拓扑排序中的栈存储结构近期看数据结构,看到拓扑排序中的栈存储数据结构,上面的栈使用数组进行存储,而非St
拓扑排序中的栈存储结构
近期看数据结构,看到拓扑排序中的栈存储数据结构,上面的栈使用数组进行存储,而非Stack定义,使用的非常妙,分享一下。
拓扑排序的主要思想:(1)选择一个入度为0的顶点并输出;(2)从网中删除此顶点及其所有边;(3)重复执行(1)(2)直到不存在入度为0的顶点;比如下面所示的图(采用邻接表表示):
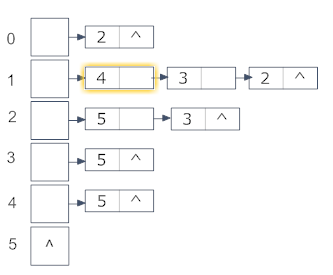
设置保存每个顶点的入度值的数组d,则d如下所示:
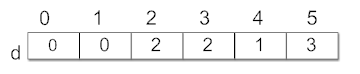
方式一:直接使用d数组作为栈,栈的使用方式如下:
(1)初始化栈,设置链栈指针top为-1;
(2)将入度为0的元素的d[0]进栈,即:的d[0]=top;top=0;此时top指向d[0]元素,表示顶点v0的入度为0,而d[0]的值为-1,表示栈低;
(3)将入度为0的d[1]进栈,即:d[1]=top;top=1;此时top指向d[1]元素,表示顶点v1的入度为0,而d[1]的值为0,表明下一个入度为0的元素为d[0],即对应下一个入度为0的顶点为v0,d[0]的值为-1,所以此栈当前有两个元素d[1]和d[0];
由上面三步步骤初始化数组d为:
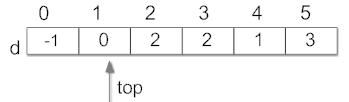
删除顶点v1,得到数组d为:
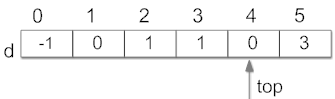
然后依次删除并输出顶点V4,V0,V2,V3,V5(方式一参考《数据结构(c语言描述)》--徐孝凯。。。)
方式二:除了使用数组d外,另外加一个Stack作为栈的存储结构,每次删除一个节点后判断节点的入度是否为零,如果为零则push入Stack中;
Java代码实现如下:
GraphNode节点定义:
由上面的结果可以看出,不仅方式一的结构存储非常妙,而且遍历耗时减小。
分享,快乐,成长
转载请注明出处:http://blog.csdn.net/fansy1990