使用 Linux 和 Hadoop 进行分布式计算?存储在 HDFS 中的文件被分成块,然后将这些块复制到多个计算机中(Dat
使用 Linux 和 Hadoop 进行分布式计算
?
存储在 HDFS 中的文件被分成块,然后将这些块复制到多个计算机中(DataNode)。这与传统的 RAID 架构大不相同。块的大小(通常为 64MB)和复制的块数量在创建文件时由客户机决定。NameNode 可以控制所有文件操作。HDFS 内部的所有通信都基于标准的 TCP/IP 协议。
?
现在回到 Hadoop 上,它是如何实现这个功能的?一个代表客户机在单个主系统上启动的 MapReduce 应用程序称为 JobTracker。类似于 NameNode,它是 Hadoop 集群中惟一负责控制 MapReduce 应用程序的系统。在应用程序提交之后,将提供包含在 HDFS 中的输入和输出目录。JobTracker 使用文件块信息(物理量和位置)确定如何创建其他 TaskTracker 从属任务。MapReduce 应用程序被复制到每个出现输入文件块的节点。将为特定节点上的每个文件块创建一个惟一的从属任务。每个 TaskTracker 将状态和完成信息报告给 JobTracker。图 3 显示一个示例集群中的工作分布。
图 3. 显示处理和存储的物理分布的 Hadoop 集群?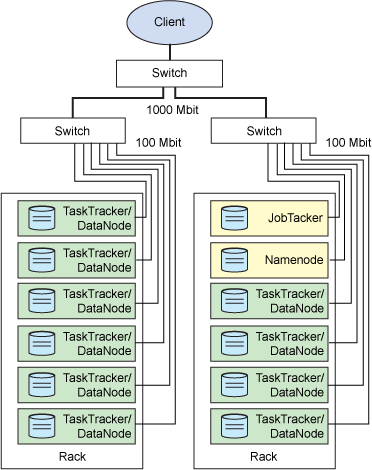 ?
?
Hadoop 的这个特点非常重要,因为它并没有将存储移动到某个位置以供处理,而是将处理移动到存储。这通过根据集群中的节点数调节处理,因此支持高效的数据处理。
结束语毫无疑问,Hadoop 正在变得越来越强大。从使用它的应用程序看,它的前途是光明的。您可以从?参考资料?小节更多地了解 Hadoop 及其应用程序,包括设置您自己的 Hadoop 集群的建议。