Apache Hadoop 0.23 HDFS Federation介绍
HDFS Federation
?
?
为了水平扩展命名服务的规模,federation?使用多个Namenode和命名空间代替过去的单个Namenode的模式。多个Namenode被联合在一起提供服务,但是每个Namenode又是独立的,且每个Namenode不需要与其他Namenode协调工作。而Datenode的存储方式还是和过去一样使用块来存储,但每个Datenode需要注册到集群中所有的Namenode上。Datanode周期性的发布心跳、块操作的报告和从Namenode发送来的操作命令的响应。
?
背景
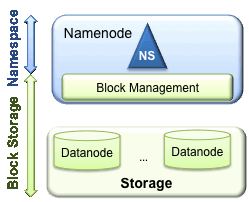
HDFS包括两个层次:
? ? ? ? 1.Namespace
? ? ? ? ? ? ? ? ? 包括目录、文件和blocks
? ? ? ? ? ? ? ? ??HDFS支持所有与namespace相关的操作,包括增删查改,列出文件和目录等操作。
? ? ? ? 2.块(block)存储,也包括两个方面
? ? ? ? ? ? ? ? ? ?块的管理(哪些已经在namenode上记录了)
? ? ? ? ? ? ? ? ? ? ? ? ?HDFS通过注册和心跳机制为hadoop提供一个datanode群组
? ? ? ? ? ? ? ? ? ? ? ? ?处理从datanode上传的块报告,并维护本地的块信息
? ? ? ? ? ? ? ? ? ? ? ? ?提供针对块的操作,例如增删查改和定位一个块的位置。
? ? ? ? ? ? ? ? ? ? ? ? ?管理备份的布局,拷贝要备份的块,删除已经备份的块。
? ? ? ? ? ? ? ? ? ?存储 - ?由datanode提供用来存储块在每个datanode本地文件系统,并且控制读和写的访问权限。
?
目前的HDFS架构只支持一个集群一个namenode,一个单独的namenode管理namespace。HDFS Federation 对现有架构进行修改,一个HDFS系统支持多个namenode。
?
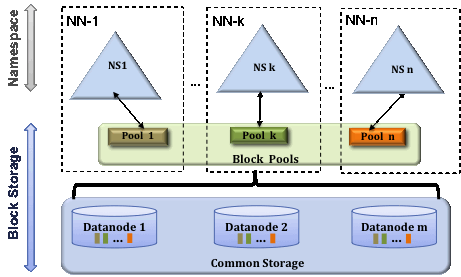
HDFS Federation
?
Block Pool
? ? ? ?一个block pool 是属于一个单独namespace的块的集合。集群中所有Datanode为每个block pool存储所有块。block pool相对于其他block pool来说是独立存在的,相互之间没有影响。这样就允许一个namespace为新生成的块创建Block??ID而不需要与其他namespace沟通协调。一个namenode挂掉并不会影响集群中datanode为其他namenode提供服务。
? ? ? ? 一个namespace和它管理的block pool合称为Namespace Volume。它是一个自给自足的独立系统。当一个Namenode/namespace被删除,在集群全部datanode上与之相关的block pool 将被一起删除。在集群升级的时候每个namespace volume 可以单独的升级。
?
ClusterID
? ? ? ?一个新的标示符ClusterID?被创建,用来识别集群中的每个节点。当一个namenode被格式化,可以手工提供或自动创建一个ClusterID。这个ID可能在集群中其他namenode格式化的时候被用到。
?
核心利益
?
Namespace?扩展性 - HDFS集群存储可以水平的扩展,但是namespace不行。通过增加在集群中的namenode数量来扩展namespace有利于大量的调度任务或者调度大量的小文件。性能 - 文件系统的吞吐量普遍收到单个namenode的制约。为集群增加namenode增加了文件系统的读写操作的吞吐量。隔离性 - 单namenode在多用户环境中没有隔离性可言。一个实验性的项目可以使namenode满负荷运行,从而降低生产环境下得项目的速度。使用多namenode后,不同类别的用户和项目通过不同的namespace被隔离。Federation配置? ? ? Federation配置是向后兼容的,所以你还是可以只配置一个namenode工作而无需做任何配置上的修改。新的配置文件被巧妙的设计后,我们可以在全部的集群节点中只使用一种配置文件而不用管哪些节点是什么类型。? ? ? 在Federation提出了一个新的抽象类NameServiceID?。一个namenode和它对应的secondary / backup?/?checkpointer节点都属于同一个NameServiceID?。为了做到只是用一种配置文件,namenode和secondary / backup / checkpointer的配置参数都要加上NameServiceID?前缀并放在同一个配置文件当中。
配置步骤1.在配置文件中增加以下参数:dfs.federation.nameservices :用逗号分隔NameServiceID。这些NameServiceID将被datanode用来判断在集群中的namenode。2.在通用配置文件中为每个namendoe和Secondary Namenode/BackupNode/Checkpointer 增加以NameServiceID开头的参数值。DaemonConfiguration ParameterNamenodedfs.namenode.rpc-address?dfs.namenode.servicerpc-address?dfs.namenode.http-address?dfs.namenode.https-address?dfs.namenode.keytab.filedfs.namenode.name.dir?dfs.namenode.edits.dir?dfs.namenode.checkpoint.dir?dfs.namenode.checkpoint.edits.dirSecondary Namenodedfs.namenode.secondary.http-address?dfs.secondary.namenode.keytab.fileBackupNodedfs.namenode.backup.address?dfs.secondary.namenode.keytab.file
以下是一份参考配置文件:
<configuration> <property> <name>dfs.federation.nameservices</name> <value>ns1,ns2</value> </property> <property> <name>dfs.namenode.rpc-address.ns1</name> <value>hdfs://nn-host1:rpc-port</value> </property> <property> <name>dfs.namenode.http-address.ns1</name> <value>nn-host1:http-port</value> </property> <property> <name>dfs.namenode.secondaryhttp-address.ns1</name> <value>snn-host1:http-port</value> </property> <property> <name>dfs.namenode.rpc-address.ns2</name> <value>hdfs://nn-host2:rpc-port</value> </property> <property> <name>dfs.namenode.http-address.ns2</name> <value>nn-host2:http-port</value> </property> <property> <name>dfs.namenode.secondaryhttp-address.ns2</name> <value>snn-host2:http-port</value> </property> .... Other common configuration ...</configuration>
格式化namenode:1.使用如下命令格式化namenode:
> $HADOOP_PREFIX_HOME/bin/hdfs namenode -format [-clusterId <cluster_id>]使用一个在你运行环境中不去其他集群机器冲突的唯一cluster_id,如果没有指定,则会自动生成一个唯一ID2.格式化与namenode关联的东西:
> $HADOOP_PREFIX_HOME/bin/hdfs namenode -format -clusterId <cluster_id>第二步的cluster_id 必须与第一步的相同。如果不一致会造成namenode与它的附属物在federated集群中不一致。
关于升级到0.23和配置federation:老版本只支持单个namenode,使用如下步骤开启federation:使用新版本的hadoop,升级过程中可以使用如下命令提供一个ClusterID :
> $HADOOP_PREFIX_HOME/bin/hdfs start namenode --config $HADOOP_CONF_DIR -upgrade -clusterId <cluster_ID>
如果ClusterID 没有指定,则会自动创建一个。
在已有HDFS系统中增加一个namenode:使用如下步骤:1.在配置文件中增加dfs.federation.nameservices参数2.使用NameServiceID 前缀更新以上参数值。配置参数从0.20发布版以后已经改变了。你必须为federation提供一个新的参数名。3.增加与namenode有关的配置项。4.同步配置文件到集群中所有节点。5.启动Namenode,Secondary/Backup。6.使用如下命令刷新datanode去获取新加入的namenode:
> $HADOOP_PREFIX_HOME/bin/hdfs dfadmin -refreshNameNode <datanode_host_name>:<datanode_rpc_port>7.在所有datanode机器上使用上面的命令。
管理集群使用如下命令启动集群:
> $HADOOP_PREFIX_HOME/bin/start-dfs.sh使用如下命令停止集群:
> $HADOOP_PREFIX_HOME/bin/stop-dfs.sh这两个命令可以在集群中所有机器上使用。命令会根据配置文件指定的namenode去启动namenode处理其他的节点。在slaves指定的datanode 会被启动。你可以参考这两个脚本编写自己的启动和停止集群的脚本。BalancerBalancer?已经发生了改变去适应多namenode的架构来均衡集群数据。Balancer 可以使用如下命令启动:
"$HADOOP_PREFIX"/bin/hadoop-daemon.sh --config $HADOOP_CONF_DIR --script "$bin"/hdfs start balancer [-policy <policy>]平衡策略如下:node?- 这是默认策略。均衡器会在datanode层面来均衡数据。这和之前版本的均衡策略很类似。blockpool - 在block pool层次来均衡存储。在blockpool 层次均衡存储和在datanode层面均衡存储都要做。注意均衡只均衡数据,而不会均衡namespace。
Decommissioning卸载和之前版本的方式类似。被卸载的节点需要写在namenode上的exclude file中。每个namenode会卸载自己拥有的block pool。当所有namenode完成了datanode的卸载工作后datanode才被认为是卸载成功的。1.使用如下命令为每个namenode增加一个exclude file:
"$HADOOP_PREFIX"/bin/distributed-exclude.sh <exclude_file>2.刷新所有namenode节点去获取exclude file:
"$HADOOP_PREFIX"/bin/refresh-namenodes.sh以上命令使用HDFS配置来找到所有配置的namenode,然后刷新namenode去获取一份新的exclude file。
集群网页控制台:
相似的namenode控制页面,一个集群控制页面增加到federation 中去监视联合集群,通过URL:http://<any_nn_host:port>/dfsclusterhealth.jsp任何namenode都可以通过以上格式的URL访问到。这个网页提供了如下信息:集群概要:文件数,块数,整个存储容量,集群中可用和已用的存储空间。列出所有namenode和它们包含的文件数、块数、丢失的块数,每个namenode包含的正常和挂掉的datanode数量。还提供一个链接快速的访问到每个namenode节点。也提供被卸载的datanode的状态原文地址:http://hadoop.apache.org/common/docs/r0.23.0/hadoop-yarn/hadoop-yarn-site/Federation.html