上亿行文本如何高效查询?
由于在开始的时候脑子里面有点想法 所以先自己动手做了一下再来问
是这样的 一个文本文件上亿行 写一个程序在里面查询对应的行
文本文件的每一行是 "Key-Value" 的形式
而Key是数字的字符串形式 是1 - 9 开头的无重复key 且在 int.MaxValue 内
现在要求给出 key 查找出key哪一行的数据 也就是 key - value 都查询出来
由于文件只用作查询 所以不用考虑增删改
我自己动手做了一下 由于现在完整文件不在我这里 我这里只有从文件切下来的200M 有八百多万行
自己写的那个程序针对这 八百万行 还算乐观 不知道对于完整的2G多的文件是啥效果
所以想请教一下 有这方面经验的人士 一般遇到这样的情况你们怎么处理
我是分了三大部
第一拆分文件:
先创建9个文本文件【1 - 9.txt】然后遍历文件每一行将取出每一样第一个字符 根据情况放入9个文本中
然后还有一个 int[9] 用做在遍历的时候保存每个文本文件当前有多少行数
然后遍历完成 将 int[9] 里面保存的每个文件的行数也写入到一个文件中 lines.txt
第二创建索引:
我定义了一个结构
上面的时间 根据情况不定 对于同一个key有时候 是1毫秒 有时候是10+毫秒
那个 拆分文件 和创建索引 可能用了 一分多钟时间 不知道这两部对 完整的文件操作的时候 会用多少时间
总感觉自己的思路有些拼凑 想知道一些对处理大文件有经验的人会怎么做 查询 大文件
[解决办法]
没有看你后边的描述(我觉得没有必要),可能跟你的设计有重复。既然这样查询,那么当让需要一个以索引,例如一个b+树,根据key值进行树形排序,并且每一个节点都是
<key,在你的大文件中的偏移位置(long整形数值)>
[解决办法]
您可以将文件中的数据用程序导入到数据库中(e.g. mysql), 后续的查询就快多了.
自己在文本中做海量数据的查询,不应该这么搞吧?
您得到的那个举行文本数据, 按照您的想法, 可以先用程序拆成100~1000个小文件.
然后您在本地建立一个数据库(mysql), 按照您的文本字段格式, 建立一个或一个关联的表.
用程序将小文件集合中的数据录入到数据库.
查询那就块多了, 效率由数据库, 服务器性能去保证.
我觉得这么干比较靠谱.
[解决办法]
你的做法中,建议不要使用0-9分段的方法,否则某个段的数据量太大了你很不好处理,要重写,否则效率会降低。
不知道你的数据是否按Key排序,如果没有,就外排一次。然后分割成很多文件,每个文件的名称中包含该文件第一条数据的KEY值。
查询时,先根据KEY值,打开对应的文件,然后进行查找。如果这个可以文件全部加载到内存,就二分,否则顺序查找。
因为你说数据不会经常改变,所以这个方法应该比较好。
每次插入,在写入对应的文件前进行排序。
如果某个文件对应的数据段包括的数据量变大,就将它拆分成两个文件。不需要对后继的文件进行更名。
另外创建一个数据结构,保存每个文件的对应行数。查找到对应的行以后,加上它之前的所有文件的总行数就是你要的结果。每次插入或拆分后,要修改这个数据。
另外,就是做成一个Access的文件进行查询,在开发效率和使用效率方面也比这种方法要好得多啊。
[解决办法]
建索引对全部数据扫描一次,读取数据+建索引的时间>直接读取txt文件,而且多出索引的空间
后续读取,读取索引时间=直接读取txt的时间,都是顺序读取,
根据索引去查找txt文件,最好情况第一次就读取到,最坏情况要读到最后,平均时间=1/2直接读取txt时间
[解决办法]
这样做,就算建立二级索引,最坏情况(缓存不命中)要读取硬盘两次。
如果Value定长或者长度相近的话,可以考虑也存到索引表。这样建立二级索引,最坏情况(缓存不命中)只读取硬盘一次。
[解决办法]
你这个做法就可以了,分多个文件那步可以省略,直接创建索引,然后根据索引二分查找,这已经是最直接的方法了,用什么数据库也不会比这个更快了。
也许还有一种更快的方法,用空间换时间,不过索引文件要高达15G,从0到intMax每个key记录一个偏移量,直接根据key数值*4就能定位偏移量,两次磁盘操作就能取出key-value,每个key的操作时间都一样
[解决办法]
这让我想起数据库中最常用的B*索引,下面是典型的B*树索引布局: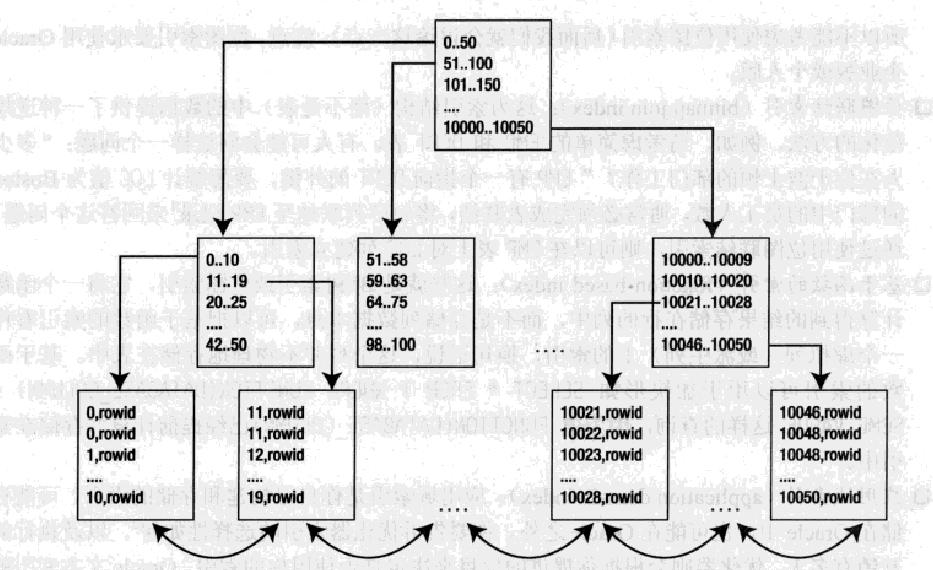
你不妨参考它来设计你的文件索引
[解决办法]
文本?txt文件?加载到内存都是件痛苦的事情,需要配合多文件+索引来实现,否则就在一个txt里面,怎么优化都是逐行读取;
数据库是索引和指针的结合,通过索引获取数据的指针,然后读取指针位置的数据,每个数据单元又有其头,包含了数据的概要信息,你这上亿行的txt,首先要拆分开。。。。
[解决办法]
依据key算出偏移量(但是前提比较扯,先排序,补齐没有的key,对齐每一行,,,,,这样key中就隐含有偏移量信息了)
算出偏移量的时候读取或许可以利用下分区表,直接找到。
我算不算异想天开啊
[解决办法]
55 56 57
综合上述得出:key中必须包含偏移信息(前期需处理数据对齐太蛋疼了)。然后去读分区文件分表记录,找到文件记录信息,算出在key对应的数据所在的簇的范围,读取这个范围的数据。
[解决办法]
这么点数据量很难说明问题。
放1T数据试试看。
而且通过seek操作,大量随机读,估计数据量大了,性能真不好。
[解决办法]
个人认为建立一个数据,分别记录:key,value,行数;逐行对数据分析,存入数据库;把key作为数据库索引;以后只对数据库操作;
[解决办法]
其实你那个分组的过程就是一种排序,只要排序算法没有什么问题,这样做不会有本质的区别,其实你更应该从索引文件的使用上面优化,比如你那个900m的文件可以按每4k一段再做一个索引,这个索引文件只有十几M,可以全部载入内存,在内存二分查找速度要比磁盘查找快很多,找到之后再一次性读入对应的4k的索引数据进行内存查找,4k数据对齐磁盘簇大小,读取速度要比在不同位置读取几十字节快很多倍
[解决办法]
1.不用拆分文件,通过索引优化查询,创建索引文件按首字母或长度拆分,控制数据量。
2.索引使用Dictory保存偏移量或实际数据,序列化到索引文件。
数据量太大,给索引建索引,如先首字母拆分,再长度拆分一次,取前两位建索引等。后一次索引记录前次的偏移量。
索引可以用数组需要排序。
3.查询,可缓存部分索引数据提高效率。
4.如果查询频率低,1秒可返回结果,没必要优化。
[解决办法]
其实我觉得问题的讨论点在于怎么实现未知格式的大数据文件的快速高效检索和操作。而不是要借助于数据库。哪些的。这个问题肯定有办法解决。但是不那么容易而已。一旦找到办法。那必是终身受益。
[解决办法]
1.外排,不是一次性对整个文件进行排序。
2.建议稍稍考虑一下以后的增删改。否则你会发现,代码过不了多久就需要改,说不定还是大改。因为已经分段存储了,需要操作的数据量很少,查入和删除就很简单,打开对应的文档进行操作就行了。
[解决办法]
那说说我的理由:
1.如果把建立索引和分文件的操作这步变为倒入数据库处理会怎样?
2.用户很关注你给他写的是采用数据库还是文本?而程序由你设计,规则由你定,如果采用数据库,让程序运行起来你知道怎么做,所以,采用数据库不是个有顾虑的问题.
3.猜你可能有点主观了,被目前情形形成的观念所限,而决定采用文本方式处理,是为了省导入数据库这一步操作?毕竟如果想提高效率的话,就有必要比较2种方式.
4.如果决定采用文本,平常没接触到如此大量处理数据,只有一点建议:可否采用多线程处理技术试看?
5.思考一下你建立索引文件的初衷是什么目的?我猜是为了载入的数据量少,速度快,当找到KEY后,还得打开原来大文件取数据,这样的消耗和时间与采用数据库比较会怎样?
纯属个人陋见莫怪啊,呵呵!