Hadoop The Definitive Guide 2nd Edition 读书笔记5
之前我们学习了MapReduce的执行过程,下面我们看一下MapReduce执行过程中输入和输出所涉及到的数据结构。
输入格式:
通过之前的学习,我们知道在执行mapreduce之前,原始数据被分割成若干split,每个split作为一个map任务的输入,在map执行过程中split会被分解成一个个记录(key-value对),map会依次处理每一个记录。
split在hadoop中用接口InputSplit来表示,每个InputSplit的实例表示一个split。InputSplit有两个成员变量,分别表示这个split的长度和存储这个split的节点位置。split的处理方式是按贪心算法实现的,长度大小用来将split进行排序,使最大的split优先被处理;MapReduce利用存储位置成员变量来保证执行map任务的节点与split距离最近。
InputFormat负创建splits并且将split分解为各个记录。InputFormat接口中包含两个方法:JobClient调用getSplits来计算splits,计算splits后,客户端将他们发送给jobtracker,jobtracker利用splits中的存储节点位置信息来调度map任务。在tasktracker执行map任务过程中,会调用getRecordReader成员函数来获得记录,并对每个记录调用map方法。
FileInputFormat:
FileInputFormat是所有以文件作为数据源的InputFormat实现的基类,FileInputFormat保存作为job输入的所有文件,并实现了对输入文件计算splits的方法。至于获得记录的方法是有不同的子类进行实现的。
FileInputFormat提供了一套addInputPath方法来设置job的输入路径,可以通过这些方法来构造一个路径的列表,具体的可参见api文档。
获得了输入文件后,FileInputFormat是怎样将他们划分成splits的呢?FileInputFormat只划分比HDFS block大的文件,所以FileInputFormat划分的结果是这个文件或者是这个文件中的一部分,如果一个文件的大小比block小,将不会被划分,这也是Hadoop处理大文件的效率要比处理很多小文件的效率高的原因。
当Hadoop处理很多小文件(文件大小小于hdfs block大小)的时候,由于FileInputFormat不会对小文件进行划分,所以每一个小文件都会被当做一个split并分配一个map任务,导致效率底下。比如一个1G的文件,会被划分成16个64MB的split,并分配16个map任务处理,而10000个100kb的文件会被10000个map任务处理。
有些时候我们需要将整个文件的内容作为map的输入,这时可以实现一个FileInputFormat,复写isSplittable函数禁止对输入数据进行分片。输入文件没有被分片,我们必须将整个文件的内容作为一个记录,这是我们需要实现一个RecodeReader来处理数据。
是不是有点晕的,还是看实际程序吧,这个例子是将6个小文件利用mapreduce的方法合并成一个大文件,并将这个文件以sequencefile的形式在HDFS中保存起来。代码如下:
WholeFileInputFormat类实现FileInputFormat,关闭分片功能,并返回新定义的WholeFileRecordReader.
运行程序后得到结果:
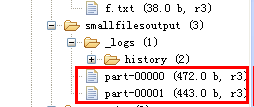
由于我们设置了reduce结果是sequencefile格式,所以在控制台用hadoop fs -text查看结果:

因为设置了reducer的数目为2,所以会产生两个文件,并且map结果是按key分组和排序的,所以我们可以得到上述结果。
FileInputFormat分析完毕,下面我们看一下Hadoop的各种输入格式:
1. TextInputformat
TextInputformat是默认的inputformat,对于输入文件,文件中每一行作为一个记录,他将每一行在文件中的起始偏移量作为key,每一行的内容作为value。为什么不用行数作为key呢?
注意split中只是保存了split在文件中的位置,map操作读取数据的时候还是会到HDFS中打开原始文件,然后定位到split所需的数据的位置。
所以在处理split的时候,打开文件后定位到split所在的位置,但是我们不知道这个split的第一个记录处在文件的第几行,我们也无法知道上一个split中存了多少行数据,所以不能确定这个记录是文件中的第几行。
然而我们会定位到split时我们可以获得第一个记录的偏移量,所以TextInputformat是以行的偏移量作为key。
2. key-value TextInputformat
当输入数据的每一行是两列,并用tab分离的形式的时候,key-value TextInputformat处理这种格式的文件非常适合。
3.NLineInputformat
NLineInputformat可以控制在每个split中数据的行数。
4.SequenceFileInputformat
当输入文件格式是sequencefile的时候,要使用SequenceFileInputformat。由于sequencefile都是以key和value的二进制形式存放的(注意hadoop类型的二进制的解释方式和原始二进制不一样,会多一些维护信息),所以这种情况下map的key和value的类型是由sequencefile决定的,所以必须保证map的输入类型与sequencefile一致。比如sequencefile中的内容key的类型是intwritable,value的类型是Text,那么在map的类型也必须是这两个。
5.sequencefileAsTextInputFormat
sequencefileAsTextInputFormat将sequencefile的key和value都转化成Text对象传入map中。
6.sequencefileAsBinaryInputFormat
他将sequencefile中的key和value都以原始二进制的形式封装在byteswritable对象中传给map,如何对二进制数据进行解释是map函数编写者的工作。
7.复合输入
MapReduce的输入格式可能不只一种,这时可以使用MutipleInputs来多次添加路径并制定输入格式。
输出格式:
1.TextOutputformat
默认的输出格式,key和value中间值用tab隔开的。
2.SequenceFileOutputformat
将key和value以sequencefile格式输出。
3.sequencefileAsOutputFormat
将key和value以原始二进制的格式输出。
4.MapFileOutputFormat
将key和value写入MapFile中。由于MapFile中的key是有序的,所以写入的时候必须保证记录是按key值顺序写入的。
5.MultipleOutputFormat
默认情况下一个reducer会产生一个输出,但是有些时候我们想一个reducer产生多个输出,MultipleOutputFormat和MultipleOutputs可以实现这个功能。
MultipleOutputFormat允许reducer将输出写入多个文件,写入那个文件是由key和value决定的。MultipleOutputFormat提供了一些方法可以控制reducer输出目标文件的名字。MultipleOutputFormat是MultipleTextOutputFormat和MultipleSequenceOutputFormat两个类的父类。
例如可以写一个类,继承自MultipleTextOutputFormat并复写他的generateFileNameForKeyValue方法控制reduce输出目标的文件名。程序运行的时候不同的reducer输出结果的时候调用这个方法,这个方法根据要输出记录的信息产生文件名,reducer将数据写入相应文件中,这样就能是一个reducer向多个文件写入。利用这个特性我们就可以方便的进行结果的聚类了。
我们看下面例子:
运行程序后会在output1目录中得到两个结果:
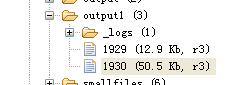
可以看到reduce的结果输出是按照年份来分别输出到不同的文件中的。
6. MultipleOutputs
MultipleOutputFormat实际上是在reduce输出结果的时候指定文件名来实现多文件输出,而MultipleOutputs是在job指定的output基础上,新增额外的输出,他才是真正意义上的多文件输出。
MultipleOutputs分为两种情况:
·附加单个文件输出。有些时候我们在原有的结果输出基础上,还想输出一些其他的信息,这是就可以调用MultipleOutputs的addNamedOutput方法,并且outputformat格式及keyvalue类型都可以自定义的。
下面我们看一个例子,一个简单的投票统计程序。程序的输入是:
people1vote2
people2vote1
people3vote2
people4vote3
people5vote2
people6vote1
people7vote3
people8vote2
people9vote2
表示9个人分别为三个候选人投票的情况。保存文件为vote.txt并上传到HDFS中。
·附加多个文件:
调用MultipleOutputs的addMultiNameOutput方法可以附加多个文件,利用这个方法可以实现多文件分类输出。
在配置job的时候用addMultiNameOutput注册一个namedoutput,在reducer中用multipleOutputs.getCollector获取这个namedoutput的时候,第二个参数指明了按照什么进行分割附加输出,我们看下面的例子:
在输出目录中得到了原始输出和三个附加输出文件。