HCrawler 项目介绍最近学习了下爬虫,而且有很多开源的基于java的爬虫项目,自己对java有些些兴趣,决定在之
HCrawler 项目介绍
最近学习了下爬虫,而且有很多开源的基于java的爬虫项目,自己对java有些些兴趣,决定在之后的一段时间内写个简单的爬虫,想实现跟Heritrix这样的项目一样的效果确实很难,做个简单的,实现对某个网站上所有资源的下载,保存到本地,便于分析(如Lucene建立索引 来实现搜索引擎等)。
首先确定下需要的东西和大致计划:
HttpClient 4 和 HTMLParser2.0 首先实现单线程的抓取。今明两天争取搞定。 20101224
熬了三天,终于搞了个雏形出来,不过可以开始快速抓取网页了。不过考虑的没有像Heritrix那样周到。界面截图如下: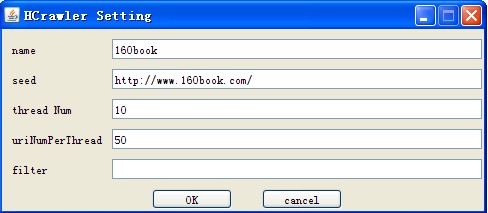
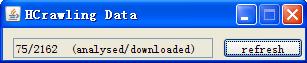
附件中有我的这个的源代码,大概1300行。 20101227