(转载)手写压缩软件,超详细解释(哈夫曼实现)
转载自:http://stchou.iteye.com/blog/833232
说到文件压缩大家很容易想到的就是 rar,zip 等我们常见的压缩格式。然而,还有一种就是大家在学习数据结构最常见到的哈夫曼树的数据结构,以前还不知道他又什么用,其实他最大的用途就是用来做压缩,也是一些 rar,zip 压缩的祖先,称为哈弗曼压缩(什么你不知道谁是哈弗曼,也不知道哈弗曼压缩,不急等下介绍)。
?? 随着网络与多媒体技术的兴起,人们需要存储和传输的数据越来越多,数据量越来越大,以前带宽有限的传输网络和容量有限的存储介质难以满足用户的需求。
特别是声音、图像和视频等媒体在人们的日常生活和工作中的地位日益突出,这个问题越发显得严重和迫切。如今,数据压缩技术早已是多媒体领域中的关键技术之一。
Huffman( 哈夫曼 ) 算法在上世纪五十年代初提出来了,它是一种无损压缩方法,在压缩过程中不会丢失信息熵,而且可以证明 Huffman 算法在无损压缩算法中是最优的。 Huffman 原理简单,实现起来也不困难,在现在的主流压缩软件得到了广泛的应用。对应用程序、重要资料等绝对不允许信息丢失的压缩场合, Huffman 算法是非常好的选择。
?
三、哈夫曼编码生成步骤:
① 扫描要压缩的文件,对字符出现的频率进行计算。
② 把字符按出现的频率进行排序,组成一个队列。
③ 把出现频率最低(权值)的两个字符作为叶子节点,它们的权值之和为根节点组成一棵树。
④ 把上面叶子节点的两个字符从队列中移除,并把它们组成的根节点加入到队列。
⑤ 把队列重新进行排序。重复步骤 ③④⑤ 直到队列中只有一个节点为止。
⑥ 把这棵树上的根节点定义为 0 (可自行定义 0 或 1 )左边为 0 ,右边为 1 。这样就可以得到每个叶子节点的哈夫曼编码了。
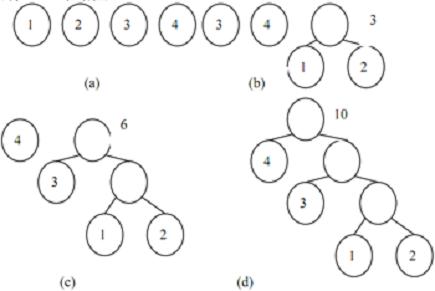
既如?(a) 、 (b) 、 (c) 、 (d) 几个图,就可以将离散型的数据转化为树型的了。
?
如果假设树的左边用0 表示右边用 1 表示,则每一个数可以用一个 01 串表示出来。
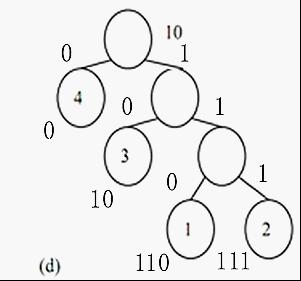
则可以得到对应的编码如下:
1-->110
2-->111
3-->10
4-->0
每一个01 串,既为每一个数字的哈弗曼编码。
为什么能压缩:
压缩的时候当我们遇到了文本中的1 、 2 、 3 、 4 几个字符的时候,我们不用原来的存储,而是转化为用它们的 01 串来存储不久是能减小了空间占用了吗。(什么 01 串不是比原来的字符还多了吗?怎么减少?)大家应该知道的,计算机中我们存储一个 int 型数据的时候一般式占用了 2^32-1 个 01 位,因为计算机中所有的数据都是最后转化为二进制位去存储的。所以,想想我们的编码不就是只含有 0 和 1 嘛,因此我们就直接将编码按照计算机的存储规则用位的方法写入进去就能实现压缩了。
比如:
1这个数字,用整数写进计算机硬盘去存储,占用了 2^32-1 个二进制位
??而如果用它的哈弗曼编码去存储,只有110 三个二进制位。
效果显而易见。
?
?
开始写程序:
?
开始些程序之前,必须想好自己的文件存储格式,和存储规则是什么
为了简便,我自定义存储的基本信息,格式如下:
?
?
SaveCode[i].n????int型?? // 每一个字节的编码长度? i:0~256
B yte[]???byte数组型 // 每一个字节的编码 SaveCode[i].node 中 String 的 01 串转化而来。
?Byte[]??byte数组型 // 对文件中每一个 byte 的重新编码的哈夫曼编码写入。
?
有了定义好的格式我们的读写就非常的方便了,
创建步骤:
①读入文件中的所有字节:
- // 创建文件输入流java.io.FileInputStream fis = new java.io.FileInputStream(path);//读入所有的文件字节while(fis.available()>0){int i=fis.read();byteCount[i]++;}?
②构建哈夫曼树:
- /** * 使用优先队列构建哈弗曼树 */ public void createTree(){ //优先队列 PriorityQueue<hfmNode> nodeQueue = new PriorityQueue<hfmNode>(); //把所有的节点都加入到 队列里面去for (int i=0;i<256;i++){if(byteCount[i]!=0){hfmNode node = new hfmNode(i,byteCount[i]);nodeQueue.add(node);//加入节点}}//构建哈弗曼树while(nodeQueue.size()>1) {hfmNode min1 = nodeQueue.poll();//获取队列头hfmNode min2 = nodeQueue.poll();hfmNode result = new hfmNode(0,min1.times+min2.times);result.lChild=min1;result.rChild=min2; nodeQueue.add(result);//加入合并节点 } root=nodeQueue.peek(); //得到根节点}?
这里我采用了优先队列的方法,因为优先队列比较符合哈夫曼的构造方法,形式上也非常的相似。
③取得每一个叶子节点的哈夫曼编码:
- /** * 获得叶子节点的哈弗曼编码 * @param root 根节点 * @param s */ public void getMB(hfmNode root,String s){ if ((root.lChild==null)&&(root.rChild==null)){ Code hc=new Code(); hc.node=s; hc.n=s.length(); System.out.println("节点"+root.data+"编码"+hc.node); SaveCode[root.data]=hc;//保存字节 root.data 的编码 HC } if (root.lChild!=null){//左0 右 1 getMB(root.lChild,s+'0'); } if (root.rChild!=null){ getMB(root.rChild,s+'1'); } }?
如此一来我们的哈夫曼树就建好了。
下面就是按照我们之前定义的文件存储格式直接写进文件就可以了。
压缩文件的写入:
- //写出每一个编码的长度 for (int i=0;i<256;i++){ fos.write(SaveCode[i].n); } ?
这一步较为复杂,因为JAVA 中没有自己定义的二进制为写入,我们就不得不将每 8 个 01?String 转化为一个 byte 再将 byte 写入。但是,问题又来了不是所有的 01String 都是 8 的整数倍,所以就又得在不是 8 整数倍的 String 后面补上 0
- /////写入每一个字节所对应的 String编码int count=0;//记录中转的字符个数int i=0;//第i个字节String writes ="";String tranString="";//中转字符串String waiteString;//保存所转化的所有字符串while((i<256)||(count>=8)){//如果缓冲区的等待写入字符大于8if (count>=8){waiteString="";//清空要转化的的码for (int t=0;t<8;t++){ waiteString=waiteString+writes.charAt(t); }//将writes前八位删掉if (writes.length()>8){ tranString=""; for (int t=8;t<writes.length();t++){ tranString=tranString+writes.charAt(t); } writes=""; writes=tranString; }else{ writes=""; } count=count-8;//写出一个8位的字节 int intw=changeString(waiteString);//得到String转化为int //写入文件 fos.write(intw);}else{//得到地i个字节的编码信息,等待写入count=count+SaveCode[i].n;writes=writes+SaveCode[i].node;i++;}}//把所有编码没有足够8的整数倍的String补0使得足够8的整数倍,再写入if (count>0){waiteString="";//清空要转化的的码for (int t=0;t<8;t++){if (t<writes.length()){waiteString=waiteString+writes.charAt(t);}else{waiteString=waiteString+'0';}}fos.write(changeString(waiteString));//写入System.out.println("写入了->"+waiteString);} /** * 将一个八位的字符串转成一个整数 * @param s * @return */ public int changeString(String s){ return ((int)s.charAt(0)-48)*128+((int)s.charAt(1)-48)*64+((int)s.charAt(2)-48)*32 +((int)s.charAt(3)-48)*16+((int)s.charAt(4)-48)*8+((int)s.charAt(5)-48)*4 +((int)s.charAt(6)-48)*2+((int)s.charAt(7)-48);}?
???这一步也比较复杂,原理同上一步,在SaveCode 中查找一个 byte 所对应的哈夫曼编码,不够 8 的整数倍的就不足,再写入。
???值得注意的事,最后一定要写一个byte 表示,补了多少个 0 方便解压缩时的删除 0
?
- //再次读入文件的信息,对应每一个字节写入编码count=0;writes ="";tranString="";int idata=fis.read();//文件没有读完的时候while ((fis.available()>0)||(count>=8)){//如果缓冲区的等待写入字符大于8if (count>=8){waiteString="";//清空要转化的的码for (int t=0;t<8;t++){ waiteString=waiteString+writes.charAt(t); } //将writes前八位删掉 if (writes.length()>8){ tranString=""; for (int t=8;t<writes.length();t++){ tranString=tranString+writes.charAt(t); } writes=""; writes=tranString; }else{ writes=""; } count=count-8;//写出一个8位的字节 int intw=changeString(waiteString); fos.write(intw);//写到文件中区}else{//读入idata字节,对应编码写出信息count=count+SaveCode[idata].n;writes=writes+SaveCode[idata].node;idata=fis.read();}}count=count+SaveCode[idata].n;writes=writes+SaveCode[idata].node;//把count剩下的写入 int endsint=0; if (count>0){waiteString="";//清空要转化的的码for (int t=0;t<8;t++){if (t<writes.length()){waiteString=waiteString+writes.charAt(t);}else{waiteString=waiteString+'0';endsint++;}}fos.write(changeString(waiteString));//写入所补的0?
如此一来,整个的压缩过程就完毕了。
?
解压缩过程:
??? 与压缩过程刚好是反着来进行的,知道的存储的方式我们就反着来读取看看。
?
- //读入文件中的每一个编码的长度 for (int i=0;i<256;i++){ Code hC=new Code(); hC.n=fis.read(); hC.node=""; SaveCode[i]=hC; }?
- int i=0; int count=0; String coms=""; //读SaveCode中0~256字节的的数据 while (i<256){ //当缓存区的编码长度比编码[i]的长度长的时候 if (coms.length()>=SaveCode[i].n){ for (int t=0;t<SaveCode[i].n;t++){//SaveCode[i].node取得该编码 SaveCode[i].node=SaveCode[i].node+coms.charAt(t); } //把coms前这几位去掉 String coms2=""; for (int t=SaveCode[i].n;t<coms.length();t++){ coms2=coms2+coms.charAt(t); } coms=""; coms=coms2;//累计的下一个编码,继续的使用 i++; }else{ //如果已经没有写出的话,再度入一个byte转化为01 String coms=coms+IntToString(fis.read()); } }?
得注意的事,前面我们又补0 的位,所以在我们读取的时候,记得把之前所补得东西,给删除掉就 OK 了。
- String?rsrg;