『开源』一个简单的 字符串计算 算法开源
算法开发原因:
自己一直在 配置化编程 方面努力,希望 项目复杂的功能可以用 简单的 配置来完成;
于是 在自己的网站中,使用了一个自己写的 数据库框架,为了给框架提速,于是就 想将 少于 5000 的数据表 进行全表缓存;
然后所有的 数据 就由框架 从缓存中 按照条件 检索——相当于 内存检索;
这时,问题就来了 —— 整个项目,Sql 脚本的 Where 条件,千变万化;
如何判断 某个对象 是否 符合 一个字符串的表达式,这就让我 头疼了;
于是经过搜索,得到: http://bbs.csdn.net/topics/230073145;
最终的解法 是 DataTable.Compute() 函数;还有一个 是 使用微软动态编译技术 的解决方案(这个才是真正无敌的方法)。
但是确有弊端:微软 动态编译技术 计算字符串表达式,即时计算 “1+1”,也需要 300ms,5000个数据的检索,这个是我所无法容忍的。
于是就想 写一个 字符串计算 的算法;
算法版本经历:
算法从去年5月完成,历时 2周业余时间,完成第一版;
今年7月开始,参与了几个 工作流项目的开发,觉着闹心:工作流 应该和 功能分开,结果我看到,代码中,业务代码和工作流代码 纵横交错;特别闹心;
于是就想 抽象一个流程设计器:让开发人员一心一意写业务代码,工作流的代码 全部使用配置,即时修改了流程,开发人员也不用 修改任何代码;
而 流程设计器 的的手稿过程中,发现 不可避免 的有一个环节:条件判断——这个非得使用 字符串计算算法;
于是 改版 第一版算法代码,得到今天的第二版 Laura.Compute;
算法亮点:
新版本 算法,字符串表达式 兼容 SQL脚本(和SQL脚本类似的 字符串格式);
新版本 算法,支持 动态参数(就像 SQL中 WHERE FName=@FName 一样);
新版本 支持 预分析,分析一次 多次执行(可用不同参数);
运算速度 达到 (分析+计算)*20000次 = 2000ms; 分析*1次+计算*20000次 = 150ms;
顺手实现了 字符串表达式 的内存检索(Word LIKE '%cat%'),50000单词,内存检索时间 800ms;
顺手实现了 字符串表达式 的 内存排序(Word DESC, ID ASC),50000单词,内存排序时间 2400ms;
算法思想:
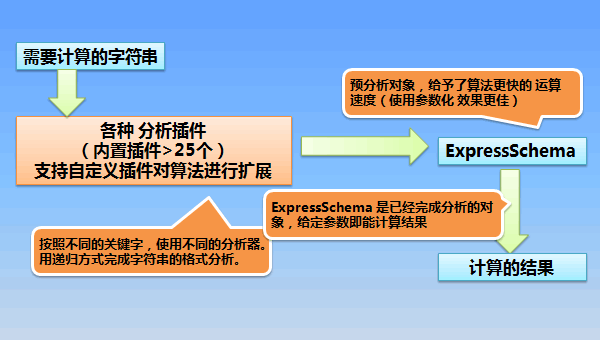
算法用法:
使用代码:
其他用法:
以上只是 一个简单的 表达式:判断 某个 字符串 是否在 一个 数组中。
以下即为 其他 功能(这些功能 全都是 算法的 插件,任何开发人员都可以 在 任意程序集 中 扩展本算法):
内存排序:
内存筛选:
算法源代码:
源码在线阅读
Ps. 最好是能将源码 发不到某个 网络版本控制器上,但是不知道 如何操作,也不知道哪个 哪个平台 有 SVN的版本控制器;
如果哪位有好的 网络版本控制器,希望推荐一哈——还是放到 版本控制器中 开源 比较好;