《unix systems for modern architectures》 笔记---SMP和锁(二)
该部分笔记记录SMP下使用自旋锁实现的内核和使用信号量实现的内核,区别于主从处理器设计,实现的是所有core均能运行在内核态的设计。一.采用自旋锁的内核
SMP系统要求运行于不同处理器上的不同进程可以同时发生系统调用,这样的一种内核实现允许一次执行内核活动的多条线索,因为称为多线程内核(multithreaded kernel),要让操作系统成为多线程,就必须以某种方式标识和保护所有的临界区,自旋锁就是一种能够提供这种保护的机制。
在使用自旋锁的时候,必须决定锁的粒度(granularity)。锁的粒度是指使用了多少个自旋锁,以及任何一个锁保护多少数据。
粗粒度的实现仅仅使用几个锁,每个锁保护内核的很大一部分,或者干脆就是一个完整的子系统。
细粒度的实现使用很多的锁,其中一些可能只保护一个数据结构元素。
是使用粗粒度锁还是细粒度锁,要在时间和空间两个方面进行权衡。
1.巨型上锁采用巨型锁,最简单的内核实现就是只使用一个锁的内核。在这种极端情况下,锁保护着所有内核数据,防止一个以上的进程同时以内核态执行。
因为中断可能分配到任何的core中,因此中断处理程序也必须获得内核巨型锁。在上面讲过中断中获取锁导致的死锁情况,所以占有内核巨型锁的处理器上必须屏蔽所有的中断。
巨型上锁技术类似于主从处理机内核。但是采用巨型锁的内核,任何处理器都执行内核代码,从而没有必要把现场切换到主处理器上。巨型锁的内核性能可能比主从处理机内核更差。如果一个进程执行一个系统调用时,另外一个处理器却占据着内核所,那么产生系统调用的处理器会进入空闲,同时自旋等待该所。在主从处理器内核中,core可以选择另外一个用户态进程来执行,而不是空等待。
从巨型锁的方式来看,需要细化锁。一方面可以通过spin_trylock来进行获得自旋锁的尝试。如果没有获得内核锁,就进行现场切换,切换到另外一个用户态进程,而不是等待内核锁。基于要细化锁的目的,下面分析哪些场合不需要要使用锁。
2.不需要上锁的多线程情况让一个内核多线程化的第一步就是确定出那些没有必要用到上锁机制的实例。
1. 每个unix进程都有一个用户区(user area,U区,从下面内容看应该是task_struct中),它是包含一个进程大部分私有数据的内核数据结构。它包含诸如当前信号处理程序(signal handler)设置,当前系统调用的参数、寄存器保护区以及其他私有的数据,因此当进程从自己的U区读取数据或者写时,不需要上锁。
2. 进程的内核栈(kernel stack)。每个进程都有它自己的内核栈,这个不需要上锁。
3. 为某些系统调用分配的额外的空间,这是为了防止所需要的数据比内核栈大的原因。比如exec的参数列表,文件路径名等。
3.细粒度上锁在前面讲到MP与UP上锁的策略问题时分析到三种情况下的上锁,下面对SMP下说明。
3.1.中断互斥对于SMP的中断上锁,前面说过,再有spin_lock_irqsave的情况下是能保证互斥的。
Spin_lock_irqsave是禁止本地中断,如果中断在其他core上发生,由于自旋锁spin_lock的存在,其他core上的中断处理程序中会获取不到锁而自旋,直到另外一个核中释放。这样存在的问题就是性能问题而已。
3.2.短期互斥在前面说过UP下,短期互斥在禁止抢占的情况下能保证互互斥。而在SMP下,
多存在多线程的情况下,如果使用自旋锁就能解决短期互斥的问题。这里的自旋锁和UP下的不同在于,在获取自旋锁时是需要锁住总线的,xchg原子操作就是用在此功能上。
3.3.长期互斥在前面UP那部分说过,MP系统下,以原有的sleep和wakeup函数实现的长期互斥也不能解决所有的正常工作问题。如果MP体系上两个进程同时检测到资源被释放,目前无进程在使用,则此二个进程均能获取到资源,从而违反了互斥的原则。
SMP上如何解决这个问题,其实是短期互斥锁在长期互斥上的一个应用。在确定临界资源为锁资源之后,在长期互斥中使用短期互斥,保护锁资源,从而就能够保证在长期互斥上也不会出现两个进程同时均能获取到资源的情况。
可以看看mutex_lock的代码,在__mutex_lock_common函数中,对锁资源的保护是通过spin_lock_mutex来进行保护的。
3.4.内核抢占为了让多线程内核实现能在一个MP系统上正确的运转,必须使用自旋锁对需要短期互斥的所有情况加以保护。因为短期互斥现在是显式的,只要一个进程没有占有自旋锁,也没有屏蔽中断,那么它就没有在一段临界区内执行,因此是可以被抢占的。当某个内核进程在这些情况下被抢占时,要保证该进程当时只在访问私有数据。例如,这项措施在实时系统上有用处,因为它能在可以运行优先级更高的进程时降低执行延迟。
4.进程颠簸与sleep/wakeupwakeup函数能够让所有正在相应事件上睡眠的进程被唤醒和运行。在多个进程等待一个锁的情况下,锁资源被其中一个高优先级的进程锁占有,而其他被唤醒的进程在运行时发现锁处于忙的状态,从而再度进入休眠(进程颠簸)。因为UP确保一次只运行一个进程,而且在不支持抢占的情况下,有可能在现场切换前释放锁,避免颠簸。
但是在SMP下,唤醒的进程有可能被分配到另一个core中运行,从而无法避免颠簸。
这样,我们就需要在唤醒时,指定wakeup某个进程,但是在一些场合,需要唤醒所有进程,则无可避免此种场景。比如一个管道多写者单读者的情形,就需要唤醒所有写者进行写,因为不能保证被挑中的第一个写者能将管道FIFO写满,需要唤醒所有的写操作者。因此需要具体问题具体分析。
linux中其实有这样的机制,比如complete函数调用的wake_up_process使用的就是唤醒指定线程的情况,而工作队列中的唤醒wake_up_common则是遍历所有等待事件的进程,逐一唤醒。
二.采用信号量的内核 1.信号量
区别于sleep/wakeup的局限性,信号量是更为高级的操作,它让阻塞的决定和阻塞进程的动作都是一项原子操作。
信号量的功能可以分为信号量的互斥,信号量的同步,以及信号量分配资源。
前两种无需说明,而信号量分配资源简单的就是用信号量控制一个有限资源库内资源的分配,比如一些缓冲区组成的库,就可以用信号量进行管理,在释放一块缓冲区时是V操作,申请一块如果成功则是P操作,如果没成功,则阻塞。
在应用于分配资源时,有可能导致死锁。比如一个库中有4份资源,两个进程同时进行申请3份资源,在二者均获取到2分资源时,再获取第三份资源是死锁。
Banker’s algorithm就能解决这种问题,其实很简单,在申请资源时不按照一份一份进行分配,而是根据全有全无的方式进行分配,这样就能防止此种死锁情况。
在前面时讲过,长期互斥保护资源时,在切换进程状态时要将进程状态从running设置为blocked状态。在SMP切换现场选择新进程运行时,需要检查进程的状态,如果为running,那么则意味着有其他进程还在保存该进程的现场状态,需要等待进程保存完现场,状态为blocked之后,在另一个core上才能开始运行。原因见下面的分析。

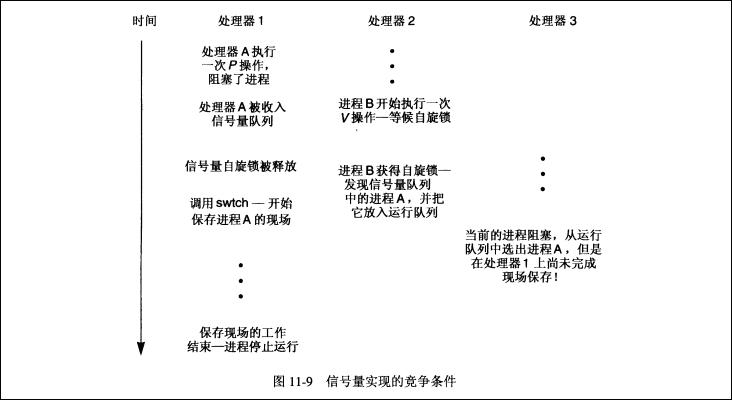
2.采用信号量实现的多线程 2.1.长期互斥
信号量很容易实现长期互斥,在linux中也是借用spin_lock_irqsave实现的。好处就在与,使用信号量的长期互斥,不存在sleep/wakeup的问题,因为信号量的唤醒时按照FIFO的次序进行唤醒的,从而使得连续出现的新进程不能妨碍等待中的进程获得锁。
代码中可以看到如下实例,
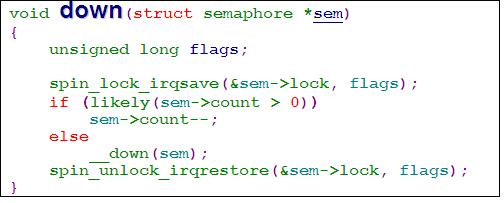
信号量的唤醒时按照FIFO的次序进行唤醒的,因此不存在进程颠簸的问题。
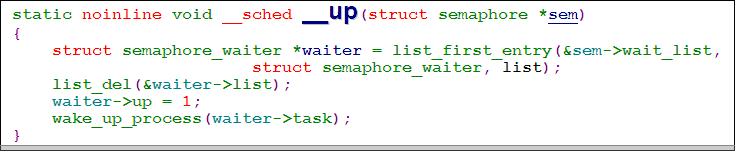
2.2.短期互斥和中断
短期和中断互斥使用信号量不太合适,最好使用自旋锁。
3.性能考虑和结对当一个持续的进程队列在等待一个二值信号量的时候,就发生了进程的结对(convoy),简单的说就是等待信号量的进程过多,导致系统性能差。典型的结对可以看以下例子,
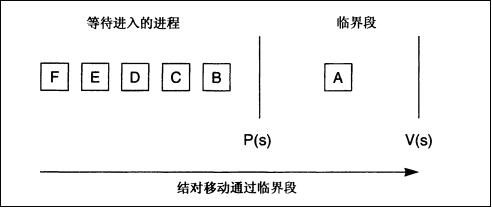
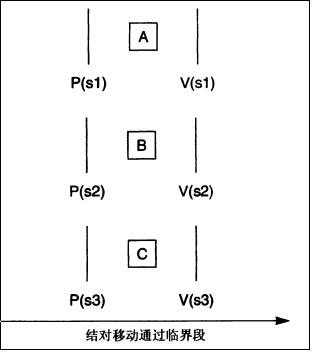
就是说,有多个进程在队列中等待一个资源。如何解决这种问题呢?首先想到的就是锁的细化,这里是信号量资源的细化,将一个信号量资源细化成两个资源,会出现下述情形,
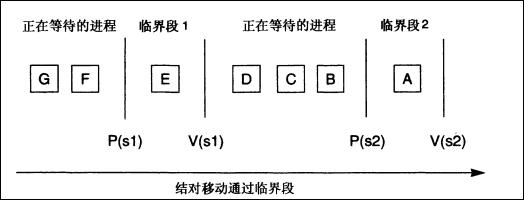
虽然这种方式能够缓解结对现象,但是不能消除。
消除结对的途径是将代码并行化,以便多个进程能够在单个临界区内执行。这个在各个进程和文件系统中有较大的应用。
针对结对的这种情况,导致多读锁的出现。在有些情况下,通过允许多个只读取不
同数据结构的进程并发执行读操作,就能让临界段并行化。只要没有进程修改任何数据结构,就不会出现竞争。当某个进程确实需要进行修改的时候,它可以通过等候读进程结束,然后以互斥的方式对数据进行修改。这样的上锁机制就是多读-单写锁。
多读单写锁在一个写方希望获得锁的时候,必须等待所有使用锁的进程都离开临界区为止。释放一个由写方占用的多读锁时最为复杂的操作。为了公平性,在读方和写方都在等待锁的时候,首先会唤醒多个读方。这就防止在锁上出现连续不断的写方,不让读方进入临界区。这样,当两种类型的进程在等候锁的时候,锁就会在读和写之间轮流。