词库的扩充-百度百科的抓取(二)
??????? 前面抓取了一次百度百科,见 http://rabbit9898.iteye.com/blog/1178199? 是2011年9月份的,这次又对它重新做了一次抓取,发现百度百科做了防抓取设置,抓取起来可真麻烦,每次只能抓取2k个左右,然后得休息半个小时左右吧。
?????? 百度百科到2013-3月份号称有590w的数据,因此想抓取下来全部比较难,但是能把目前大家常用的抓取下来也不错了。
???? 本次抓取的思路:
???? 1)通过百科的每一个词条入口,这个建立在你已经有一批词条,然后调用首页的“进入词条”搜索,可以直接抓取到词条内容。(原始的词条你可以网上收集分词词库) 现在搜索的入口调用地址也用js封装起来了,估计得用httpwatch来找地址了,估计以后会越来越难找入口。
????
????? 2)通过分类导航抓取词条的名词和词条的链接,根据词条的链接又抓取一部分词条内容。
????????? 如文化遗产: http://baike.baidu.com/fenlei/文化遗产 ?入口,抓取页面内容和翻页内容,解析每页当中的词条链接,得到的词条链接再单独抓取 http://baike.baidu.com/view/dddd.htm?(dddd表示词条ID)得到词条内容。 (分类名称可以通过解析词条内容得到一部分;通过入口页自己整理一部分。)
?????
????? 3)对抓取到的具体词条内容解析其中的开放分类,可以得到更多的分类.根据该分类,循环步骤2)可以得到更多的词条。
???? 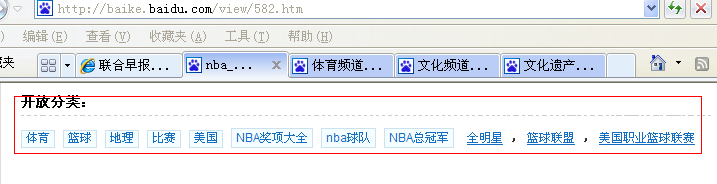
??? 4)对抓取到的具体词条内容解析其中的超链接 (这个参考htmlcleaner Object[] ns = node.evaluateXPath("//a");? ),匹配http://baike.baidu.com/view/dddd.htm?(dddd表示数字) 都是具体的词条。
?
?? 5)重复3和4可以抓取更多的词条。
?
?? 6)对抓取的词条估计有200w左右吧,再进一步筛选你认为优质的词条,估计也就70w左右吧。 当然还有很多不怎么常用的词条,估计用处也不大。
?
?
??