Lzw字典压缩(思路简单)
???????
?Lzw字典压缩:
??? 1978年,Ziv和Lempel开发了一种基于字典的被称为LZ78 的压缩算法,在LZ78中,字典是一个潜在的先前所见的短语的无限序列。后来由于自身限制,由Terry Welch在1984年提出的关于LZ78压缩算法的变种,他的编码器部署出单个字符,只是输出词典短语中的代号(或者说是代码)。
?
???? lzw的编码词典就像是一张转换表,用来存放每一项,每个表象分配一个代码,默认的是将0~255即8位的ASCII字符集进行了扩充,增加的符号用来表示创建的新的代码。扩充后的代码可以采用自己定义的位来表示,比如12位,15位等等。不过此时用的是数组存储,可定义默认的数组长度可以是2的12次方4096,或者是2的15次方32768。自己是用的队列,所以相当于是默认的可存放2的16次方65536个对象。
?
简单说明:
例如对于abababababababababab,字符a(97)和b(98)出现的次数很多,那么就可以将ab作为一个新的节点例如256存储,此时文件就相当于256,256,256。。。如果将ababab当作257,那么文件就会变为257,257.压缩的效果还是很明显的。
适用范围:
??? ?对于文件中字符重复出现次数多的压缩效果比较好。
?
?效果展示
压缩前:
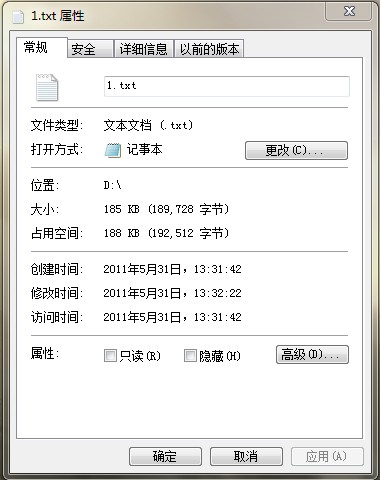
?
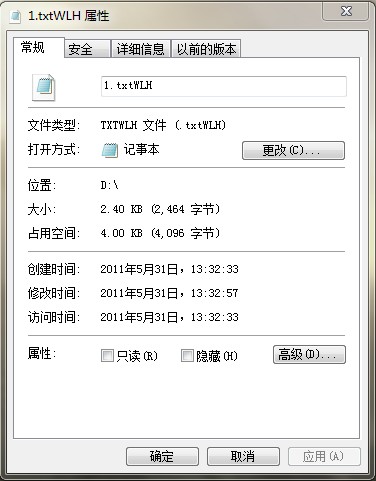
压缩后:
举例实现:
例如比较简单的abababab
压缩: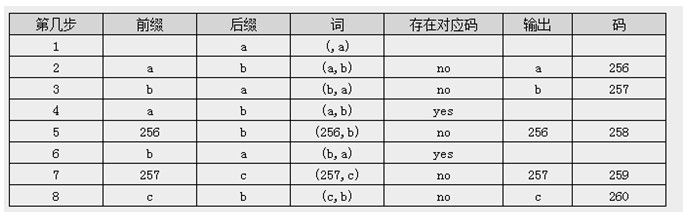
?
?最后输出的是:a,b,256,257,c?? 压缩玩了以后就可以将字典扔掉,在解压的时候重新建立字典。
解压:
由于压缩的独特方法,那么解压时也有自己独特的解压方法,关键是:每一步都可以创建一个Dictionary类,这是由于压缩时方法决定的即:每次发现不认识的节点是就创建一个字典类,同时将前缀写进文件中。在解压的时候,每次读取的字符其实都是压缩时不认识后在创建新的字典类的同时也操作写进文件的这个动作的。例如读取了258,其实此次不仅可以先从字典中找出258对应的首个字符(只需知道首个,此规律可以总结出来),完善碎裂的最后元素的后缀,同时创建新的字典类如262,只是我用的是前缀当然是258,默认后缀为0,再读取下个字节时如256,得到256的首个字符作为将上次创建的262的后缀。实际上每步都可以创建新的字典类。
具体的步骤:

?
?解压:
?
//节点类public class LzwNode {
// 前缀
int prefix;
// 后缀
int suffix;
public LzwNode(int prefix, int suffix) {
this.prefix = prefix;
this.suffix = suffix;
}
// 判断两个节点元素是否相同
public boolean isEqual(LzwNode node) {
boolean state = false;
if (this.prefix == node.prefix) {
if (this.suffix == node.suffix) {
state = true;
}
}
return state;
}
}