二次学习(节外生枝篇)一、初探Hadoop(3)在讨论MapReduce计算模型执行过程(框架或者叫运行时系统提供支持)之
二次学习(节外生枝篇)一、初探Hadoop(3)
在讨论MapReduce计算模型执行过程(框架或者叫运行时系统提供支持)之前,我们来看看计算环境。Google的计算环境非常典型,在两位工程师的论文中已经提到:
?
每个节点通常是双X86处理器,运行Linux,每台机器2~4GB内存使用的网络设备都是常用的,一般在节点上使用的是100M或者1000M网络,一般情况下都用不到一半的网络带宽一个Cluster中常常有成百上千台机器,所以,机器故障是常见的存储时使用的是便宜的IDE硬盘,有个分布式文件系统来管理,通过复制的方法在不可靠的硬件上保证可用性和可靠性用户向调度系统提交请求,每一个请求包含了一组任务,映射到cluster中的一组机器上执行?
我们仔细分析这种计算环境,可以看到这样几个特点,集群中的机器很多,但是机器的配置较低,内存有限,硬件很不可靠,网络带宽一般。这些特点将成为设计框架或者运行时环境的约束性输入。
?
来看看这个计算模型的执行过程:
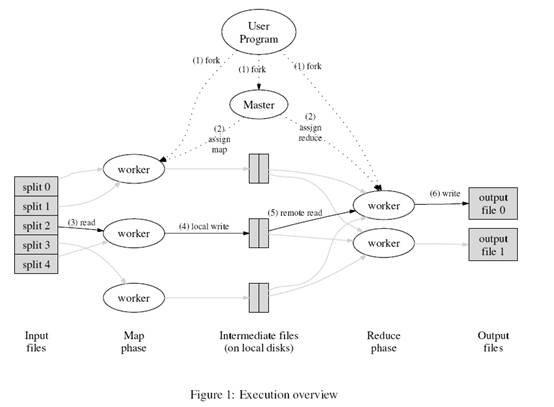
?
?
- 用户调用MapReduce函数库,输入一组文档;Split函数把文件分成M块,每块大概16M到64M(通过参数来设置);在cluster的各个机器上执行处理程序(注意,数据并没有传递);cluster中的某个机器上运行的是master(主控程序,只有一个),其他机器上运行的都是由master指派任务的worker程序。总共有M个map任务和R个reduce任务。从图上看,master在中间位置,负责map和reduce任务的调度,它会把任务指派给相对空闲的worker程序。这里还涉及到Reduce程序的分布,一般来说,它根据中间产生的Key来分布的,并且有个分区函数(比如:hash(key) mod R。但用户可以指定其他的函数)来做这件事,R的数量也是用户指定的;一个分配了map任务的worker程序会读取并处理输入的一小块内容(16M到64M,这时候才会在网络上传递数据)。这个worker程序会从输入的一小块内容中分析出一组键值对,然后交由map函数来产生中间键值对。此时,中间结果是在内存中的;在内存中的中间结果(中间键值对)会定期刷写到本地硬盘,然后再通过分区函数(比如:hash(key) mod R)分成R个区。然后,位置信息被发送回master,master负责把这些位置信息传递给执行reduce任务的worker;在执行reduce任务的worker接收到这些位置信息时,会调用Remote Procedure从map worker的本地硬盘读取数据(中间生成的键值对),然后进行排序(按照中间生成的键),如果中间生成的键值对数据太多(内存不够),可以进行external sort(不太理解,以后补充说明);排序后的中间结果被传递到reduce函数,然后得到一个输出文件(一共有R份);最后把控制权交还用户程序。
最后生成的R份文件通常不需要合并成一份,因为它们通常又会作为另一个mapreduce调用的输入。
?
今天暂写到这里。
?
?
?