MySql无限分类结构
无限分类是我们开发中非常常见的应用,像论坛的的版块,CMS的类别,应用的地方特别多。
我们最常见最简单的方法就是在MySql里ID ,parentID,name:
优点是简单,结构简单。
缺点是效率不高,因为每一次递归都要查询数据库,几百条数据库时就不是很快了!
存储树是一种常见的问题,多种解决方案。主要有两种方法:邻接表的模型,并修改树前序遍历算法。
我们将探讨这两种方法的节能等级的数据。我会使用树从一个虚构的网上食品商店作为一个例子。这食品商店组织其食品类,通过颜色和类型。这棵树看起来像这样: 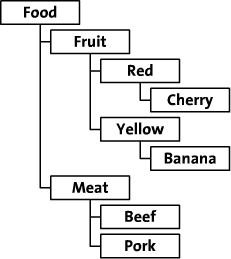
下面我们将用另外一种方法,这就是预排序遍历树算法(modified?preorder?tree?traversal?algorithm)?
这种方法大家可能接触的比较少,初次使用也不像上面的方法容易理解,但是由于这种方法不使用递归查询算法,有更高的查询效率。
我们首先将多级数据按照下面的方式画在纸上,在根节点Food的左侧写上?1?然后沿着这个树继续向下?在?Fruit?的左侧写上?2?然后继续前进,沿着整个树的边缘给每一个节点都标上左侧和右侧的数字。最后一个数字是标在Food?右侧的?18。?在下面的这张图中你可以看到整个标好了数字的多级结构。(没有看懂?用你的手指指着数字从1数到18就明白怎么回事了。还不明白,再数一遍,注意移动你的手指)。?
这些数字标明了各个节点之间的关系,"Red"的号是3和6,它是?"Food"?1-18?的子孙节点。?同样,我们可以看到?所有左值大于2和右值小于11的节点?都是"Fruit"?2-11?的子孙节点?
如图所示: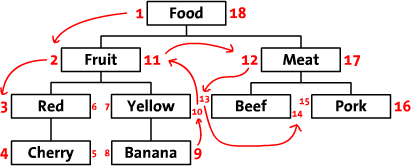
这样整个树状结构可以通过左右值来存储到数据库中。继续之前,我们看一看下面整理过的数据表。?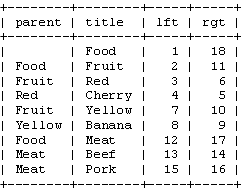
注意:由于"left"和"right"在?SQL中有特殊的意义,所以我们需要用"lft"和"rgt"来表示左右字段。?另外这种结构中不再需要"parent"字段来表示树状结构。也就是?说下面这样的表结构就足够了。?
SELECT * FROM tree WHERE lft BETWEEN 2 AND 11;
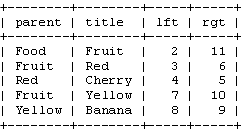
看到了吧,只要一个查询就可以得到所有这些节点。为了能够像上面的递归函数那样显示整个树状结构,我们还需要对这样的查询进行排序。用节点的左值进行排序:?
SELECT * FROM tree WHERE lft BETWEEN 2 AND 11 ORDER BY lft ASC;
那么某个节点到底有多少子孙节点呢?很简单,子孙总数=(右值-左值-1)/2?
descendants?=?(right?–?left?-?1)?/?2?,如果不是很清楚这个公式,那就去翻下书,我们在上数据结构写的很清楚!
添加同一层次的节点的方法如下:
<?php function display_tree($root) { // retrieve the left and right value of the $root node $result = mysql_query('SELECT lft, rgt FROM tree '. 'WHERE title="'.$root.'";'); $row = mysql_fetch_array($result); // start with an empty $right stack $right = array(); // now, retrieve all descendants of the $root node $result = mysql_query('SELECT title, lft, rgt FROM tree '. 'WHERE lft BETWEEN '.$row['lft'].' AND '. $row['rgt'].' ORDER BY lft ASC;'); // display each row while ($row = mysql_fetch_array($result)) { // only check stack if there is one if (count($right)>0) { // check if we should remove a node from the stack while ($right[count($right)-1]<$row['rgt']) { array_pop($right); } } // display indented node title echo str_repeat(' ',count($right)).$row['title']."\n"; // add this node to the stack $right[] = $row['rgt']; } } ?>8 楼 utyphoon 2008-10-16 是个不错的思路。 9 楼 utom75 2008-10-16 这是B-tree,如果一个node有超过两个以上的子node,这种解决方法不适用了 10 楼 zzm_fly2004 2008-10-16 采用id,parentId结构的树状数据结构,查找一个节点下所有子节点也可以不使用递归方法。可以在表结构中维护一个fullPath字段:根节点到当前节点的ID链。比如:
ROOT(1)
|
|--A(2)
|--C(4)
| |--D(5)
|
|--B(3)
|--E(6)
括弧里面表示节点ID,那么
id parent name fullPath
1 0 ROOT 0-1
2 1 A 0-1-2
3 1 B 0-1-3
4 2 C 0-1-2-4
5 4 D 0-1-2-4-5
6 3 E 0-1-3-6
假设要找A节点C,D下所有的子节点,SQL如下:
select * from table t where t.fullPath like '%2%';
但效率怎样,没有测试过。 11 楼 moonranger 2008-10-16 对于分类这种通常变化不大的数据,用这种方式的确不错,提高了不少效率。但是如果分类变化比较频繁,那很难说效率能高多少,因为对分类进行改变时太麻烦,效率不高。 12 楼 waterdh 2008-10-16 我觉得比较好的方法是初始化的时候,全部装载到内存里。以后的更新删除等操作,同步内存和数据库。
数据结构:
class Tree{
int treeId;
String treeName;
Tree parent;
List<Tree> sons;
.
.
other useful field;
}
根据需要使用HashMap作treeId ->Tree和treeName->Tree的映射索引。
这样增加和删除节点,更新下parent和sons,删除或更新数据库记录。
速度相当快。
13 楼 east_java 2008-10-16 呵呵..这个不错..
我一直用这种方式处理树形结构.
但如果加上Composite模式,就更好了.. 14 楼 xly_971223 2008-10-16 不错 但不太实用 插入 删除略显复杂 15 楼 SeanHe 2008-10-17 zzm_fly2004 写道
采用id,parentId结构的树状数据结构,查找一个节点下所有子节点也可以不使用递归方法。可以在表结构中维护一个fullPath字段:根节点到当前节点的ID链。比如: ROOT(1) | |--A(2) |--C(4) | |--D(5) | |--B(3) |--E(6) 括弧里面表示节点ID,那么 id parent name fullPath 1 0 ROOT 0-1 2 1 A 0-1-2 3 1 B 0-1-3 4 2 C 0-1-2-4 5 4 D 0-1-2-4-5 6 3 E 0-1-3-6 假设要找A节点C,D下所有的子节点,SQL如下: select * from table t where t.fullPath like '%2%'; 但效率怎样,没有测试过。
你的fullpath应该这么写0-1-2- ,查这一级的子节点应该用like '0-1-2-%',不然会吧0-1-21也当成0-1-2的下级了 16 楼 lijie250 2008-10-17 utom75 写道
这是B-tree,如果一个node有超过两个以上的子node,这种解决方法不适用了
可以多个子节点的,你按照上面的方法试就知道了! 17 楼 danielking 2008-10-17 貌似和rails里的betternestedset插件类似 18 楼 beyondqinghua 2008-10-17 这种方式太麻烦了,还不如用二进制相与来处理
0000 0000 0000 0000 0000 0000 。。。
一般来说一个64位的就足够你分了
第一级有2的四次方,如果觉得不够可以再多分几位,如果要查找第二级为哪个的子菜单只要与0000 1111 相与就是了,而且数据库本身就支持这种运算,所以非常方便,效率就更不用说了。唯一的麻烦就是要写个算法删除菜单后如何重新利用的问题!
19 楼 beyondqinghua 2008-10-17 beyondqinghua 写道
这种方式太麻烦了,还不如用二进制相与来处理 0000 0000 0000 0000 0000 0000 。。。 一般来说一个64位的就足够你分了 第一级有2的四次方,如果觉得不够可以再多分几位,如果要查找第二级为哪个的子菜单只要与0000 1111 相与就是了,而且数据库本身就支持这种运算,所以非常方便,效率就更不用说了。唯一的麻烦就是要写个算法删除菜单后如何重新利用的问题!
如果了解子网的算法那么这就很容易理解了。 20 楼 liudaoru 2008-10-18 呵呵,翻译的不错,不过最好把别人的文章链接放在前面,尊重别人的劳动成果:) 21 楼 lqixv 2008-12-10 查询还行,但每添加或删除一条数据的时候,就必须把所有的数据全部更新一遍,代价也很大。 22 楼 lijie250 2008-12-14 lqixv 写道
查询还行,但每添加或删除一条数据的时候,就必须把所有的数据全部更新一遍,代价也很大。
这个就要看需求了,我准备是用在CMS上,一般更改不大,主要想在查询方面效率高! 23 楼 thxg 2010-03-04 算法有点意思,不过处理确实有些复杂,可能是第一次看到这样处理树目录有些陌生。
我一般用parentId加逐级累加的字符串来处理,跨级查询子目录时用 like 'xxx-xxx-*'。like效率差些,但想着百分号在后面,或许还将就吧。