Java 序列化的高级认识--序列化反序列化, 加密存储<转>
简介: 文章对序列化进行了更深一步的讨论,用实际的例子代码讲述了序列化的高级认识,包括父类序列化的问题、静态变量问题、transient 关键字的影响、序列化 ID 问题。
将 Java 对象序列化为二进制文件的 Java 序列化技术是 Java 系列技术中一个较为重要的技术点,在大部分情况下,开发人员只需要了解被序列化的类需要实现 Serializable 接口,使用 ObjectInputStream 和 ObjectOutputStream 进行对象的读写。然而在有些情况下,光知道这些还远远不够,文章列举了一些真实情境,它们与 Java 序列化相关,通过分析情境出现的原因,使读者轻松牢记 Java 序列化中的一些高级认识。
Client 端通过 Fa?ade Object 才可以与业务逻辑对象进行交互。而客户端的 Fa?ade Object 不能直接由 Client 生成,而是需要 Server 端生成,然后序列化后通过网络将二进制对象数据传给 Client,Client 负责反序列化得到 Fa?ade 对象。该模式可以使得 Client 端程序的使用需要服务器端的许可,同时 Client 端和服务器端的 Fa?ade Object 类需要保持一致。当服务器端想要进行版本更新时,只要将服务器端的 Fa?ade Object 类的序列化 ID 再次生成,当 Client 端反序列化 Fa?ade Object 就会失败,也就是强制 Client 端从服务器端获取最新程序。
?
?
上图中可以看出,attr1、attr2、attr3、attr5 都不会被序列化,放在父类中的好处在于当有另外一个 Child 类时,attr1、attr2、attr3 依然不会被序列化,不用重复抒写 transient,代码简洁。
?
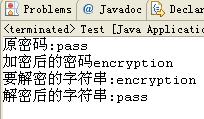
在清单 3 的 writeObject 方法中,对密码进行了加密,在 readObject 中则对 password 进行解密,只有拥有密钥的客户端,才可以正确的解析出密码,确保了数据的安全。执行清单 3 后控制台输出如图 3 所示。
图 3. 数据加密演示
?
特性使用案例
RMI 技术是完全基于 Java 序列化技术的,服务器端接口调用所需要的参数对象来至于客户端,它们通过网络相互传输。这就涉及 RMI 的安全传输的问题。一些敏感的字段,如用户名密码(用户登录时需要对密码进行传输),我们希望对其进行加密,这时,就可以采用本节介绍的方法在客户端对密码进行加密,服务器端进行解密,确保数据传输的安全性。
我们看到,第二次写入对象时文件只增加了 5 字节,并且两个对象是相等的,这是为什么呢?
解答:Java 序列化机制为了节省磁盘空间,具有特定的存储规则,当写入文件的为同一对象时,并不会再将对象的内容进行存储,而只是再次存储一份引用,上面增加的 5 字节的存储空间就是新增引用和一些控制信息的空间。反序列化时,恢复引用关系,使得清单 3 中的 t1 和 t2 指向唯一的对象,二者相等,输出 true。该存储规则极大的节省了存储空间。
特性案例分析
查看清单 5 的代码。
清单 5. 案例代码
ObjectOutputStream out = new ObjectOutputStream(new FileOutputStream("result.obj"));Test test = new Test();test.i = 1;out.writeObject(test);out.flush();test.i = 2;out.writeObject(test);out.close();ObjectInputStream oin = new ObjectInputStream(new FileInputStream("result.obj"));Test t1 = (Test) oin.readObject();Test t2 = (Test) oin.readObject();System.out.println(t1.i);System.out.println(t2.i);?
清单 4 的目的是希望将 test 对象两次保存到 result.obj 文件中,写入一次以后修改对象属性值再次保存第二次,然后从 result.obj 中再依次读出两个对象,输出这两个对象的 i 属性值。案例代码的目的原本是希望一次性传输对象修改前后的状态。
结果两个输出的都是 1, 原因就是第一次写入对象以后,第二次再试图写的时候,虚拟机根据引用关系知道已经有一个相同对象已经写入文件,因此只保存第二次写的引用,所以读取时,都是第一次保存的对象。读者在使用一个文件多次 writeObject 需要特别注意这个问题。