叉树(存储在数组HT中)进行译码,叶子的下标为1~n*//*buff指向原文的编码序列*/{ int p=2*n-1;While(*buff){if(*buff=='0')p=HT[p].lchild; /*进入左分支*/elsep=HT[p].rchild; /*进入右分支*/if(HT[p].lchild==0 && HT[p].rchild==0){printf("%c",HT[p].ch);p=2*n-1; /*回到树根*/}/*if*/buff++}/*while*/}/*Decoding*/
那哈弗曼编码怎么求呢?
通过上图得到了基本的哈弗曼编码,确定了每个结点的最优前缀码,同时也能确定结点的哈弗曼编码,它是从叶子节点为出发点,向上回溯至根结点为止,上溯时走左分支则生成代码0,走右分支则生成代码1。
哈弗曼编码的构造方法:void HuffmanCoding(HuffmanTree HT,HuffmanCode HC,int n)/*n个叶子结点在哈弗曼树HT中的下标为1~n,第i(1≤i≤n)个叶子的编码存放HC[i]中*/{char *cd;int I,start,c,f;if(n<=1)return;cd=(char *)malloc(n);cd[n-1]='\0';for(i=1;i<=n;i++){start=n-1;for(c=i,f=HT[i].parent;f!=0;c=f,f=HT[f].parent)if(HT[f].lchild==c)cd[--start]='0';elsecd[--start]='1';HC[i]=(char*)malloc(n-start0;strcpy(HC[i],&cd[start]);}/*for*/delete cd;}/*HuffmanCoding*/
哈弗曼树的一些基本概念已经讨论完成,另外穿插了一些有关完全二叉树和满二叉树的一些概念,因为这两种二叉树型结构都是特殊的二叉树,满二叉树都知道它的构造方式,但是对于完全二叉树呢?完全二叉树有时候很难区分,所以拿出来重点讨论了下,是不是对非线性结构有个更加深刻的了解了。