项目大数据表分表过程有一个项目运行了一段时间之后,数据越来越大,有几张表数据达到四千多万,这个时候就考
项目大数据表分表过程
有一个项目运行了一段时间之后,数据越来越大,有几张表数据达到四千多万,这个时候就考虑对这些大数据表进行分表来加快数据的操作,OK,寻找可以作为分表的KEY,最后找到了一个deviceId码(包含IMEI、MEID和ESN)这个码有个规律就是由数字和字母组合而成,原先想去deviceId的前六位进行加法运算得到一个数字作为表的分别值,后来经过验证发现这三个码是有规律的,前面都各自有代表的意思,所以导致数据分出来之后有些表的数据多有些少,达不到预期想要的结果,只能考虑另外一种方法,最后决定用deviceId码的最后一位来作为分表的依据,因为最后一位是随机码来的,所以分布比较均匀。
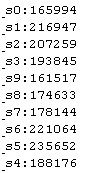
200多万的测试数据,结果还是比较满意的。
找到了规律就可以开始分表了,这时候另一个问题迎面而来就是四千多万的数据怎么分到各个表里面去呢,这个可不是一件小事,而且项目在运行着。
方法1:
写了一个存储过程想一次想把一张表分离好,理论上是没有问题的
必须注意的是:如果自增id不想弄到新表中,那么在select中列出要获取的字段,outfile后面是你想要导出文本的路径:
数据导完算是完成了一大半了,这个时候就是加上索引和约束,因为分表之后每个表还有400多万的数据,要每个表加上索引还是有些些痛苦的
刚开始测试用[client]#password= your_passwordport= 3306socket= /var/lib/mysql/mysql.sock[mysqld]port= 3306socket = /var/lib/mysql/mysql.sockdatadir = /var/lib/mysqllog-error = /var/log/mysql/mysql-error.logpid-file = /var/lib/mysql/mysql.pid#skip-external-lockingskip-lockingskip-name-resolveevent_scheduler=ONcharacter-set-server = utf8max_connections = 6000max_connect_errors = 6000wait_timeout=600interactive_timeout=600log-bin=mysql-binexpire_logs_days=15log_slave_updates = 1binlog_cache_size = 4Mmax_binlog_cache_size = 8Mmax_binlog_size = 1Gbinlog-ignore-db = mysqlbinlog-ignore-db = testbinlog-ignore-db = information_schemakey_buffer_size = 384Msort_buffer_size = 6Mread_buffer_size = 4Mread_rnd_buffer_size = 16Mjoin_buffer_size = 2Mthread_cache_size = 64query_cache_size = 128Mquery_cache_limit = 2Mquery_cache_min_res_unit = 2Kthread_concurrency = 8table_cache = 1024table_open_cache = 512open_files_limit = 10240back_log = 450external-locking = FALSEmax_allowed_packet = 16Mdefault-storage-engine = MyISAMthread_stack = 256K#transaction_isolation = READ-COMMITTEDtmp_table_size = 256Mmax_heap_table_size = 512Mbulk_insert_buffer_size = 64Mmyisam_sort_buffer_size = 64Mmyisam_max_sort_file_size = 4Gmyisam_repair_threads = 1myisam_recoverlong_query_time = 2slow_query_log#skip-networking[mysqldump]quickmax_allowed_packet = 16M[mysql]no-auto-rehash# Remove the next comment character if you are not familiar with SQL#safe-updates[isamchk]key_buffer = 128Msort_buffer_size = 128Mread_buffer = 2Mwrite_buffer = 2M[myisamchk]key_buffer_size = 256Msort_buffer_size = 256Mread_buffer = 2Mwrite_buffer = 2M[mysqlhotcopy]interactive-timeout
这样优化后,再执行添加索引,这些一个表只要2分钟就可以完成建立索引操作。这个时候终于完成了,我们分表的操作了,过程曲直,结果还是理想的。
1 楼 须等待 2013-08-01 Select userId,imei,fid,integral,0,type,insertTime From `integral_log` where lower(RIGHT(imei,1))='1' or lower(RIGHT(imei,1))='a' or lower(RIGHT(imei,1))='k' or lower(RIGHT(imei,1))='u' Into OutFile '/var/lib/mysql/integral_log_s1.txt';
这种sql要扫全表的,为什么半个小时就结束了?