计算机网络的协议介绍(二)
网络分层的“艺术”观点
?
传输层最重要的协议为TCP协议和UDP协议。这两者使用“网”的方式走了两个极端。两个协议的对比非常有趣。TCP协议复杂,但传输可靠。UDP协议简单,但传输不可靠。其他的各个传输层协议在某种程度上都是这两个协议的折中。我们先来看传输层协议中比较简单的UDP协议。我们将参考许多之前文章的内容(协议森林01,
UDP:依然不是那么“可靠”
?
尽管UDP协议非常简单,但它的产生晚于更加复杂的TCP协议。早期的网络开发者开发出IP协议和TCP协议分别位于网络层和传输层,所有的通信都要先经过TCP封装,再经过IP封装(应用层->TCP->IP)。开发者将TCP/IP视为相互合作的套装。但很快,网络开发者发现,IP协议的功能和TCP协议的功能是相互独立的。对于一些简单的通信,我们只需要“Best Effort”式的IP传输就可以了,而不需要TCP协议复杂的建立连接的方式(特别是在早期网络环境中,如果过多的建立TCP连接,会造成很大的网络负担,而UDP协议可以相对快速的处理这些简单通信)。UDP协议随之被开发出来,作为IP协议在传输层的"傀儡"。这样,网络通信可以通过应用层->UDP->IP的封装方式,绕过TCP协议。由于UDP协议本身异常简单,实际上只为IP传输起到了桥梁的作用。我们将在TCP协议的讲解中看到更多TCP协议和UDP协议的对比。
?

IP和他的傀儡UDP
?
UDP的数据包同样分为头部(header)和数据(payload)两部分。UDP是传输层(transport layer)协议,这意味着UDP的数据包需要经过IP协议的封装(encapsulation),然后通过IP协议传输到目的电脑。随后UDP包在目的电脑拆封,并将信息送到相应端口的缓存中。
?
UDP协议的头部

来自wikipedia
上面的source port和destination port分别为UDP包的出发端口和目的地端口。Length为整个UDP包的长度。
checksum的算法与IP协议的header checksum算法相类似。然而,UDP的checksum所校验的序列包括了整个UDP数据包,以及封装的IP头部的一些信息(主要为出发地IP和目的地IP)。这样,checksum就可以校验IP:端口的正确性了。在IPv4中,checksum可以为0,意味着不使用checksum。IPv6要求必须进行checksum校验。
?
端口与socket
端口(port)是伴随着传输层诞生的概念。它可以将网络层的IP通信分送到各个通信通道。UDP协议和TCP协议尽管在工作方式上有很大的不同,但它们都建立了从一个端口到另一个端口的通信。
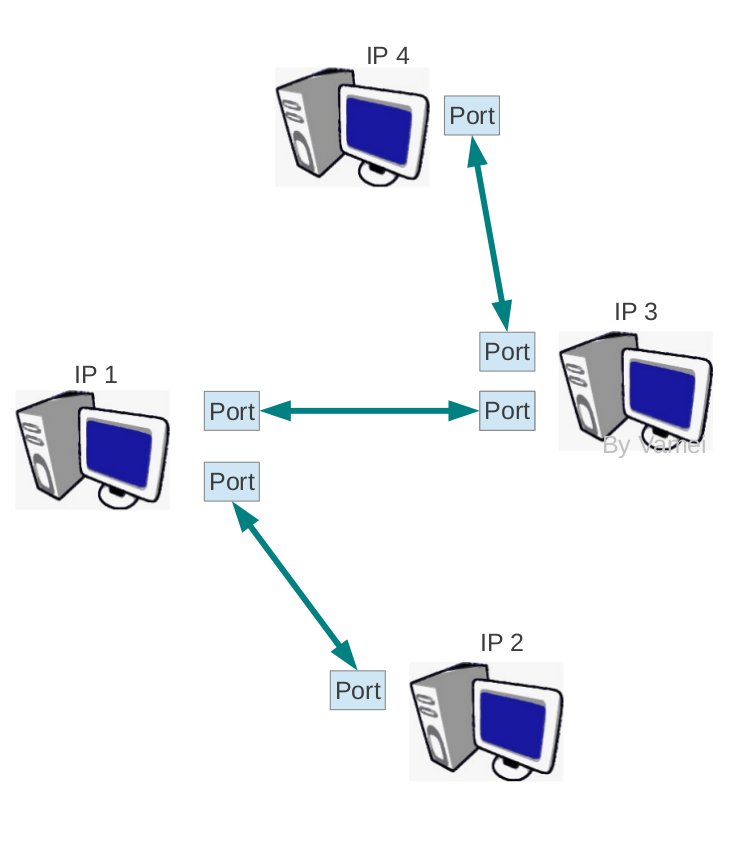 IP:端口
IP:端口
?
随着我们进入传输层,我们也可以调用操作系统中的API,来构建socket。Socket是操作系统提供的一个编程接口,它用来代表某个网络通信。应用程序通过socket来调用系统内核中处理网络协议的模块,而这些内核模块会负责具体的网络协议的实施。这样,我们可以让内核来接收网络协议的细节,而我们只需要提供所要传输的内容就可以了,内核会帮我们控制格式,并进一步向底层封装。因此,在实际应用中,我们并不需要知道具体怎么构成一个UDP包,而只需要提供相关信息(比如IP地址,比如端口号,比如所要传输的信息),操作系统内核会在传输之前会根据我们提供的相关信息构成一个合格的UDP包(以及下层的包和帧)。socket是一个比较大的课题,在协议森林系列中不会过多深入。
(在原始Python服务器我们讨论了如何使用socket建立一个TCP连接,可以作为一个参考)
?
总结
端口是传输层带来的最重要的概念。我们进一步了解了UDP协议。如果已经掌握了IP协议,那么UDP协议就没有任何困难可言,它只是IP协议暴露在传输层上的接口。
?
?
?
片段与编号
TCP片段的头部(header)会存有该片段的序号(sequence number)。这样,接收的计算机就可以知道接收到的片段在原文本流中的顺序了,也可以知道自己下一步需要接收哪个片段以形成流。比如已经接收到了片段1,片段2,片段3,那么接收主机就开始期待片段4。如果接收到不符合顺序的数据包(比如片段8),接收方的TCP模块可以拒绝接收,从而保证呈现给接收主机的信息是符合次序的“流”。
?可靠性
片段编号这个初步的想法并不能解决我们所有的问题。IP协议是不可靠的,所以IP数据包可能在传输过程中发生错误或者丢失。而IP传输是"Best Effort" 式的,如果发生异常情况,我们的IP数据包就会被轻易的丢弃掉。另一方面,如果乱序(out-of-order)片段到达,根据我们上面说的,接收主机不会接收。这样,错误片段、丢失片段和被拒片段的联手破坏之下,接收主机只可能收到一个充满“漏洞”的文本流。

请补上漏洞
TCP的补救方法是,在每收到一个正确的、符合次序的片段之后,就向发送方(也就是连接的另一段)发送一个特殊的TCP片段,用来知会(ACK,acknowledge)发送方:我已经收到那个片段了。这个特殊的TCP片段叫做ACK回复。如果一个片段序号为L,对应ACK回复有回复号L+1,也就是接收方期待接收的下一个发送片段的序号。如果发送方在一定时间等待之后,还是没有收到ACK回复,那么它推断之前发送的片段一定发生了异常。发送方会重复发送(retransmit)那个出现异常的片段,等待ACK回复,如果还没有收到,那么再重复发送原片段... 直到收到该片段对应的ACK回复(回复号为L+1的ACK)。

终于收到ACK的发送主机
当发送方收到ACK回复时,它看到里面的回复号为L+1,也就是发送方下一个应该发送的TCP片段序号。发送方推断出之前的片段已经被正确的接收,随后发出L+1号片段。ACK回复也有可能丢失。对于发送方来说,这和接收方拒绝发送ACK回复是一样的。发送方会重复发送,而接收方接收到已知会过的片段,推断出ACK回复丢失,会重新发送ACK回复。
通过ACK回复和重新发送机制,TCP协议将片段传输变得可靠。尽管底盘是不可靠的IP协议,但TCP协议以一种“不放弃的精神”,不断尝试,最终成功。(技术也可以很励志)

面对“挫折”,TCP协议的态度: never give up
TCP协议和UDP协议走了两个极端。TCP协议复杂但可靠,UDP协议轻便但不可靠。在处理异常的时候,TCP极端负责,而UDP一副无所谓的样子。我们可以顺便“黑”一下UDP协议:

同样面对“挫折”,UDP的态度: who cares...
?滑窗
上面的工作方式中,发送方保持发送->等待ACK->发送->等待ACK...的单线工作方式,这样的工作方式叫做stop-and-wait。stop-and-wait虽然实现了TCP通信的可靠性,但同时牺牲了网络通信的效率。在等待ACK的时间段内,我们的网络都处于闲置(idle)状态。我们希望有一种方式,可以同时发送出多个片段。然而如果同时发出多个片段,那么由于IP包传送是无次序的,有可能会生成乱序片段(out-of-order),也就是后发出的片段先到达。在stop-and-wait的工作方式下,乱序片段完全被拒绝,这也很不效率。毕竟,乱序片段只是提前到达的片段。我们可以在缓存中先存放它,等到它之前的片段补充完毕,再将它缀在后面。然而,如果一个乱序片段实在是太过提前(太“乱”了),该片段将长时间占用缓存。我们需要一种折中的方法来解决该问题:利用缓存保留一些“不那么乱”的片段,期望能在段时间内补充上之前的片段(暂不处理,但发送相应的ACK);对于“乱”的比较厉害的片段,则将它们拒绝(不处理,也不发送对应的ACK)。

总有那么几个“出格”片段
?
滑窗(sliding window)被同时应用于接收方和发送方,以解决以上问题。发送方和接收方各有一个滑窗。当片段位于滑窗中时,表示TCP正在处理该片段。滑窗中可以有多个片段,也就是可以同时处理多个片段。滑窗越大,越大的滑窗同时处理的片段数目越多(当然,计算机也必须分配出更多的缓存供滑窗使用)。
?

同时处理多个片段
我们假设一个可以容纳三个片段的滑窗,并假设片段从左向右排列。对于发送方来说,滑窗的左侧为已发送并已ACK过的片段序列,滑窗右侧是尚未发送的片段序列。滑窗中的片段(比如片段5,6,7)被发送出去,并等待相应的ACK。如果收到片段5的ACK,滑窗将向右移动。这样,新的片段从右侧进入滑窗内,被发送出去,并进入等待状态。在接收到片段5的ACK之前,滑窗不会移动,即使已经收到了片段6和7的ACK。这样,就保证了滑窗左侧的序列是已经发送的、接收到ACK的、符合顺序的片段序列。
对于接收方来说,滑窗的左侧是已经正确收到并ACK回复过的片段(比如片段1,2,3,4),也就是正确接收到的文本流。滑窗中是期望接收的片段(比如片段5, 6, 7)。同样,如果片段6,7先到达,那么滑窗不会移动。如果片段5先到达,那么滑窗会向右移动,以等待接收新的片段。如果出现滑窗之外的片段,比如片段9,那么滑窗将拒绝接收。
下面一个视频中,我尝试模拟可容纳三个片段的滑窗(固定大小)的工作过程。
如果视频加载有问题,可点下面链接:
?
参与连接的如果是两台电脑,那么两台电脑操作系统的TCP模块负责建立连接。每个连接有四个参数(两个IP,两个端口),来表明“谁在和谁通话”。每台电脑都会记录有这四个参数,以确定是哪一个连接。如果这四个参数完全相同,则为同一连接;如果这四个参数有一个不同,即为不同的连接。这意味着,同一个端口上可以有多个连接。内核中的TCP模块生成连接之后,将连接分配给进程使用。
?
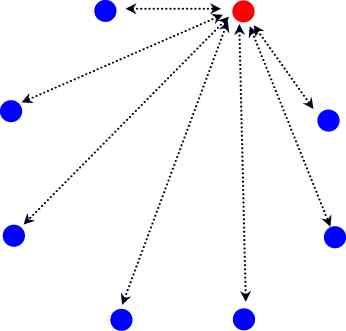
一个端口上可以有多个连接
?
TCP连接是双向(duplex)的。在TCP协议与"流"通信中,我们所展示的TCP传输是单向的。双向连接实际上就是建立两个方向的TCP传输,所以概念上并不复杂。这时,连接的每一方都需要两个滑窗,以分别处理发送的文本流和接收的文本流。由于连接的双向性,我们也要为两个方向的文本流编号。这两个文本流的编号相互独立。为文本流分段和编号由发送方来处理,回复ACK则由接收的一方进行。
?
TCP片段的头部格式
在深入TCP连接之前,我们需要对TCP片段的头部格式有一些了解。我们知道,TCP片段分为头部和数据。数据部分为TCP真正传输的文本流数据。下面为TCP片段的头部格式:

来自wikipedia
先关注下面几点:
1. 一个TCP头部需要包含出发端口(source port)和目的地端口(destination port)。这些与IP头中的两个IP地址共同确定了连接。
2. 每个TCP片段都有序号(sequence number)。这些序号最终将数据部分的文本片段整理成为文本流。
3.
青色为纯粹的ACK片段。整个过程的本质是双方互发含有自己的ISN的SYN片段。根据TCP传输的规则,接收到ISN的一方需要回复ACK,所以共计四片信息在建立连接过程中传输。之所以是三次握手 (而不是四次),是因为server将发送SYN和回复ACK合并到一个TCP片段中。我们以client方为例。client知道自己的ISN(也就是ISN(c))。建立连接之后,它也知道了对方的ISN(s)。此后,如果需要发送文本流片段,则编号为ISN(c) + 1, ISN(c) + 2 ...。如果接收文本流片段,则期待接收ISN(s) + 1, ISN(s) + 2 ...。
连接建立之后,连接的双方就可以按照TCP传输的方式相互发送文本流了。
?
连接的正常终结
一个连接建立之后,连接两端的进程可以利用该连接进行通信。当连接的一方觉得“我讲完了”,它可以终结连接中发送到对方方向的通信。连接最终通过四次握手(four-way handshaking)的方式终结,连接终结使用的是特殊片段FIN(FIN位为1的片段)。
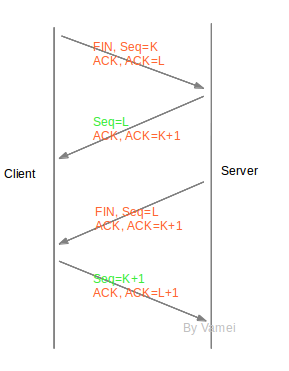
我们可以看到,连接终结的过程中,连接双方也交换了四片信息(两个FIN和两个ACK)。在终结连接的过程中,TCP并没有合并FIN与ACK片段。原因是TCP连接允许单向关闭(half-close)。也就是说,TCP连接关闭了一个方向的传输,成为一个单向连接(half-duplex)。第二个箭头和第三个箭头传递必须分开,才能有空隙在开放的方向上继续传输。如果第二个箭头和第三个箭头合并在一起,那么,随着一方关闭,另一方也要被迫关闭。
第二和第三次握手之间,server可以继续单向的发送片段给client,但client不能发送数据片段给server。
(上面的终结从client先发起,TCP连接终结也可以从server先发起。)
在Client发送出最后的ACK回复,但该ACK可能丢失。Server如果没有收到ACK,将不断重复发送FIN片段。所以Client不能立即关闭,它必须确认Server接收到了该ACK。Client会在发送出ACK之后进入到TIME_WAIT状态。Client会设置一个计时器,等待2MSL的时间。如果在该时间内再次收到FIN,那么Client会重发ACK并再次等待2MSL。所谓的2MSL是两倍的MSL(Maximum Segment Lifetime)。MSL指一个片段在网络中最大的存活时间,2MSL就是一个发送和一个回复所需的最大时间。如果直到2MSL,Client都没有再次收到FIN,那么Client推断ACK已经被成功接收,则结束TCP连接。

TIME_WAIT State
?
总结
TCP是连接导向的协议,与之对应的是像UDP这样的非连接导向的协议。连接能带来更好的传输控制,但也需要更多额外的工作,比如连接的建立和终结。
我们还初步了解了TCP的头部格式。应该注意到,许多时候我们将ACK片段“附着”在其他片段上。相对于纯粹的ACK片段,我们这样做节约了ACK所需的流量。事实上,由于ACK片段所需的ACK位和acknowledge number区域总是存在于TCP的头部,所以附着ACK片段的成本基本上等于0。
?
?
?
?
?
?
累计ACK
在TCP连接中,我们通过将ACK回复“附着”在其他数据片段的方式,减少了ACK回复所消耗的流量。但这并不是全部的故事。TCP协议并不是对每个片段都发送ACK回复。TCP协议实际采用的是累计ACK回复(accumulative acknowledgement)。接收方往往利用一个ACK回复来知会连续多个片段的成功接收。通过累计ACK,所需要的ACK回复通常可以降到50%。
如下图所示,橙色为已经接收的片段。方框为滑窗,滑窗可容纳3个片段。
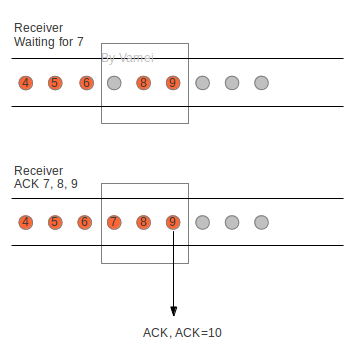
累计ACK
?
滑窗还没接收到片段7时,已接收到片段8,9。这样就在滑窗中制造了一个“空穴”(hole)。当滑窗最终接收到片段7时,滑窗送出一个回复号为10的ACK回复。发送方收到该回复,会意识到,片段10之前的片段已经按照次序被成功接收。整个过程中节约了片段7和片段8所需的两个ACK回复。
此外,接收方在接收到片断,并应该回复ACK的时候,会故意延迟一些时间。如果在延迟的时间里,有后续的片段到达,就可以利用累计ACK来一起回复了。
?
滑窗结构
在之前的讨论中,我们以片段为单位,来衡量滑窗的大小的。真实的滑窗是以byte为单位表示大小,但这并不会对我们之前的讨论造成太大的影响。
发送方滑窗可以分为下面两个部分。offered window为整个滑窗的大小。
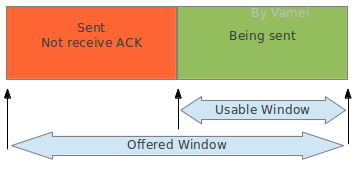
?
接收方滑窗可分为三个部分:
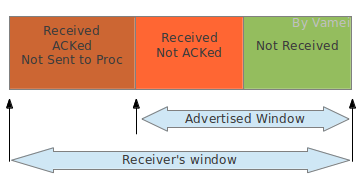
?
可以看到,接收方的滑窗相对于发送方的滑窗多了一个"Received; ACKed; Not Sent to Proc"的部分。接收方接收到的文本流必须等待进程来读取。如果进程正忙于做别的事情,那么这些文本流即使已经正确接收,还是需要暂时占用接收缓存。当出现上述占用时,滑窗的可用部分(也就是图中advertised window)就会缩水。这意味着接收方的处理能力下降。如果这个时候发送方依然按照之前的速率发送数据给接收方,接收方将无力接收这些数据。
?
流量控制
TCP协议会根据情况自动改变滑窗大小,以实现流量控制。流量控制(flow control)是指接收方将advertised window的大小通知给发送方,从而指导发送方修改offered window的大小。接收方将该信息放在TCP头部的window size区域:

发送方在收到window size的通知时,会调整自己滑窗的大小,让offered window和advertised window相符。这样,发送窗口变小,文本流发送速率降低,从而减少了接收方的负担。
?
零窗口
advertised window大小有可能变为0,这意味着接收方的接收能力降为0。发送方收到大小为0的advertised window通知时,停止发送。

零窗口
当接收方经过处理,再次产生可用的advertised window时,接收方会通过纯粹的ACK回复来通知发送方,让发送方恢复发送。然而,ACK回复的传送并不是可靠的。如果该ACK回复丢失,那么TCP传输将陷入死锁(deadlock)状态。
为此,发送方会在零窗口后,不断探测接收方的窗口。窗口探测(window probe)时,发送方会向接收方发送包含1 byte文本流的TCP片段,并等待ACK回复(该ACK回复包含有window size)。由于有1 byte的数据存在,所以该传输是可靠的,而不用担心ACK回复丢失的问题。如果探测结果显示窗口依然为0,发送方会等待更长的时间,然后再次进行窗口探测,直到TCP传输恢复。
?
白痴窗口综合症
滑窗机制有可能犯病,比如白痴窗口综合症 (Silly Window Syndrome)。假设这样一种情形:接收方宣布(advertise)一个小的窗口,发送方根据advertised window,发送一个小的片段。接收方的小窗口被填满,经过处理,接收方再宣布一个小的窗口…… 这就是“白痴窗口综合症”:TCP通信的片段中包含的数据量很小。在这样的情况下,TCP通信的片段所含的信息都很小,网络流量主要是TCP片段的头部,从而造成流量的浪费 (由于TCP头部很大,我们希望每个TCP片段中含有比较多的数据)。

?
如果发送方不断发送小的片段,也会造成“白痴窗口”。为了解决这个问题,需要从两方面入手。TCP中有相关的规定,要求:
1. 接收方宣告的窗口必须达到一定的尺寸,否则等待。
2. 除了一些特殊情况,发送方发送的片段必须达到一定的尺寸,否则等待。特殊情况主要是指需要最小化延迟的TCP应用(比如命令行互动)。
?
总结
累计ACK减少了TCP传输过程中所需的ACK流量。通过流量管理,TCP连接两端的工作能力可以匹配,从而减少不不要的传输浪费。累计ACK和流量控制都是TCP协议的重要特征。
TCP协议相当复杂,并充斥着各种细节。然而TCP协议又是如此重要的一个协议,引领风骚三十年,可以说是互联网的奇迹。这些细节正是TCP协议成功的原因,并值得我们深入了解。
?
?
?
?
?
TCP头部的checksum
接收方(receiver)可以通过校验TCP片段头部中checksum区域来检验TCP片段是否出错。我们已经接触过了IP协议详解的checksum算法。TCP片段的checksum算法与之类似。IP协议的checksum只校验头部,TCP片段头部的checksum会校验包括IP头部、TCP头部和TCP数据在内的整个序列,确保IP地址、端口号和其他相关信息正确。如果TCP片段出错,接收方可以简单的丢弃改TCP片段,也就相当于TCP片段丢失。
TCP片段包裹在一个IP包中传输。IP包可能在网络中丢失。导致IP包丢失的原因可能有很多,比如IP包经过太多的路由器接力,达到hop limit;比如路由器太过拥挤,导致一些IP包被丢弃;再比如路由表(routing table)没有及时更新,导致IP包无法送达目的地。
下面我们要介绍两种重新发送TCP片段的机制:超时重新发送和快速重新发送。?
?
超时重新发送
我们之前已经简单介绍过重新发送的机制:当发送方送出一个TCP片段后,将开始计时,等待该TCP片段的ACK回复。如果接收方正确接收到符合次序的片段,接收方会利用ACK片段回复发送方。发送方得到ACK回复后,继续移动窗口,发送接下来的TCP片段。如果直到计时完成,发送方还是没有收到ACK回复,那么发送方推断之前发送的TCP片段丢失,因此重新发送之前的TCP片段。这个计时等待的时间叫做重新发送超时时间(RTO, retransmission timeout)。
?
RTO:沙漏中沙子的多少
发送方应该在等待多长时间之后重新发送呢?这是重新发送的核心问题。上述过程实际上有往返两个方向:1. 发送片段从发送方到接收方的传输,2. ACK片段从接收方到发送方的传输。整个过程实际耗费的时间称做往返时间(RTT, round trip time)。如果RTT是固定的,比如1秒,那么我们可以让RTO等于RTT。但实际上,RTT的上下浮动很大。比如某个时刻,网络中有许多交通,那么RTT就增加。在RTT浮动的情况下,如果我们设置了过小的RTO,那么TCP会等待很短的时间之后重新发送,而实际上之前发送的片段并没有丢失,只是传输速度比较慢而已,这样,网络中就被重复注入TCP片段,从而浪费网络传输资源。另一方面,如果RTO时间过长,那么当TCP片段已经实际丢失的情况下,发送方不能及时重新发送,会造成网络资源的闲置。所以,RTO必须符合当前网络的使用状况。网络状况越好,RTO应该越短;网络状况越差,RTO应该越长。
?
RTT: 往返时间
?
TCP协议通过统计RTT,来决定合理的RTO。发送方可以测量每一次TCP传输的RTT (从发送出数据片段开始,到接收到ACK片段为止),这样的每次测量得到的往返时间,叫做采样RTT(srtt, sampling round trip time)。建立连接之后,每次的srtt作为采样样本,计算平均值(mean)和标准差(standard deviation),并让RTO等于srtt平均值加上四倍的srtt标准差。
RTO = mean + 4 std
(上述算法有多个变种,根据平台不同有所变化)
平均值反映了平均意义上的RTT,平均往返时间越大,RTO越大。另一方面,标准差越大也会影响RTO。标准差代表了RTT样本的离散程度。如果RTT上下剧烈浮动,标准差比较大。RTT浮动大,说明当前网络状况相对不稳定。因此要设置更长的RTO,以应对不稳定的网络状况。
?
快速重新发送
我们刚才介绍了超时重新发送的机制:发送方送出一个TCP片段,然后开始等待并计时,如果RTO时间之后还没有收到ACK回复,发送方则重新发送。TCP协议有可能在计时完成之前启动重新发送,也就是利用快速重新发送(fast-retransmission)。快速发送机制如果被启动,将打断计时器的等待,直接重新发送TCP片段。
由于IP包的传输是无序的,所以接收方有可能先收到后发出的片段,也就是乱序(out-of-order)片段。乱序片段的序号并不等于最近发出的ACK回复号。已接收的文本流和乱序片段之间将出现空洞(hole),也就是等待接收的空位。比如已经接收了正常片段5,6,7,此时又接收乱序片段9。这时片段8依然空缺,片段8的位置就是一个空洞。

补上空洞
TCP协议规定,当接收方收到乱序片段的时候,需要重复发送ACK。比如接收到乱序片段9的时候,接收方需要回复ACK。回复号为8 (7+1)。此后接收方如果继续收到乱序片段(序号不是8的片段),将再次重复发送ACK=8。当发送方收到3个ACK=8的回复时,发送方推断片段8丢失。即使此时片段8的计时器还没有超时,发送方会打断计时,直接重新发送片段8,这就是快速重新发送机制(fast-retransmission)。
?
快速重新发送机制利用重复的ACK来提示空洞的存在。当重复次数达到阈值时,认为空洞对应的片段在网络中丢失。快速重新发送机制提高了检测丢失片段的效率,往往可以在超时之前探测到丢失片段,并重复发送丢失的片段。
?
总结
凤凰浴火重生。而TCP协议利用重新发送(retransmission)来实现TCP传输的可靠性。重新发送的基本形式是超时重新发送,根据统计的往返时间来设置超时标准;如果超时,则重新发送TCP片段。另一方面,快速重新发送则通过乱序片段的ACK来更早的推断出片段的丢失。
?
?
?
?
?
?
为了解决这一缺陷,从八十年代开始,TCP协议中开始加入堵塞控制(congestion control)的功能,以避免堵塞崩溃的出现。多个算法被提出并实施,大大改善了网络的交通状况。直到今天,堵塞控制依然是互联网研究的一个活跃领域。
?
公德
现实中,当我们遇到堵车,可能就会希望兴建立交桥和高架,或者希望有一位交警来疏导交通。而TCP协议的堵塞控制是通过约束自己实现的。当TCP的发送方探测到网络交通拥堵时,会控制自己发送片段的速率,以缓解网络的交通状况,避免堵塞崩溃。简言之,TCP协议规定了发送方需要遵守的“公德”。

?
我们先来说明堵塞是如何探测的。在TCP重新发送中,我们已经总结了两种推测TCP片段丢失的方法:ACK超时和重复ACK。一旦发送方认为TCP片段丢失,则认为网络中出现堵塞。
另一方面,TCP发送方是如何控制发送速率呢?TCP协议通过控制滑窗(sliding window)大小来控制发送速率。在TCP滑窗管理中,我们已经见到了一个窗口限制,就是advertised window size,以实现TCP流量控制。TCP还会维护一个congestion window size,以根据网络状况来调整滑窗大小。真实滑窗大小取这两个滑窗限制的最小值,从而同时满足两个限制 (流量控制和堵塞控制)。

?advertised window vs congestion window
我们将专注于congestion window。(Hulk,smash!)
?
Congestion Window
congestion window总是处于两种状态的一个。这两种状态是:
上图是概念性的。实际的实施要比上图复杂,而且根据算法不同会有不同的版本。cwnd代表congestion window size。我们以片段的个数为单位,来表示cwnd的大小 (同样是概念性的)。
Congestion window从slow start的状态开始。Slow start的特点是初始速率低,但速率不断倍增。每次进入到slow start状态时,cwnd都需要重置为初始值1。发送方每接收到一个正确的ACK,就会将congestion window增加1,从而实现速率的倍增(由于累计ACK,速率增长可能会小于倍增)。
当congestion window的大小达到某个阈值ssthresh时,congestion进入到congestion avoidance状态。发送速率会继续增长。发送方在每个窗户所有片段成功传输后,将窗口尺寸增加1(实际上就是每个RTT增加1)。所以在congestion avoidance下,cwnd线性增长,增长速率慢。
如果在congestion avoidance下有片段丢失,重新回到slow start状态,并将ssthresh更新为cwnd的一半。
我们看到,sshthresh是slow start到congestion avoidance的切换点。而片段丢失是congestion avoidance到slow start的切换点。一开始sshthresh的值一般比较大,所以slow start可能在切换成congestion avoidance之前就丢失片段。这种情况下,slow start会重新开始,而ssthresh更新为cwnd的一半。
?
总的来说,发送速率总是在增长。如果片段丢失,则重置速率为1,并快速增长。增长到一定程度,则进入到慢性增长。快速增长和慢性增长的切换点(sshthred)会随着网络状况(何时出现片段丢失)更新。通过上面的机制,让发送速率处于动态平衡,不断的尝试更大值。初始时增长块,而接近饱和时增长慢。但一旦尝试过度,则迅速重置,以免造成网络负担。
?
总结
阻塞控制有效的提高了互联网的利用率。阻塞控制的算法多种多样,并且依然不完善。一个常见的问题是cwnd在接近饱和时线性增长,因此对新增的网络带宽不敏感。
互联网利用“公德”来实现效率。“公德”和效率似乎可以并存。
到现在为止,TCP协议的介绍就可以告一段落了。可以回想一下TCP的几大模块:分段与流,滑窗,连接,流量控制,重新发送,堵塞控制。