SQL Server 索引基础知识(2)----聚集索引,非聚集索引 (转合)
? 之前做过一次试验,当所建立的索引没有在where条件中应用时,查询结果需要40多分钟;而建对索引时,不到30秒,很神奇吧,这就是索引的作用,他就像目录一样,可以轻松的找到你想要的数据,就像字典,如果没有目录,可想其查询的难度。
?
??? 在总结索引设计的原则时,我们有必要来阐述SQLSERVER中索引的四种类型:
?
1.聚集索引(Cluster Index)
??? 聚集索引中索引存储的值的顺序和表中的数据的物理存储顺序是完全一致的。建立索引时,系统将对表的物理数据页中的数据按列进行排序,然后再重新存储到磁盘上,即聚集索引与数据是混为一体的,它的叶节点中存储的是实际的数据。特点如下:
??? 建立聚集索引后,更新索引列数据,往往会导致表中物理记录的存储顺序的变化,维护的代价会比较大,对于需要经常更新的列,不宜建立聚集索引。
?
2.非聚集索引(Non-Cluster Index)
??? 非聚集索引存储的数据顺序一般和表的物理数据的存储不同。尽管查询速度慢一些,但是维护的代价小。而且表中最多可以建立249个非聚集索引以满足多种查询的需要。
?
3.惟一索引(Unique Index)
??? 惟一索引是指索引存储的值必须是惟一的,不允许两行具有相同的索引值(包括NULL)。主码索引时当然的惟一索引。
?
4.复合索引
??? 复合索引是指利用表中的多个列值的组合来构建索引值。SQLServer 2000规定复合索引最多使用16个列的值进行组合,索引列值最大长度不能超过900字节,而且这些列必须在同一个数据表中。
?
??? 而合理的索引设计是要建立在对各种查询的分析和预测上,我们可以按照如下原则建立索引,希望对软件开发相关人员有所帮助:
索引中的数据尽可能少,即窄索引更容易被选择; 聚集索引码要被包含在表的所有的非聚集索引中,所以聚集索引码要尽可能短; 建立高选择性的非聚集索引; 频繁请求的列上不能建立聚集索引,应该建立非聚集索引,并且要尽可能使值惟一; 尽可能减少热点数据。如果频繁地对表中的某些数据进行读和写,这些数据就是热点数据,要想办法将热点数据分散; 监控磁盘的数据流量。如果利用率太高,就要考虑索引列并在多个磁盘上分布数据以减少I/O; 在至少有一个索引的表中,应该有一个聚集索引。包括的不同值的个数有限,返回一定范围内值的列,查询时返回大量结果的列考虑建立聚集索引; 分析经常使用的SQL语句的Where子句,得出经常取值的数据,考虑对这些数据列根据常见的查询类型建立索引; 主码如果涉及多个数据列,要将显著变化的数据列放在首位。如果数据列的变化程度相当,将经常访问的数据列放在首位; 有大量重复值、且经常有范围查询。如(between,>,<,>=,<=)、order by、group by发生的列,可考虑建立聚集索引; SQL查询语句同时存取多列的数据,且每列都含有重复值,可以考虑建立覆盖索引,覆盖索引要尽量使关键查询形成索引覆盖,其前导列一定是使用最频繁的列; 索引值较短的索引具有比较高的效率,因为每个索引页上能存放较多的索引行,而且索引的级别也比较少。所以,缓存中能防止更多的索引列,这样也减少了I/O操作; 表上的索引过多会影响UPDATE、INSERT和DELETE的性能,因为所有的索引必须做响应的调整。另外,所有的分页操作都被记录在日志中,这样也会增加I/O操作; 一般不对经常被更新的列建立聚集索引,这样会引起整行的移动,严重影响性能; 查询很少或着数据很少的数据表一般不用建立索引; 与ORDER BY或GROUP BY一起使用的列一般使用建立聚集索引。如果ORDER BY 命令中用到的列上有聚集索引,就不会生成1个临时表,因为行已经排序。GROUP BY命令则一定产生1个临时表; 当有大量的行正在被插入表中时,要避免在本表一个自然增长(例如Identity列)的列上建立聚集索引。如果建立了聚集索引,那么INSERT的性能就会大大降低,因为每个插入的行必须到表的最后一个数据页面。?
由于需要给同事培训数据库的索引知识,就收集整理了这个系列的博客。发表在这里,也是对索引知识的一个总结回顾吧。通过总结,我发现自己以前很多很模糊的概念都清晰了很多。
不论是 聚集索引,还是非聚集索引,都是用B+树来实现的。我们在了解这两种索引之前,需要先了解B+树。如果你对B树不了解的话,建议参看以下几篇文章:
BTree,B-Tree,B+Tree,B*Tree都是什么
http://blog.csdn.net/manesking/archive/2007/02/09/1505979.aspx
B+ 树的结构图:

B+ 树的特点:
所有关键字都出现在叶子结点的链表中(稠密索引),且链表中的关键字恰好是有序的; 不可能在非叶子结点命中; 非叶子结点相当于是叶子结点的索引(稀疏索引),叶子结点相当于是存储(关键字)数据的数据层;B+ 树中增加一个数据,或者删除一个数据,需要分多种情况处理,比较复杂,这里就不详述这个内容了。?
聚集索引(Clustered Index)
下面是两副简单描述聚集索引的示意图:?
在聚集索引中执行下面语句的的过程:
select * from table where firstName = 'Ota'
?
一个比较抽象点的聚集索引图示:

?
非聚集索引 (Unclustered Index)??
非聚集索引的页,不是数据,而是指向数据页的页。 若未指定索引类型,则默认为非聚集索引 叶节点页的次序和表的物理存储次序不同 每个表最多可以有249个非聚集索引 在非聚集索引创建之前创建聚集索引(否则会引发索引重建)在非聚集索引中执行下面语句的的过程:
select * from employee where lname = 'Green'

一个比较抽象点的非聚集索引图示:
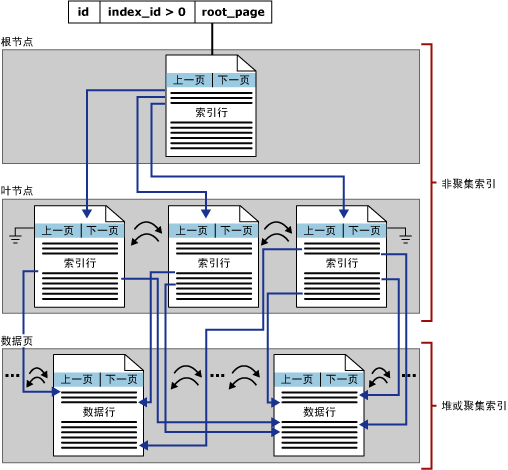
?
什么是 Bookmark Lookup
虽然SQL 2005 中已经不在提? Bookmark Lookup 了(换汤不换药),但是我们的很多搜索都是用的这样的搜索过程,如下:
先在非聚集中找,然后再在聚集索引中找。
 ?
?
在 http://www.sqlskills.com/ 提供的一个例子中,就给我们演示了 Bookmark Lookup? 比 Table Scan 慢的情况,例子的脚本如下:
USE CREDITgo-- These samples use the Credit database. You can download and restore the-- credit database from here:-- http://www.sqlskills.com/resources/conferences/CreditBackup80.zip-- NOTE: This is a SQL Server 2000 backup and MANY examples will work on -- SQL Server 2000 in addition to SQL Server 2005.--------------------------------------------- (1) Create two tables which are copies of charge:--------------------------------------------- Create the HEAPSELECT * INTO ChargeHeap FROM Chargego-- Create the CL TableSELECT * INTO ChargeCL FROM ChargegoCREATE CLUSTERED INDEX ChargeCL_CLInd ON ChargeCL (member_no, charge_no)go--------------------------------------------- (2) Add the same non-clustered indexes to BOTH of these tables:--------------------------------------------- Create the NC index on the HEAPCREATE INDEX ChargeHeap_NCInd ON ChargeHeap (Charge_no)go-- Create the NC index on the CL TableCREATE INDEX ChargeCL_NCInd ON ChargeCL (Charge_no)go--------------------------------------------- (3) Begin to query these tables and see what kind of access and I/O returns--------------------------------------------- Get ready for a bit of analysis:SET STATISTICS IO ON-- Turn Graphical Showplan ON (Ctrl+K)-- First, a point query (also, see how a bookmark lookup looks in 2005)SELECT * FROM ChargeHeap WHERE Charge_no = 12345goSELECT * FROM ChargeCL WHERE Charge_no = 12345go-- What if our query is less selective?-- 1000 is .0625% of our data... (1,600,000 million rows)SELECT * FROM ChargeHeap WHERE Charge_no < 1000goSELECT * FROM ChargeCL WHERE Charge_no < 1000go-- What if our query is less selective?-- 16000 is 1% of our data... (1,600,000 million rows)SELECT * FROM ChargeHeap WHERE Charge_no < 16000goSELECT * FROM ChargeCL WHERE Charge_no < 16000go--------------------------------------------- (4) What's the EXACT percentage where the bookmark lookup isn't worth it?--------------------------------------------- What happens here: Table Scan or Bookmark lookup?SELECT * FROM ChargeHeap WHERE Charge_no < 4000goSELECT * FROM ChargeCL WHERE Charge_no < 4000go-- What happens here: Table Scan or Bookmark lookup?SELECT * FROM ChargeHeap WHERE Charge_no < 3000goSELECT * FROM ChargeCL WHERE Charge_no < 3000go-- And - you can narrow it down by trying the middle ground:-- What happens here: Table Scan or Bookmark lookup?SELECT * FROM ChargeHeap WHERE Charge_no < 3500goSELECT * FROM ChargeCL WHERE Charge_no < 3500go-- And again:SELECT * FROM ChargeHeap WHERE Charge_no < 3250goSELECT * FROM ChargeCL WHERE Charge_no < 3250go-- And again:SELECT * FROM ChargeHeap WHERE Charge_no < 3375goSELECT * FROM ChargeCL WHERE Charge_no < 3375go-- Don't worry, I won't make you go through it all :)-- For the Heap Table (in THIS case), the cutoff is: 0.21%SELECT * FROM ChargeHeap WHERE Charge_no < 3383goSELECT * FROM ChargeHeap WHERE Charge_no < 3384go-- For the Clustered Table (in THIS case), the cut-off is: 0.21%SELECT * FROM ChargeCL WHERE Charge_no < 3438SELECT * FROM ChargeCL WHERE Charge_no < 3439go
这个例子也就是 吴家震 在Teched 2007 上的那个演示例子。
小结:
这篇博客只是简单的用几个图表来介绍索引的实现方法:B+数, 聚集索引,非聚集索引,Bookmark Lookup 的信息而已。
参考资料:
表组织和索引组织
?