深入理解JVM--类的执行机制
?
在完成将class文件信息加载到JVM并产生class对象之后,就可以执行Class对象的静态方法或者实例方法对对象进行调用了。JVM在源代码编译阶段将源代码编译为字节码文件,字节码是一种中间代码的方式,要由JVM在运行时进行解释执行,这种方式称之为解释执行方式。
1、字节码的解释执行
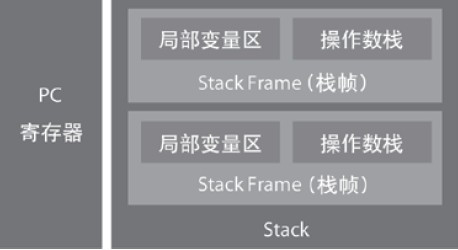
SunJDK是基于栈的体系结构来执行字节码的,基于栈的好处是代码紧凑,体积小。每个线程创建之后,都会产生一个程序计数器(又称PC计数器)和栈,栈中存在若干的栈帧,每个方法的调用都会产生栈帧。栈帧主要包含两部分,局部变量和操作数栈,局部变量用户存放方法中的局部变量和参数,操作数栈用户存放方法中性过程中产生的中间结果,栈帧中还会有一些杂用的空间,用于存放指向方法已解析的常量池的引用,一些JVM内部所需要的数据等。如下图所示
?
?
?1)
?????????指令解释执行
?
方法的指令执行是经典的冯诺依曼体系中饿FDX的循环方式,即取一条指令,然后分派,执行。
如下面的代码
???????while(true){
???????????int?code=fetchNextCode();
???????????switch(code){
???????????case?IADD:
??????????????// do add
???????????case?…:
??????????????// do?sth.
???????????}
???????}
以上程序很简单的满足了我们的需求,也是FDX循环模式一个很简单的实现,但是这段程序每次执行完毕都会回到程序的原点,重新判断重新执行,效率是比较差的,所以,有人提出了一种叫token-threding的方式,使用令牌来进行处理,如下面的代码
????IADD:{
???????// do add;
???????fetchNextCode();
???????dispatch();
????}
????ICONST_0:{
???????//do?sth
???????fetchNextCode();
???????dispatch();
?
}
???????这段代码冗余了fetchNextCode和dispatch两条指令,性能相对会好一些(为什么性能会好?详情请参看博文JAVA类的执行机制)但是使用这种方法由于冗余相关指令,因此占用的内存会大一些。
2)?????????栈顶缓存
在方法执行过程中,可以看到有很多重要的操作将数据放入到操作数栈,这会导致寄存器和内存要不断的进行交换数据,SunJDK采用可栈顶缓存,即将本来位于操作数栈的值直接缓存在寄存器上,这样对于大部分只需要一个操作数的操作而言,无需将数据放入操作数栈,可直接在寄存器上进行计算,然后放回操作数栈。
3)?????????部分栈帧共享
当一个方法调用另外一个方法的时候,通常会传入另一个方法的参数存放在操作数栈,SunJDK为此做了一个优化,就是当调用方法时,后一方可以将前一方的操作数栈作为当前方法的局部变量,从而节省数据copy带来的损耗。
当然SunJDK为了提高数据执行的效率,做了很多优化,这里有不一一列举了
2、编译执行
解释执行的效率是很低的,为了提升代码编译的执行性能,SunJDK也提供了编译执行的机制(N多教科书上说java是一种结实型语言,都是不全面的,JVM是可以执行编译执行的),编译在运行时进行,通常成为JIT编译器。SunJDK对执行频率高的代码进行编译,而对执行频率不高的代码仍然进行解释执行,因此SunJDK又被称作为HotspotVM,对于编译,SunJDK提供了2种方式,clint complier(-clint)和server complier(-server)。
Clint complier又被成为C1,较为轻量级,只做少量的性能开销比较高的一些优化,占用内存较少,适合做桌面的交互式应用。在寄存器分配策略上,JDK6采用了线性扫描寄存器的方式(具体可参照http://www.bluedavy.com/book/reference/LSRA.pdf),在其他方面的优化主要包括:方法内联、去虚拟化、冗余消除等!
1)?????????方法内联
对于java语言来说,通常需要调用多个方法来完成功能,执行的时候还需要多次传参和返回值传递,因此C1采用了方法内联的方式,把用到的方法直接植入到当前的方法中,示例如下
????????public?void?buy(){
???????saveOrder();
???????saveDetail();
????}
?
????public?void?saveOrder(){
???????//do save saveOrder
????}
?
????public?void?saveDetail(){
???????//do write detail
????}
当编译的时候,发现编译后的buy方法的字节码≤35个字节(这个可以通过JVM启动的时候设置参数-XX:MaxInlineSize=35来进行控制),则该程序会演变成下面的结构!
????public?void?buy(){
???????//do save saveOrder
???????//do write detail
}
2)?????????去虚拟化
去虚拟化是指在状态class文件之后进行层次分析,如果发现类中的方法只提供了一个实现类,那么对于条用了此方法的代码,也就可以通过方法内联来提高性能。
如下列代码
interface?OrderInterface{
??public?void?buy();
}
class?Order?implements?OrderInterface{
?
??@Override
??public?void?buy() {
?????//do buy
??}
}
public?class?Test{
??public?void?testBuy(Order order){
?????order.buy();
??}
当JVM在编译的时候发现buy方法只有一个实现的时候,就演变成以下结构
public?class?Test{
???????public?void?testBuy(Order order){
???????//do buy
???????}
}
3)?????????冗余消除
冗余消除是指在编译时,根据运行时的状况进行代码折叠或削除
如下代码
import?com.sun.org.apache.commons.logging.Log;
import?com.sun.org.apache.commons.logging.LogFactory;
public?class?Test{
???
????private?final?static?Log?log?= LogFactory.getLog(Test.class);
???
????private?final?static?boolean?isDebug?=?log.isDebugEnabled();
???
????public?void?execute(){
???????if(isDebug)
???????????log.debug("Test.execute() has been excuted");
???????//do?sth
????}
}
这段代码在编译的时候如果被监测到isDebug是false,则执行完C1编译之后就变成了如下代码
public?class?Test{
???
????public?void?execute(){
???????//do?sth
????}
}
这也是很多时候优秀的程序员不直接写log.debug而要先写一个判断的原因。
Server complier又称为C2编译,就比较重量级.
转(http://yhjhappy234.blog.163.com)