hadoop 源码分析(五)hadoop 任务调度TaskScheduler
hadoop mapreduce 之所有能够实现job的运行,以及将job分配到不同datanode 上的map和reduce task 是由TaskSchduler 完成的.
TaskScheduler mapreduce的任务调度器类,当jobClient 提交一个job 给JobTracker 的时候.JobTracker 接受taskTracker 的心跳.心跳信息含有空闲的slot信息等.JobTracker 则通过调用TaskScheduler 的assignTasks()方法类给报告心跳信息中含有空闲的slots信息的taskTracker 分布任务、
TaskScheduler 类为hadoop的 调度器的抽象类。默认继承它作为hadoop调度器的方式为FIFO,当然也有Capacity 和Fair等其他调度器,也可以自己编写符合特定场景所需要的调度器.通过继承TaskScheduler 类即可完成该功能、
下面就 FIFO 调度器进行简单的说明:
JobQueueTaskScheduler 类为FIFO 调度器的实现类.
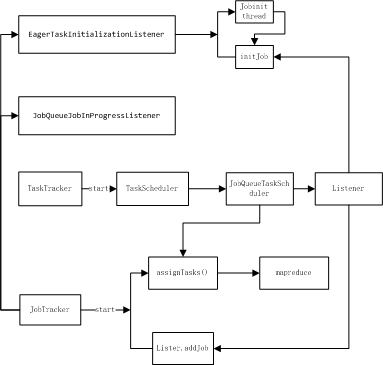
1.首先JobQueueTaskSchduler 注册两个监听器类:
JobQueueJobInProgressListener jobQueueJobInProgressListener;
EagerTaskInitializationListener eagerTaskInitializationListener;
JobQueueJobInProgressListener 维护一个job的queue ,其中JobSchedulingInfo 中包含job调度的信息:priority,startTime,id.以及 jobAdd update 等操作jobqueue的方法
EagerTaskInitializationListener 初始化job的listener ,这里所谓的初始化不是初始化job的属性信息,而是针对已经存在jobqueue中 即将被执行job的初始化,
上面方法中真正执行task的方法为:
obtainNewNodeOrRackLocalMapTask 和obtainNewNonLocalMapTask
下一张详细的分析这两个方法