数据结构全攻略--线性结构不攻自破(一)
上篇博客集中讨论了学习数据结构所要经历的三个过程,这三个过程不仅仅适用于数据结构,同样也适用于其它课程门类的学习。相信经过三个过程后在数据结构上取得较好的分数是没问题的。另外我们还讨论了数据结构一些基本的知识点,使用红色标记的文字是软件考试中的重点部分。接下来进入数据结构的内容部分。
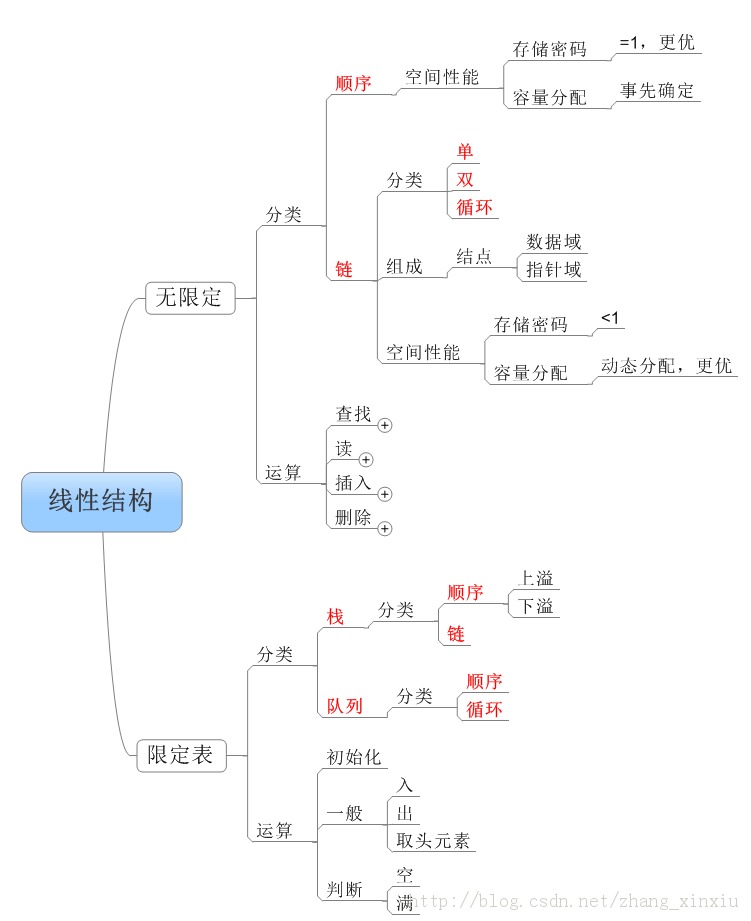
一、线性结构
线性表是一种常用的数据结构,它和指针紧密相连。在实际应用中,线性表是以栈、队列、字符串、数组等特殊线性表的形式来使用的。由于这些特殊线性表都具有各自的特性,因此,掌握这些特殊线性表的特性,对于数据运算的可靠性和提高操作效率都是至关重要的。
Note:在线性结构中常见的运算有增、删、查操作,这些操作归根结底都是对指针的操作。
线性结构关系图:
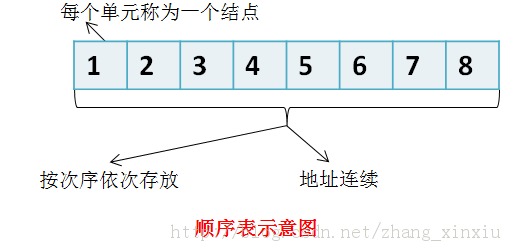
顺序表,需要强调两点:
a) 元素在内存中是以顺序存储的;
b) 内存划分的区域是一个连续的单元。
设线性表中所有结点的类型相同,则每个结点所占用存储空间大小亦相同。假设表中每个结点占用c个存储单元,其中第一个单元的存储地址则是该结点的存储地址,并设表中开始结点a1的存储地址(简称为基地址)是LOC(a1),那么结点ai的存储地址LOC(ai)可通过下式计算:
LOC(ai)= LOC(a1)+(i-1)*c 1≤i≤n
Note:在顺序表中,每个结点ai的存储地址是该结点在表中的位置i的线性函数。只要知道基地址和每个结点的大小,就可在相同时间内求出任一结点的存储地址。是一种随机存取结构。
2、链表
链表在内存中是离散存储的,一个个单独的表。一个链相当于一个结点,结点之间通过指针联系起来。存储空间虽然是离散的,但是通过逻辑上的指针互相联系起来,使得成为一个线性的整体的表。
Note:链表,物理上是离散的,逻辑上是连续的。
Note:每个结点分为数据域和指针域。
由很多结点链起来的,单向的数据结构。
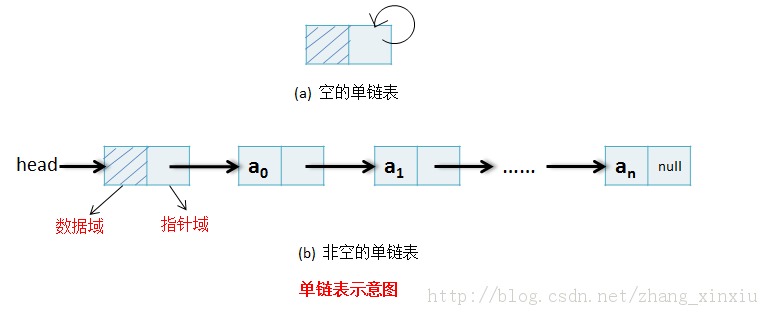
Note:每个结点的前部分是数据域,用来存放数据;后部分是指针域,存放指针的数据,指向了下一个结点的地址。
2.1.1 删除 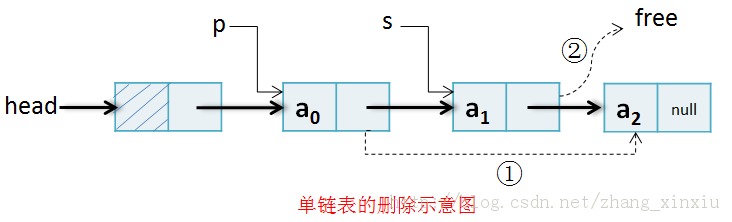
在删除时,首先把P结点的指针域指向S结点的指针域所指向的内容,然后在某一时间释放被删除的节点即可。
void DDeleteNode(DListNode *p) {//在带头结点的单链表中,删除结点*p,设*p为非终端结点 p->next =s->next;//① free(p);// ② } 2.1.2 插入
在插入节点时,首先要把s写入结点的数据域中,然后执行插入操作,将p结点的指针域替换为指向s,s的指针域指向p指针指向的结点。
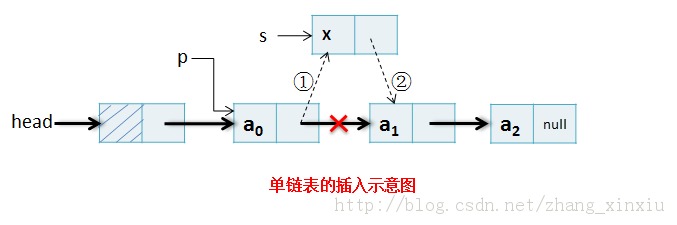
void DInsertBefore(DListNode *p,DataType x) {//在带头结点的单链表中,将值为x的新结点插入*p之后,设p≠NULL DListNode *s=malloc(sizeof(DListNode)); s->data=x;s->next= p->next;// ② p->next=s;//① }
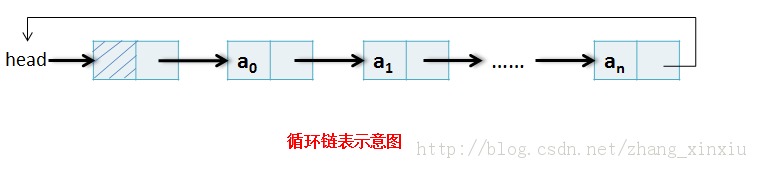
2.2 循环链表
类似于单链表,不同的是循环链表最后一个节点它的下一个节点是头结点,而单链表最后一个节点是空。
2.3 双链表
双(向)链表中有两条方向不同的链,即每个结点中除next域存放后继结点地址外,还增加一个指向其直接前趋的指针域prior。
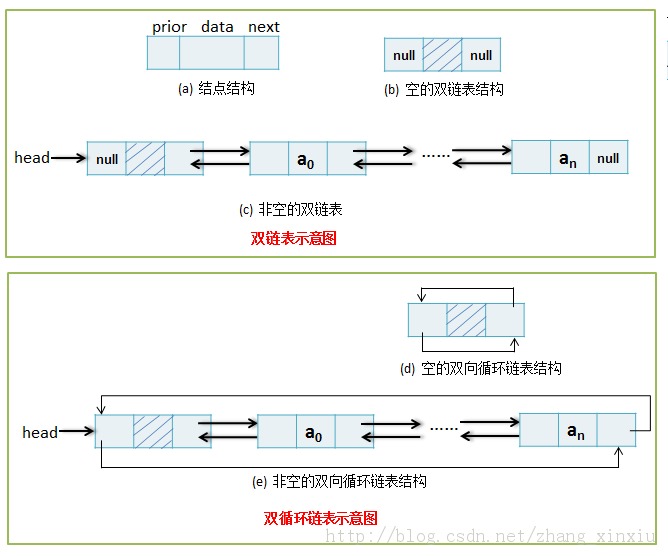
Note:将头结点和尾结点链接起来,为双循环链表。
Contrast:双链表可以朝两个方向移动,而单链表只能朝一个方向移动,所以双链表的灵活性优于单链表,但是它会更消耗内存。
2.3.1 删除
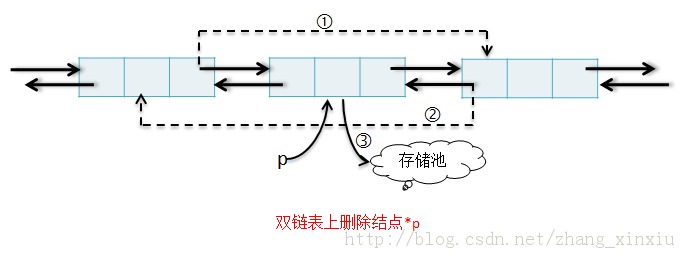
void DDeleteNode(DListNode *p) {//在带头结点的双链表中,删除结点*p,设*p为非终端结点 p->prior->next=p->next;//① p->next->prior=p->prior;//② free(p);//③ }
Note:与单链表上的插入和删除操作不同的是,在双链表中插入和删除必须同时修改两个方向上的指针。
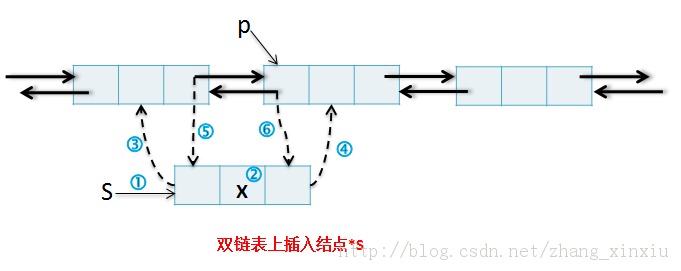
void DInsertBefore(DListNode *p,DataType x) {//在带头结点的双链表中,将值为x的新结点插入*p之前,设p≠NULL DListNode *s=malloc(sizeof(DListNode));//① s->data=x;//② s->prior=p->prior;//③ s->next=p;//④ p->prior->next=s;//⑤ p->prior=s;//⑥ }
上述两个算法的时间复杂度均为O(1)。
3、对比升华
上面介绍了线性结构中最基本的两种线性表--顺序表和链表,最后我们从图上来比较下两种结构的优略性。
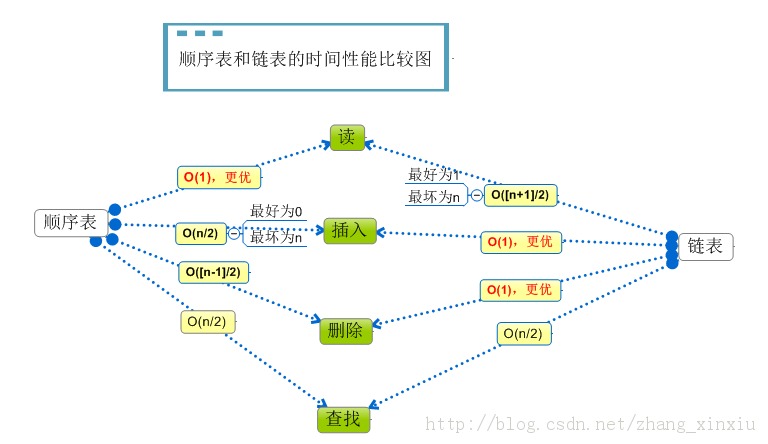
(1)从空间存储性能上分析,因为顺序表存储的数据在内存空间上是连续分配的,而且它的存储容量是事先确定的,所以它相较链表来说,在存储密度上会优于链表。但也因为这种事先分配空间的原因,当存储大小不一的数据时往往会造成空间的浪费,而链表是动态的分配数据的空间,所以在容量分配上链表更有优势。
(2)从时间性能上来说,链表的节点是程离散分配的,它没有固定的结构,这使得对数据的插入和删除更加灵活,不会出现数据的上溢和下溢的情况,也不会出现其它数据的移动问题,所以它的操作会优于顺序表。对于查找来说两种结构有着相同的时间复杂度,在查找时都会遵循线性结构一个个的查找。但对于读操作却有着区别,因为顺序表在读取数据时链表会按照存储顺序一个个的进行读操作,但是链表有复杂的逻辑结构,它的时间的复杂度取决于逻辑结构的复杂的所以对于读操作顺序表会更加便利些。
下篇博客--讨论线性结构中的栈和队列。