用HTTP协议写自动化测试时临时跳过验证码用HTTP协议写自动化测试时临时跳过验证码这两天测试了一个问答系
用HTTP协议写自动化测试时临时跳过验证码
用HTTP协议写自动化测试时临时跳过验证码
这两天测试了一个问答系统,由于开发和测试时间比较紧迫,没有时间屏蔽掉验证码
测试的需求是:
1.模拟用户在网站提出大量问题
2.问题的模板从其他同行业网站上抓取
3.调用提问action前必须以管理员身份登录
解决办法:
以下均由自动化脚本实现
1.urllib先请求登录页,脚本提示输入验证码
2.urllib从登录页获取验证码图片的地址
3.urllib请求该图片地址,将图片保存,os.system自动打开图片,
4.raw_input提示测试人员输入验证码
5.urllib提交登录表单(使用刚输入的验证码,放心,由于session没有变,验证码是有效的)
6.完成登录,开始不停调用提交问题的action(从之前抓取保存的问答模板中,每行是一个问题,逐行提交问题)
下面是脚本:
1.管理员登录的脚本
class askAdminLogin(object): '''问答管理员登录''' def __init__(self, username): self.username = username def runcase(self): username = self.username logger.info("管理员登录:") #构建http cookie = cookielib.CookieJar() opener = urllib2.build_opener(urllib2.HTTPCookieProcessor(cookie)) urllib2.install_opener(opener) #构造数据 req = urllib2.Request("http://10.105.20.11:9090/xxxxx/xxx/admin/login.action") req_logger(req) #请求action fp = urllib2.urlopen(req) resp = fp.read() srandimgurl = re.findall('<img src="(.+)" alt="验证码"', resp)[0] req = urllib2.Request("http://10.105.20.11:9090" + srandimgurl) req_logger(req) #请求action fp = urllib2.urlopen(req) resp = fp.read() srandimg = file('srandimg.jpeg', 'wb') srandimg.write(resp) srandimg.close() os.system('srandimg.jpeg') srand = raw_input("请手动输入验证码后按回车") #构造数据 req = urllib2.Request("http://10.105.20.11:9090/xxxxx/xxx/admin/dologin.action") data = urllib.urlencode({"userName":username["LOGINNAME"], #用户名 "password":username["LOGINNAME"].split("@")[0], #密码 "checkcode":srand}) #验证码 req_logger(req, data) #请求action fp = urllib2.urlopen(req, data) resp = fp.read() geturl = fp.geturl() assert '<title>宜人问答管理中心</title>' in resp, "登录未成功, 服务器返回:%s" % resp assert "http://10.105.20.11:9090/xxxxx/xxx/admin/questionView.action" in geturl, "页面跳转不正确:%s" % geturl return opener, cookie
2.发布新知识问答的脚本
class addKnowledge(object): '''发布新知识''' def __init__(self, username): self.username = username def runcase(self): username = self.username logger.info("发布新知识:") dbopra = db_update() sql = 'delete from QA_KNOWLEDGE_TYPE_LINK t' dbopra.set_value(sql) sql = 'delete from QA_KNOWLEDGE t' dbopra.set_value(sql) #构建http lg = askAdminLogin(username) #调用登录功能 opener, cookie = lg.runcase() urllib2.install_opener(opener) req = urllib2.Request("http://10.105.20.11:9090/xxxxx/xxx/admin/showAddKnowledge.action") req_logger(req) fp = urllib2.urlopen(req) resp = fp.read() ktypes = re.findall('<option value="(\d+)"', resp) fpfile = file('paipai.txt', 'r') for eachline in fpfile: alist = eachline.split('\t') ktitle = alist[1] kcontent = alist[2] ktype = random.Random().choice(ktypes) #构造数据 req = urllib2.Request("http://10.105.20.11:9090/xxxxx/xxx/admin/updateKnowledge.action?t=%s" % str(time.time()).split('.')[0]) datapara = (("ktitle", ktitle), ("kcontent", kcontent), ("ktype",ktype)) data = urllib.urlencode(datapara) req_logger(req, data) #请求action fp = urllib2.urlopen(req, data) resp = fp.read() if '添加成功' not in resp: logger.critical('服务器返回不正确:%s' % resp) fpfile.close() return opener, cookie
附图:
1.之前用脚本抓取的一些数据,用于当做问答知识一条条发布

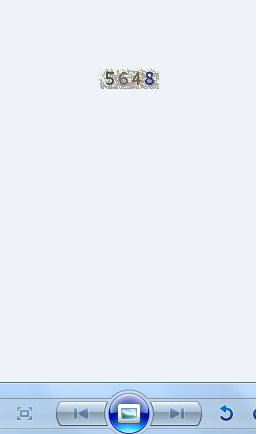
2.每次自动保存的验证码图片
3.脚本运行了不到一分钟后,每个分类都插入了一些问答知识
总结:
这个脚本应该可以更好的理解验证码,浏览器在请求登录页面的时候,其实是先获取了主页返回的HTML,然后加载HTML又自动请求了里面的验证码图片地址,
验证码是服务每次请求时生成的(先生成随机4位数字,再将数字转换成图片),每次生成的随机4位数字会和SESSION进行绑定
在这个SESSION里且不刷新,这个验证码就是有效期的