1-hadoop-1.03单节点的安装
?
?
[root@primary local]# chmod +x jdk-6u31-linux-i586.rpm
[root@primary local]# rpm -ivh jdk-6u31-linux-i586.rpm
?
?
[root@primary ~]# vi /etc/profile
export JAVA_HOME=/usr/java/jdk1.6.0_31
export PATH=$JAVA_HOME/bin:$PATH
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
?
source /etc/profile
?
?
???????????????? ?
[root@primary ~]# java -version
java version "1.6.0_31"
Java(TM) SE Runtime Environment (build 1.6.0_31-b04)
Java HotSpot(TM) Client VM (build 20.6-b01, mixed mode, sharing)
?
?
我用来安装的用户为hadoop
?
2、建立ssh无密码登录
删除了机器上所有的认证文件
[hadoop@primary ~]$ rm ~/.ssh/* ?
[hadoop@primary ~]$ ssh-keygen -t dsa -P '' -f ~/.ssh/id_dsa
Generating public/private dsa key pair.
Your identification has been saved in /home/hadoop/.ssh/id_dsa.
Your public key has been saved in /home/hadoop/.ssh/id_dsa.pub.
The key fingerprint is:
8b:db:12:21:57:1c:25:32:d9:4d:4d:16:98:6b:66:88 hadoop@primary
[hadoop@primary ~]$ cat ~/.ssh/id_dsa.pub >> ~/.ssh/authorized_keys
ssh对文件的权限要求
[hadoop@primary ~]$ chmod 644 ~/.ssh/authorized_keys
?
[hadoop@primary ~]$
[hadoop@primary ~]$ ssh localhost
?
?
- rsync ?默认安装了
[hadoop@primary ~]$ rsync --version
rsync? version 2.6.3? protocol version 28
Copyright (C) 1996-2004 by Andrew Tridgell and others
<http://rsync.samba.org/>
Capabilities: 64-bit files, socketpairs, hard links, symlinks, batchfiles,
????????????? inplace, IPv6, 64-bit system inums, 64-bit internal inums
?
rsync comes with ABSOLUTELY NO WARRANTY.? This is free software, and you
are welcome to redistribute it under certain conditions.? See the GNU
General Public Licence for details
?
?
?
?
4)安装HADOOP
[root@primary home]# chmod 777 hadoop-1.0.4-bin.tar.gz
?
?
[hadoop@primary home]$ tar xzvf hadoop-1.0.4-bin.tar.gz
进入HADOOP解压的目录
[hadoop@primary home]$ cd hadoop
查看JAVA—HOME
[hadoop@primary ~]$ env |grep JAVA?????
JAVA_HOME=/usr/java/jdk1.6.0_31
?
我在根目录下创建了一个文件。如下操作的
chown -R? hadoop:root /hadoop?
-bash-3.00$ id
uid=503(hadoop) gid=505(hadoop) groups=0(root),505(hadoop)
-bash-3.00$? tar xzvf hadoop-1.0.4-bin.tar.gz
-bash-3.00$ pwd
/hadoop/hadoop-1.0.4
-bash-3.00$ vi conf/hadoop-env.sh
在 conf/hadoop-env.sh 中配置 Java 环境
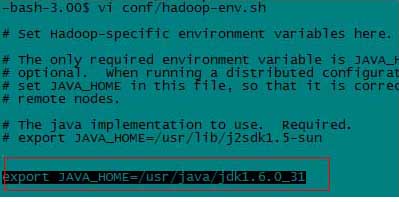
?
配置conf/core-site.xml HDFS 地址和端口
?
hadoop@station1 hadoop-1.0.3]$ cat conf/core-site.xml
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
?
<!-- Put site-specific property overrides in this file. -->
?
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://station1:9000</value>
</property>
?
<property>
<name>dfs.data.dir</name>
<value>/hadoop/web/data/</value>
</property>
?
<property>
<name>dfs.tem.dir</name>
<value>/hadoop/web/tem/</value>
</property>
?
<property>
<name>dfs.name.dir</name>
<value>/hadoop/web/name/</value>
</property>
</configuration>
?
?
配置hdfs-site.xml?? replication
?
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
?
<!-- Put site-specific property overrides in this file. -->
?
<configuration>
<property>
???????? <name>dfs.replication</name>
???????? <value>1</value>
</property>
?
<property>
<name>dfs.data.dir</name>
<value>/hadoop/web/data/</value>
</property>
?
<property>
<name>dfs.tem.dir</name>
<value>/hadoop/web/tem/</value>
</property>
?
<property>
<name>dfs.name.dir</name>
<value>/hadoop/web/name/</value>
</property>
?
?
</configuration>
?
?
?
配置?conf/mapred-site.xml
?
[hadoop@station1 hadoop-1.0.3]$ cat conf/mapred-site.xml
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
?
<!-- Put site-specific property overrides in this file. -->
?
<configuration>
<property>
???????? <name>mapred.job.tracker</name>
???????? <value>localhost:9001</value>
???? </property>
?
?
</configuration>
?
?
?
mapred-queue-acls.xml? mapred-site.xml??????? masters???????????????
[cloud@station1 conf]$ vi mapred-site.xml
?
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
?
<!-- Put site-specific property overrides in this file. -->
?
<configuration>
<property>
???????? <name>mapred.job.tracker</name>
???????? <value>station1:9001</value>
</property>
</configuration>
?
?
?
?
?
?
5)
运行hadoop,进入bin
? (1)格式化文件系统
? ? ? ?hadoop namenode – format
?
-bash-3.00$ ./bin/hadoop - format
Unrecognized option: -
Could not create the Java virtual machine.
报错了。命令错了。
[hadoop@primary hadoop-1.0.4]$ ./bin/hadoop? namenode? -format
12/10/25 16:53:38 INFO namenode.NameNode: STARTUP_MSG:
/************************************************************
STARTUP_MSG: Starting NameNode
STARTUP_MSG:?? host = primary/192.168.26.83
STARTUP_MSG:?? args = [-format]
STARTUP_MSG:?? version = 1.0.4
STARTUP_MSG:?? build = https://svn.apache.org/repos/asf/hadoop/common/branches/branch-1.0 -r 1393290; compiled by 'hortonfo' on Wed Oct? 3 05:13:58 UTC 2012
************************************************************/
12/10/25 16:53:39 INFO util.GSet: VM type?????? = 32-bit
12/10/25 16:53:39 INFO util.GSet: 2% max memory = 19.33375 MB
12/10/25 16:53:39 INFO util.GSet: capacity????? = 2^22 = 4194304 entries
12/10/25 16:53:39 INFO util.GSet: recommended=4194304, actual=4194304
12/10/25 16:53:39 INFO namenode.FSNamesystem: fsOwner=hadoop
12/10/25 16:53:39 INFO namenode.FSNamesystem: supergroup=supergroup
12/10/25 16:53:39 INFO namenode.FSNamesystem: isPermissionEnabled=true
12/10/25 16:53:39 INFO namenode.FSNamesystem: dfs.block.invalidate.limit=100
12/10/25 16:53:39 INFO namenode.FSNamesystem: isAccessTokenEnabled=false accessKeyUpdateInterval=0 min(s), accessTokenLifetime=0 min(s)
12/10/25 16:53:39 INFO namenode.NameNode: Caching file names occuring more than 10 times
12/10/25 16:53:39 INFO common.Storage: Image file of size 112 saved in 0 seconds.
12/10/25 16:53:39 INFO common.Storage: Storage directory /tmp/hadoop-hadoop/dfs/name has been successfully formatted.
12/10/25 16:53:39 INFO namenode.NameNode: SHUTDOWN_MSG:
/************************************************************
SHUTDOWN_MSG: Shutting down NameNode at primary/192.168.26.83
************************************************************/
?
?
?
?
?
? ? (2)启动hadoop?
? ? ? ? ? ? ??start-all.sh?
?
?
[hadoop@primary hadoop-1.0.4]$ cd bin
[hadoop@primary bin]$ pwd
/hadoop/hadoop-1.0.4/bin
[hadoop@primary bin]$ ./start-all.sh
namenode running as process 7387. Stop it first.
localhost: starting datanode, logging to /hadoop/hadoop-1.0.4/libexec/../logs/hadoop-hadoop-datanode-primary.out
localhost: starting secondarynamenode, logging to /hadoop/hadoop-1.0.4/libexec/../logs/hadoop-hadoop-secondarynamenode-primary.out
starting jobtracker, logging to /hadoop/hadoop-1.0.4/libexec/../logs/hadoop-hadoop-jobtracker-primary.out
localhost: starting tasktracker, logging to /hadoop/hadoop-1.0.4/libexec/../logs/hadoop-hadoop-tasktracker-primary.out
?
?
? ? (3)查看进程
? ? ? ? ? ? ? ?jps
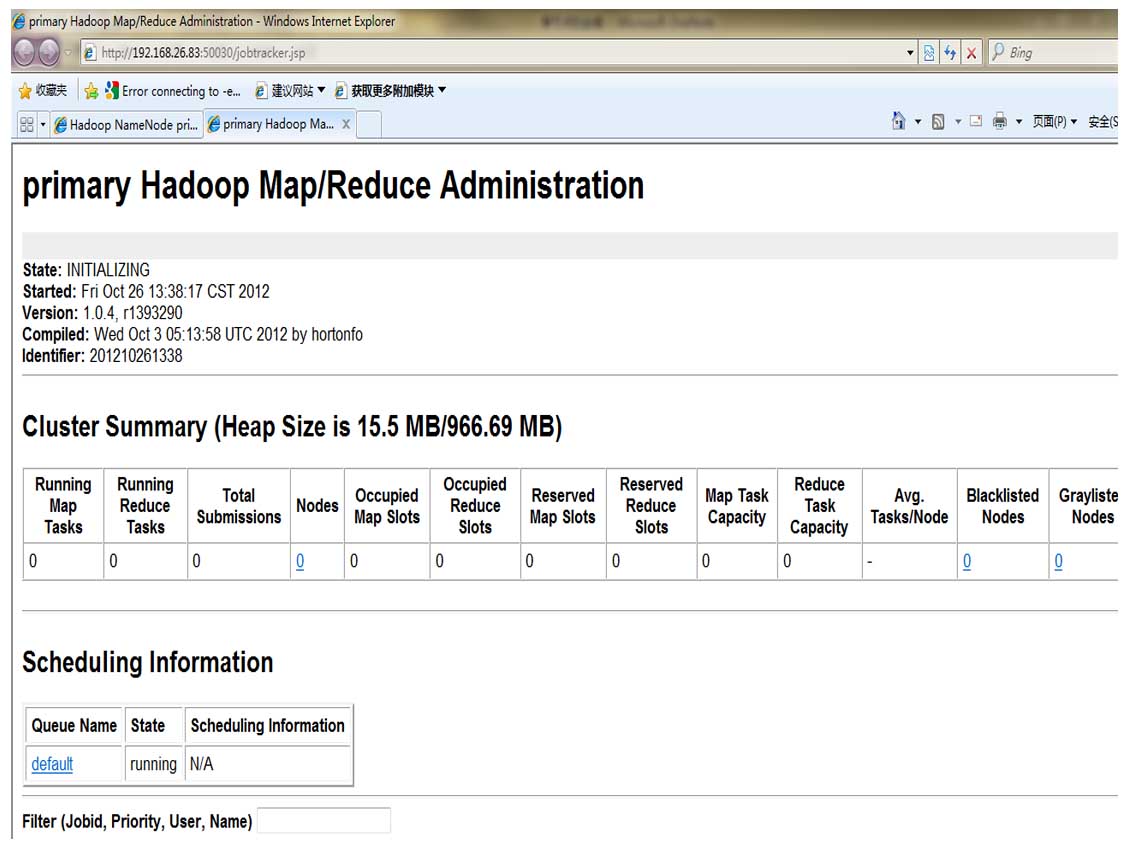
? ? ?(4)查看集群状态
? ? ? ? ? ? ? ?hadoop dfsadmin -report?
? ? ? ? ? ? ??web 方式查看:http://localhost:50070? ? ? ??http://localhost:50030?
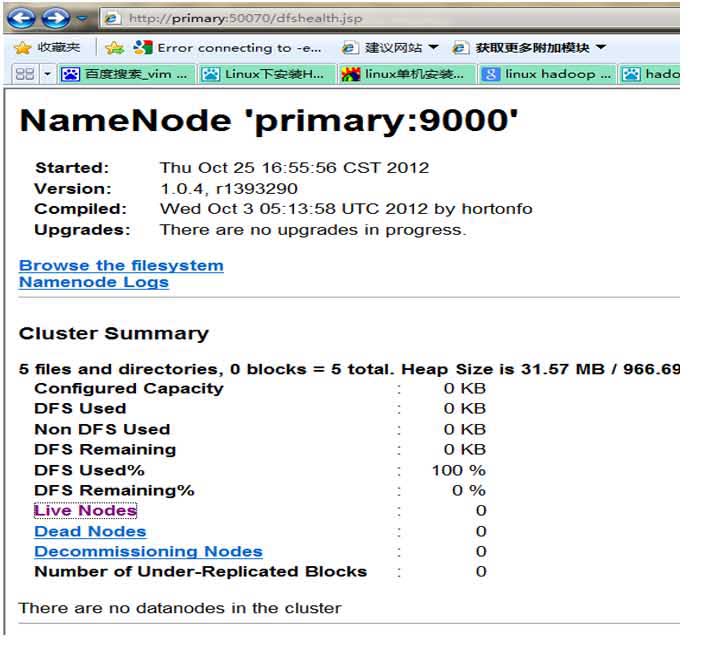
?
?
但没想到的是按网上的步骤配置后datanode节点怎么也没办法启动。后来通过分析启动日志后发现fs.data.dir参数设置的目录权限必需为755,要不启动datanode节点启动就会因为权限检测错误而自动关闭。提示信息如下:
?
?
- WARN?org.apache.hadoop.hdfs.server.datanode.DataNode:?Invalid?directory?in?dfs.data.dir:?Incorrect?permission?for?/data/hadoop/disk,?expected:?rwxr-xr-x,?while?actual:?rwxrwxrwx?
- RROR?org.apache.hadoop.hdfs.server.datanode.DataNode:?All?directories?in?dfs.data.dir?are?invalid.?
?
源文档 <http://gghandsome.blog.51cto.com/398804/822983>
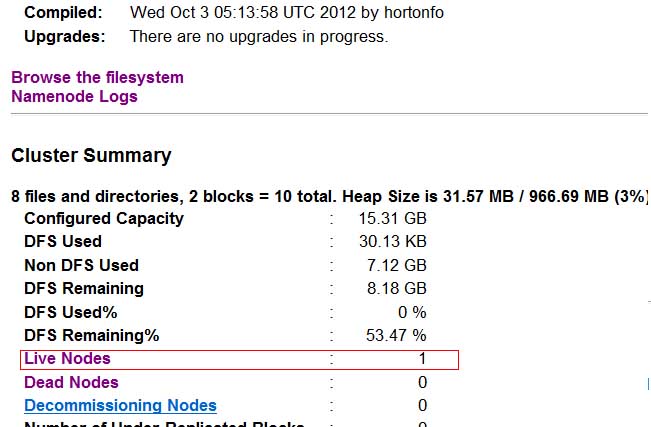
?
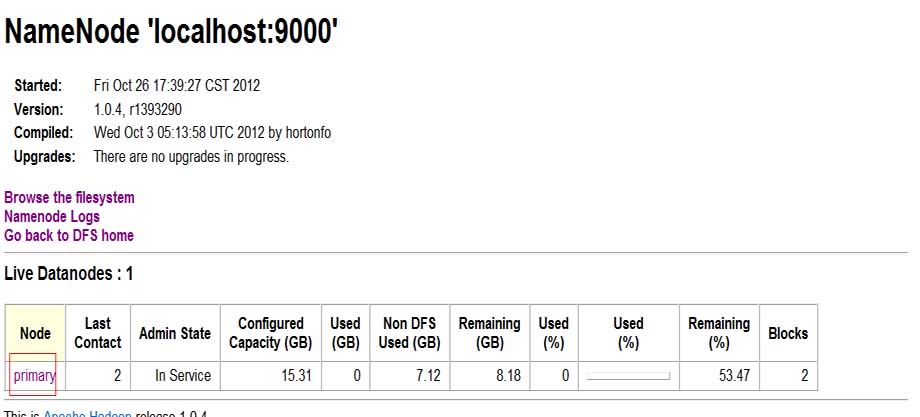
5)测试向DATANODE 添加文件
[hadoop@primary bin]$ pwd
/hadoop/hadoop-1.0.4/bin
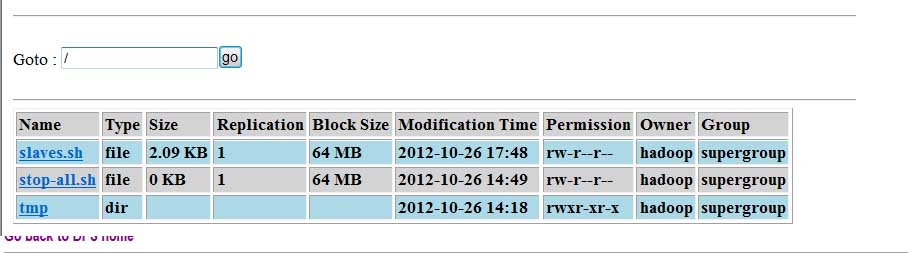
[hadoop@primary bin]$ hadoop fs -put slaves.sh hdfs://localhost:9000/
Warning: $HADOOP_HOME is deprecated.
?
[hadoop@primary bin]$
?
?
6)测试MapReduce
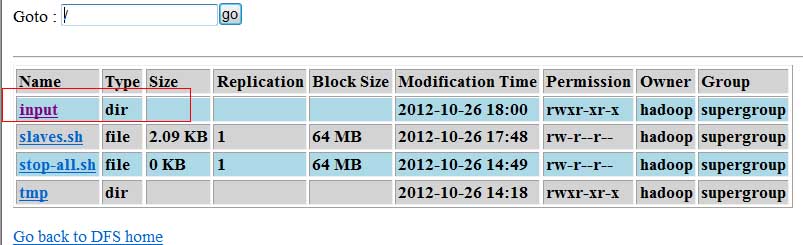
创建目录
[hadoop@primary bin]$ hadoop fs -mkdir?? hdfs://localhost:9000/input/
?
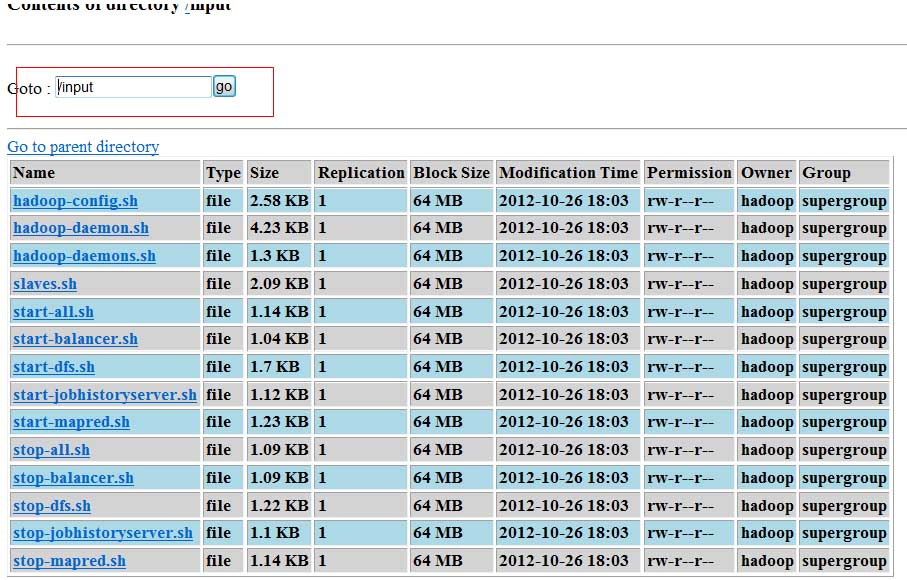
放入文件
?
[hadoop@primary bin]$ hadoop fs -put *.sh???? /input/
?
?
?
计算这个SH文件里的单词数量(注意这个目录在hadoop 的目录,不在BIN目录)
?
[hadoop@station1 hadoop-1.0.3]$ bin/hadoop jar hadoop-examples-1.0.3.jar wordcount /input /out
Warning: $HADOOP_HOME is deprecated.
?
12/10/29 15:00:55 INFO input.FileInputFormat: Total input paths to process : 14
12/10/29 15:00:55 INFO util.NativeCodeLoader: Loaded the native-hadoop library
12/10/29 15:00:55 WARN snappy.LoadSnappy: Snappy native library not loaded
12/10/29 15:00:56 INFO mapred.JobClient: Running job: job_201210291430_0002
12/10/29 15:00:57 INFO mapred.JobClient:? map 0% reduce 0%
12/10/29 15:01:10 INFO mapred.JobClient:? map 14% reduce 0%
12/10/29 15:01:19 INFO mapred.JobClient:? map 28% reduce 0%
12/10/29 15:01:28 INFO mapred.JobClient:? map 42% reduce 9%
12/10/29 15:01:34 INFO mapred.JobClient:? map 57% reduce 9%
12/10/29 15:01:37 INFO mapred.JobClient:? map 57% reduce 14%
12/10/29 15:01:40 INFO mapred.JobClient:? map 71% reduce 14%
12/10/29 15:01:43 INFO mapred.JobClient:? map 71% reduce 19%
12/10/29 15:01:47 INFO mapred.JobClient:? map 85% reduce 19%
12/10/29 15:01:53 INFO mapred.JobClient:? map 100% reduce 23%
12/10/29 15:02:00 INFO mapred.JobClient:? map 100% reduce 28%
12/10/29 15:02:06 INFO mapred.JobClient:? map 100% reduce 100%
12/10/29 15:02:11 INFO mapred.JobClient: Job complete: job_201210291430_0002
12/10/29 15:02:11 INFO mapred.JobClient: Counters: 29
12/10/29 15:02:11 INFO mapred.JobClient:?? Job Counters
12/10/29 15:02:11 INFO mapred.JobClient:???? Launched reduce tasks=1
12/10/29 15:02:11 INFO mapred.JobClient:???? SLOTS_MILLIS_MAPS=87869
12/10/29 15:02:11 INFO mapred.JobClient:???? Total time spent by all reduces waiting after reserving slots (ms)=0
12/10/29 15:02:11 INFO mapred.JobClient:???? Total time spent by all maps waiting after reserving slots (ms)=0
12/10/29 15:02:11 INFO mapred.JobClient:???? Launched map tasks=14
12/10/29 15:02:11 INFO mapred.JobClient:???? Data-local map tasks=14
12/10/29 15:02:11 INFO mapred.JobClient:???? SLOTS_MILLIS_REDUCES=55240
12/10/29 15:02:11 INFO mapred.JobClient:?? File Output Format Counters
12/10/29 15:02:11 INFO mapred.JobClient:???? Bytes Written=6173
12/10/29 15:02:11 INFO mapred.JobClient:?? FileSystemCounters
12/10/29 15:02:11 INFO mapred.JobClient:???? FILE_BYTES_READ=28724
12/10/29 15:02:11 INFO mapred.JobClient:???? HDFS_BYTES_READ=23858
12/10/29 15:02:11 INFO mapred.JobClient:???? FILE_BYTES_WRITTEN=381199
12/10/29 15:02:11 INFO mapred.JobClient:???? HDFS_BYTES_WRITTEN=6173
12/10/29 15:02:11 INFO mapred.JobClient:?? File Input Format Counters
12/10/29 15:02:11 INFO mapred.JobClient:???? Bytes Read=22341
12/10/29 15:02:11 INFO mapred.JobClient:?? Map-Reduce Framework
12/10/29 15:02:11 INFO mapred.JobClient:???? Map output materialized bytes=28802
12/10/29 15:02:11 INFO mapred.JobClient:???? Map input records=691
12/10/29 15:02:11 INFO mapred.JobClient:???? Reduce shuffle bytes=28802
12/10/29 15:02:11 INFO mapred.JobClient:???? Spilled Records=4018
12/10/29 15:02:11 INFO mapred.JobClient:???? Map output bytes=34161
12/10/29 15:02:11 INFO mapred.JobClient:???? Total committed heap usage (bytes)=2264064000
12/10/29 15:02:11 INFO mapred.JobClient:???? CPU time spent (ms)=9340
12/10/29 15:02:11 INFO mapred.JobClient:???? Combine input records=3137
12/10/29 15:02:11 INFO mapred.JobClient:???? SPLIT_RAW_BYTES=1517
12/10/29 15:02:11 INFO mapred.JobClient:???? Reduce input records=2009
12/10/29 15:02:11 INFO mapred.JobClient:???? Reduce input groups=497
12/10/29 15:02:11 INFO mapred.JobClient:???? Combine output records=2009
12/10/29 15:02:11 INFO mapred.JobClient:???? Physical memory (bytes) snapshot=1989103616
12/10/29 15:02:11 INFO mapred.JobClient:???? Reduce output records=497
12/10/29 15:02:11 INFO mapred.JobClient:???? Virtual memory (bytes) snapshot=5140561920
12/10/29 15:02:11 INFO mapred.JobClient:???? Map output records=3137
?
?
?下面是上传文件文件的统计
[hadoop@station1 bin]$ grep apache *.sh|wc
???? 14????? 28???? 915
?
hadoop? 统计结果如下
?
查看的路径? (因为面页太大了。我只显视了一部分) 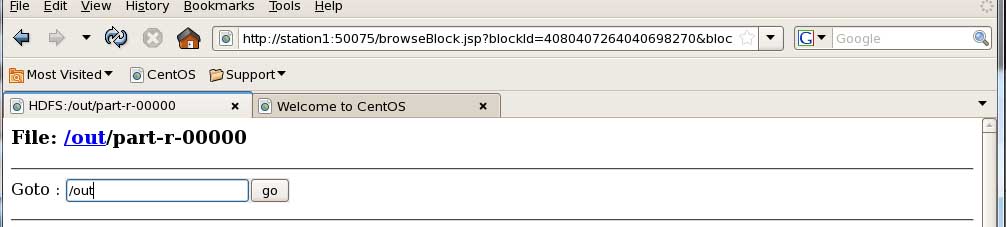
?
结果
?查看运行任务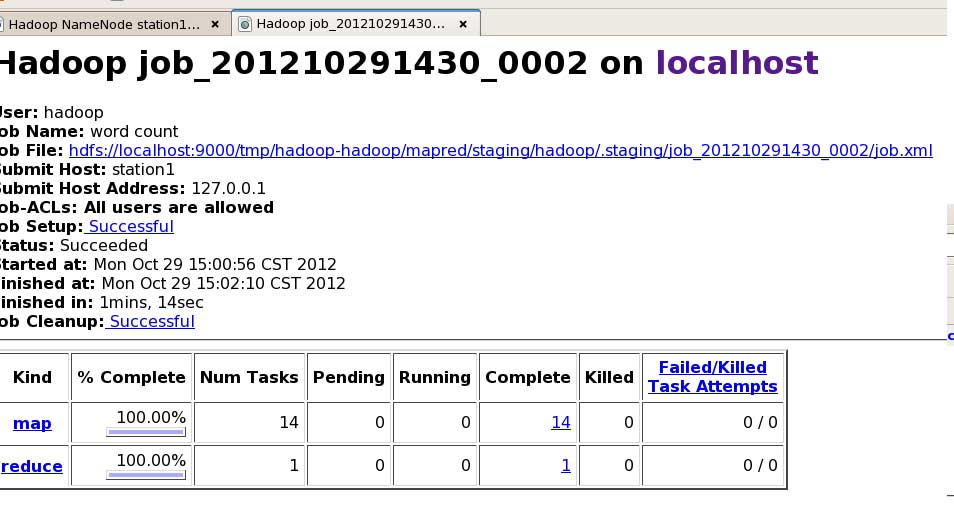
?
?
?
?
?
??
?