阿里巴巴开源项目:分布式数据库同步系统otter(解决中美异地机房)
?
项目背景? ?阿里巴巴B2B公司,因为业务的特性,卖家主要集中在国内,买家主要集中在国外,所以衍生出了杭州和美国异地机房的需求,同时为了提升用户体验,整个机房的架构为双A,两边均可写,由此诞生了otter这样一个产品。
???otter第一版本可追溯到04~05年,此次外部开源的版本为第4版,开发时间从2011年7月份一直持续到现在,目前阿里巴巴B2B内部的本地/异地机房的同步需求基本全上了otte4。
目前同步规模:- 同步数据量6亿文件同步1.5TB(2000w张图片)涉及200+个数据库实例之间的同步80+台机器的集群规模
?
项目介绍名称:otter ['?t?(r)]
译意: 水獭,数据搬运工
语言: 纯java开发
定位: 基于数据库增量日志解析,准实时同步到本机房或跨机房的mysql/oracle数据库.?
?
工作原理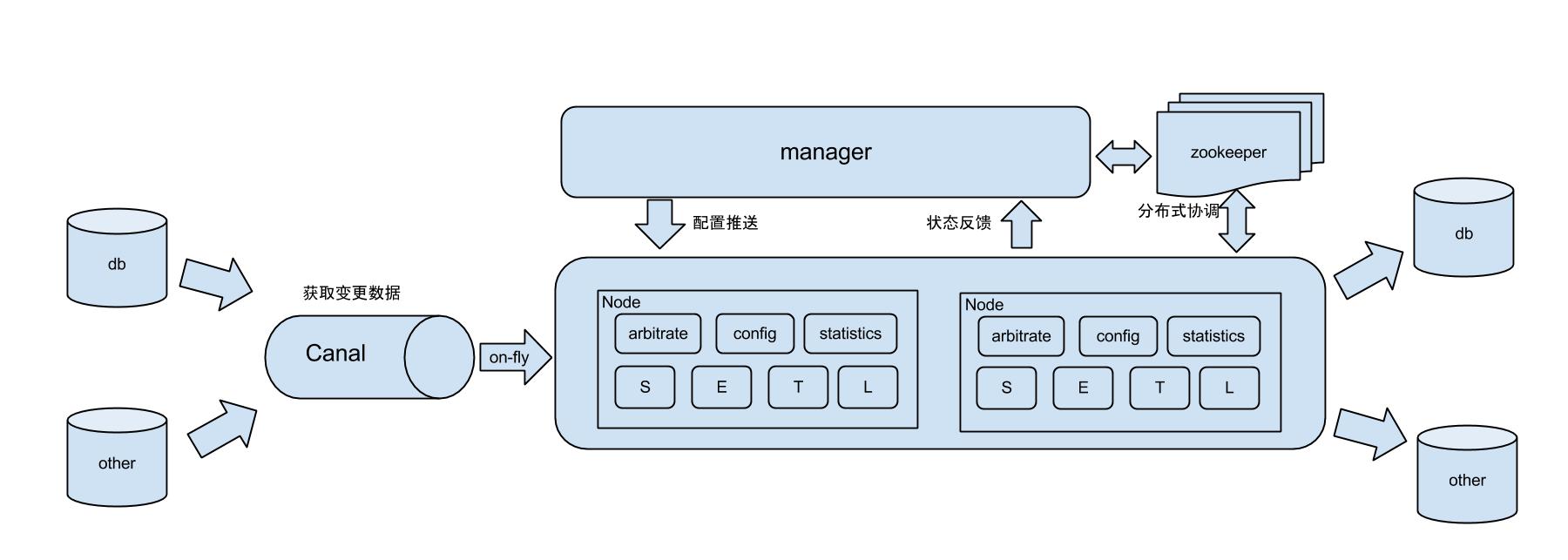
原理描述:
1. ? 基于Canal开源产品,获取数据库增量日志数据。 什么是Canal, ?请点击
2. ? 典型管理系统架构,manager(web管理)+node(工作节点)
? ? ?a. ?manager运行时推送同步配置到node节点
? ? ?b. ?node节点将同步状态反馈到manager上
3. ?基于zookeeper,解决分布式状态调度的,允许多node节点之间协同工作.?
?
什么是canal?
otter之前开源的一个子项目,开源链接地址:http://github.com/alibaba/canal
?
?
otter能解决什么?1. ?异构库同步
? ?a. ?mysql -> ?mysql/oracle. ?(目前开源版本只支持mysql增量,目标库可以是mysql或者oracle,取决于canal的功能)
2. ?单机房同步 (数据库之间RTT < 1ms)
? ?a. 数据库版本升级
? ?b. 数据表迁移
? ?c. 异步二级索引
3. ?跨机房同步 (比如阿里巴巴国际站就是杭州和美国机房的数据库同不,RTT > 200ms,亮点)
? ?a. 机房容灾
4. ?双向同步
? ? a. ?避免回环算法 ?(通用的解决方案,支持大部分关系型数据库)
? ? b. ?数据一致性算法 ? (保证双A机房模式下,数据保证最终一致性,亮点)
5. ?文件同步
? ? a. ?站点镜像 ?(进行数据复制的同时,复制关联的图片,比如复制产品数据,同时复制产品图片).
?
单机房复制示意图: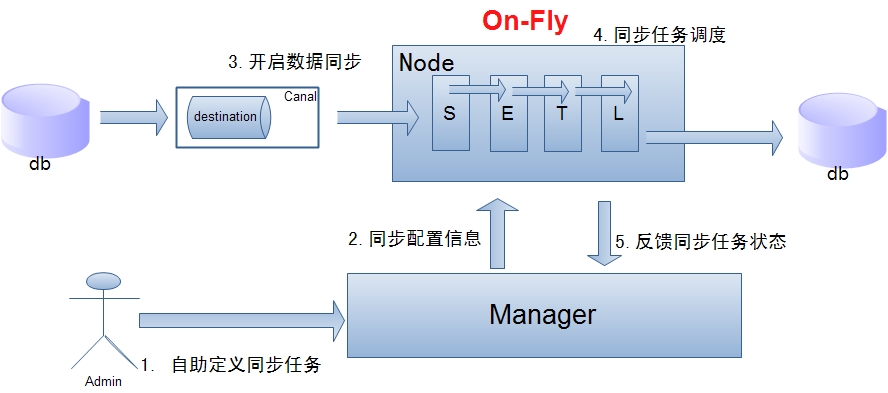
说明:?
? ?a. ?数据on-Fly,尽可能不落地,更快的进行数据同步. ?(开启node?loadBalancer算法,如果Node节点S+ETL落在不同的Node上,数据会有个网络传输过程)
? ?b. ?node节点可以有failover / ?loadBalancer. ?
?
跨机房复制示意图: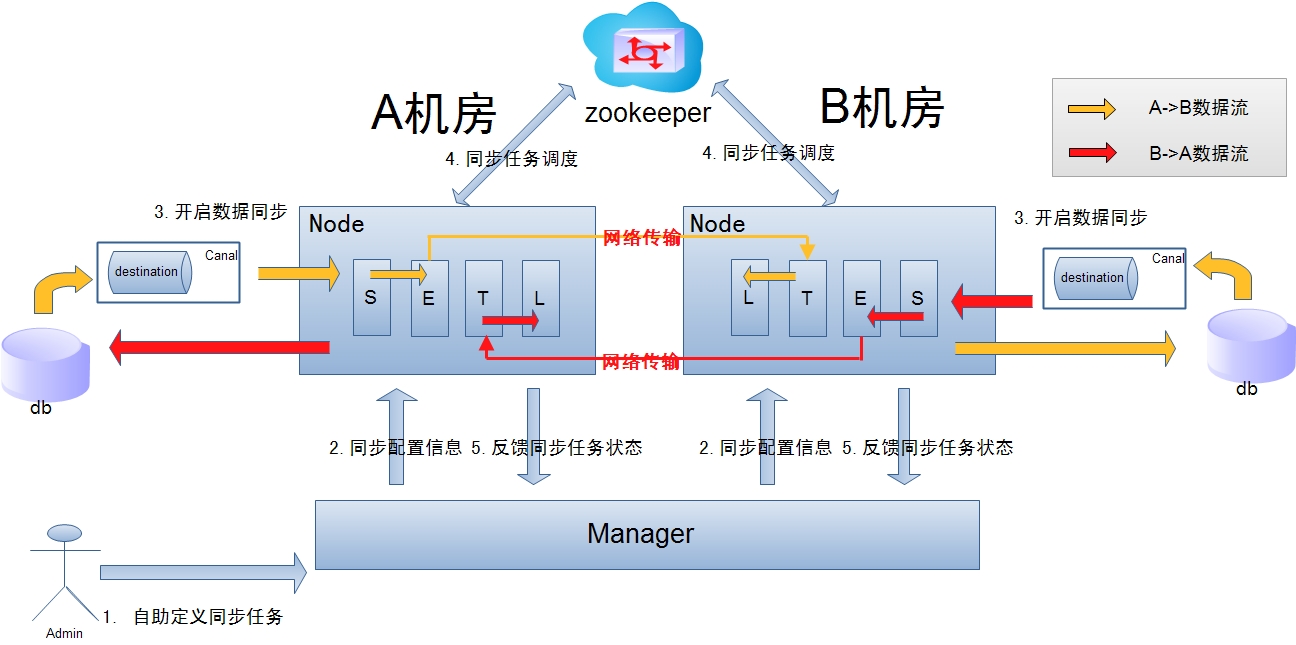
说明:?
? ?a. ?数据涉及网络传输,S/E/T/L几个阶段会分散在2个或者更多Node节点上,多个Node之间通过zookeeper进行协同工作 ?(一般是Select和Extract在一个机房的Node,Transform/Load落在另一个机房的Node)
? ?b. ?node节点可以有failover / ?loadBalancer. ?(每个机房的Node节点,都可以是集群,一台或者多台机器)
?
?相关名词解释
?
otter核心model关系图
?
名词解释Pipeline:从源端到目标端的整个过程描述,主要由一些同步映射过程组成Channel:同步通道,单向同步中一个Pipeline组成,在双向同步中有两个Pipeline组成DateMediaPair:根据业务表定义映射关系,比如源表和目标表,字段映射,字段组等DateMedia : 抽象的数据介质概念,可以理解为数据表/mq队列定义DateMediaSource : 抽象的数据介质源信息,补充描述DateMediaColumnPair : 定义字段映射关系ColumnGroup : 定义字段映射组Node : 处理同步过程的工作节点,对应一个jvmotter的S/E/T/L stage阶段模型
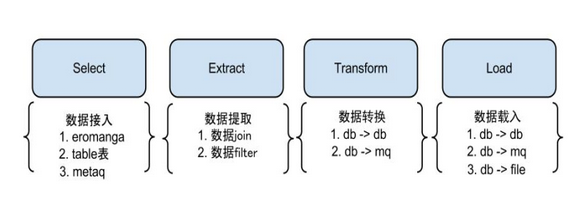
说明:为了更好的支持系统的扩展性和灵活性,将整个同步流程抽象为Select/Extract/Transform/Load,这么4个阶段.
Select阶段: 为解决数据来源的差异性,比如接入canal获取增量数据,也可以接入其他系统获取其他数据等。
Extract/Transform/Load 阶段:类似于数据仓库的ETL模型,具体可为数据join,数据转化,数据Load的
?
相关实现介绍???Otter调度模型???Otter数据入库算法???Otter双向回环控制???Otter数据一致性???Otter高可用性???Otter扩展性?QuickStart
See the page for quick start:?QuickStart.
AdminGuide
See the page for admin deploy guide :?AdminGuide
?
?
otter的S/E/T/L stage阶段模型

说明:为了更好的支持系统的扩展性和灵活性,将整个同步流程抽象为Select/Extract/Transform/Load,这么4个阶段.
Select阶段: 为解决数据来源的差异性,比如接入canal获取增量数据,也可以接入其他系统获取其他数据等。
Extract/Transform/Load 阶段:类似于数据仓库的ETL模型,具体可为数据join,数据转化,数据Load的
?
相关实现介绍???Otter调度模型???Otter数据入库算法???Otter双向回环控制???Otter数据一致性???Otter高可用性???Otter扩展性?QuickStart
See the page for quick start:?QuickStart.
AdminGuide
See the page for admin deploy guide :?AdminGuide
?
?
QuickStart
See the page for quick start:?QuickStart.
AdminGuide
See the page for admin deploy guide :?AdminGuide
?
?