linux环境下Hadoop 2.0.3单机部署
<final>true</final>
</property>
</configuration>
(3) 在etc/hadoop目录中编辑hdfs-site.xml
<configuration>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/usr/lib/hadoop-2.0.0-alpha/workspace/hadoop_space/hadoop23/dfs/name</value>
<description>Determines where on the local filesystem the DFS name node should store the name table.If this is a comma-delimited list of directories,then name table is replicated in all of the directories,for redundancy.</description>
<final>true</final>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/usr/lib/hadoop-2.0.0-alpha/workspace/hadoop_space/hadoop23/dfs/data</value>
<description>Determines where on the local filesystem an DFS data node should store its blocks.If this is a comma-delimited list of directories,then data will be stored in all named directories,typically on different devices.Directories that do not exist are ignored.</description>
<final>true</final>
</property>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.permission</name>
<value>false</value>
</property>
</configuration>
路径
file:/home/hadoop/workspace/hadoop_space/hadoop23/dfs/name与
file:/home/hadoop/workspace/hadoop_space/hadoop23/dfs/data
是计算机中的一些文件夹,用于存放数据和编辑文件的路径必须用一个详细的URI描述。
(4)在 /etc/hadoop 使用以下内容创建一个文件mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.job.tracker</name>
<value>hdfs://10.1.50.170:9001</value>
<final>true</final>
</property>
<property>
<name>mapreduce.map.memory.mb</name>
<value>1536</value>
</property>
<property>
<name>mapreduce.map.java.opts</name>
<value>-Xmx1024M</value>
</property>
<property>
<name>mapreduce.reduce.memory.mb</name>
<value>3072</value>
</property>
<property>
<name>mapreduce.reduce.java.opts</name>
<value>-Xmx2560M</value>
</property>
<property>
<name>mapreduce.task.io.sort.mb</name>
<value>512</value>
</property>
<property>
<name>mapreduce.task.io.sort.factor</name>
<value>100</value>
</property>
<property>
<name>mapreduce.reduce.shuffle.parallelcopies</name>
<value>50</value>
</property>
<property>
<name>mapred.system.dir</name>
<value>file:/usr/lib/hadoop-2.0.0-alpha/workspace/hadoop_space/hadoop23/mapred/system</value>
<final>true</final>
</property>
<property>
<name>mapred.local.dir</name>
<value>file:/usr/lib/hadoop-2.0.0-alpha/workspace/hadoop_space/hadoop23/mapred/local</value>
<final>true</final>
</property>
</configuration>
路径:
file:/home/hadoop/workspace/hadoop_space/hadoop23/mapred/system与
file:/home/hadoop/workspace/hadoop_space/hadoop23/mapred/local
为计算机中用于存放数据的文件夹路径必须用一个详细的URI描述。
(5)编辑yarn-site.xml
<configuration>
<property>
<name>yarn.resourcemanager.address</name>
<value>10.1.50.170:8080</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>10.1.50.170:8081</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>10.1.50.170:8082</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce.shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
</configuration>
(6) 在 /etc/hadoop 目录中创建hadoop-env.sh 并添加:
export HADOOP_FREFIX=/usr/lib/hadoop-2.0.0-alpha
export HADOOP_COMMON_HOME=${HADOOP_FREFIX}
export HADOOP_HDFS_HOME=${HADOOP_FREFIX}
export PATH=$PATH:$HADOOP_FREFIX/bin
export PATH=$PATH:$HADOOP_FREFIX/sbin
export HADOOP_MAPRED_HOME=${HADOOP_FREFIX}
export YARN_HOME=${HADOOP_FREFIX}
export HADOOP_CONF_HOME=${HADOOP_FREFIX}/etc/hadoop
export YARN_CONF_DIR=${HADOOP_FREFIX}/etc/hadoop
export JAVA_HOME=/usr/lib/jvm/java-7-sun
另,需要yarn-env.sh中充填相同的内容,再配置到各节点。
配置过程中遇到的问题:
▼在浏览器中localhost:8088中,只能看到主节点的信息,看不到datanode的信息。
解决方法:在重新配置yarn.xml(以上为修改后内容)后已经可以看到两个节点,但启动后有一个datanode会自动关闭。
▼在纠结了很长时间kerbose的问题后,才找到运行不能的原因是这个提示:
INFO mapreduce.Job: Job job_1340251923324_0001 failed with state FAILED due to: Application application_1340251923324_0001 failed 1 times due to AM Container for appattempt_1340251923324_0001_000001 exited with exitCode: 1 due to:Failing this attempt.. Failing the application.
按照一个国外友人的回贴[6]fs.deault.name -> hdfs://localhost:9100 in core-site.xml ,mapred.job.tracker - > http://localhost:9101 in mapred-site.xml,错误提示发生改变。再把hadoop-env.sh中的内容copy到yarn-env.sh中,平台就可以勉强运行了(还是有报警)
5.初始化hadoop
首先格式化 namenode,输入命令 hdfs namenode –format;
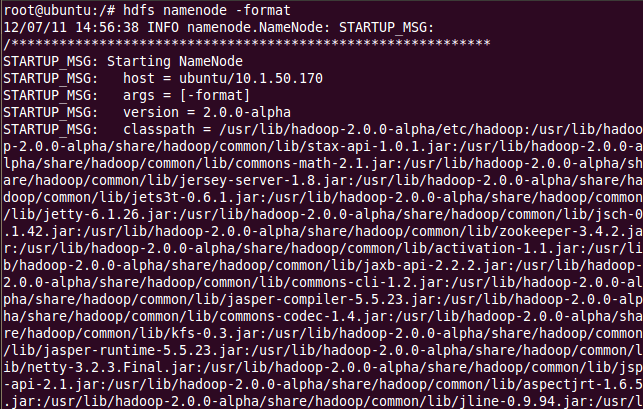
然后开始守护进程 hadoop-daemon.sh start namenode 和 hadoop-daemon.sh start datanode或(可以同时启动:start-dfs.sh);然后,开始 Yarn 守护进程运行 yarn-daemon.sh start resourcemanager和 yarn-daemon.sh start nodemanager(或同时启动: start-yarn.sh)。
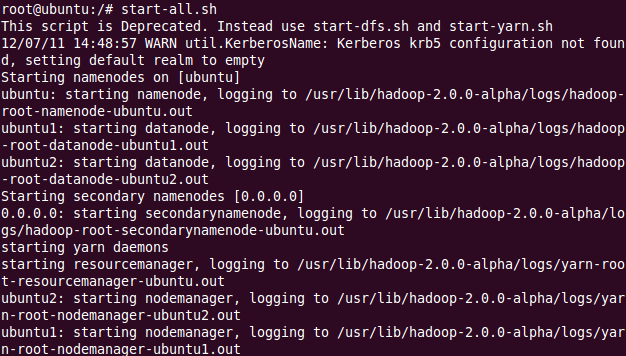
最后,检查守护进程是否启动运行 jps,是否输出以下结果:

在datanode上jps,有以下输出:


浏览UI,打开 localhost:8088 可以查看资源管理页面。
结束守护进程stop-dfs.sh和stop-yarn.sh(或者同时关闭stop-all.sh)。
原文链接:http://wenluoxicheng.blog.163.com/blog/static/192519939201325114018477/