MapReduce运行流程源码分析(一)
?? 这几天都会看一些hadoop的源代码,开始的时候总会没有任何头绪,不知道从哪开始,经过这几天的对hadoop运行流程的分析和了解,还有从别人那得到的一些启发,再加上看到其他人发表的博客,对hadoop源代码 有了一点点的认识,这篇博客写下一点对hadoop源代码的了解
1.启动hadoop
我们都知道启动hadoop的命令是bin/start-all.sh,通过查看start-all.sh脚本,可以发现运行该脚本之后,Hadoop会配置一系列的环境变量以及其他Hadoop运行所需要的参数,然后在本机运行JobTracker和NameNode。然后通过SSH登录到所有slave机器上,启动TaskTracker和DataNode。
2.启动namenode和JobTracker(这次只分析启动JobTracker)
org.apache.hadoop.mapred.JobTracker类实现了JobTracker启动的实现,我们可以看一下JobTracker这个类,
首先看一下startTracker这个方法
?
public static JobTracker startTracker(JobConf conf) throws IOException, InterruptedException { return startTracker(conf, DEFAULT_CLOCK); } static JobTracker startTracker(JobConf conf, Clock clock) throws IOException, InterruptedException { return startTracker(conf, clock, generateNewIdentifier()); } static JobTracker startTracker(JobConf conf, Clock clock, String identifier) throws IOException, InterruptedException { JobTracker result = null; while (true) { try { result = new JobTracker(conf, clock, identifier); result.taskScheduler.setTaskTrackerManager(result); break; } catch (VersionMismatch e) { throw e; } catch (BindException e) { throw e; } catch (UnknownHostException e) { throw e; } catch (AccessControlException ace) { // in case of jobtracker not having right access // bail out throw ace; } catch (IOException e) { LOG.warn("Error starting tracker: " + StringUtils.stringifyException(e)); } Thread.sleep(1000); } if (result != null) { JobEndNotifier.startNotifier(); } return result; }}startTracker函数是一个静态方法,是它调用JobTracker的构造函数生成一个JobTracker类的实例,名为result,传入的参数JobConf,进行一系列的配置。然后,进行了一系列初始化活动,包括启动RPC server,启动内置的jetty服务器,检查是否需要重启JobTracker等。
再来看一下offerService方法
?
/** * Run forever */ public void offerService() throws InterruptedException, IOException { // Prepare for recovery. This is done irrespective of the status of restart // flag. while (true) { try { recoveryManager.updateRestartCount(); break; } catch (IOException ioe) { LOG.warn("Failed to initialize recovery manager. ", ioe); // wait for some time Thread.sleep(FS_ACCESS_RETRY_PERIOD); LOG.warn("Retrying..."); } } taskScheduler.start(); recoveryManager.recover(); // refresh the node list as the recovery manager might have added // disallowed trackers refreshHosts(); startExpireTrackersThread(); expireLaunchingTaskThread.start(); if (completedJobStatusStore.isActive()) { completedJobsStoreThread = new Thread(completedJobStatusStore, "completedjobsStore-housekeeper"); completedJobsStoreThread.start(); } // start the inter-tracker server once the jt is ready this.interTrackerServer.start(); synchronized (this) { state = State.RUNNING; } LOG.info("Starting RUNNING"); this.interTrackerServer.join(); LOG.info("Stopped interTrackerServer"); }?
?
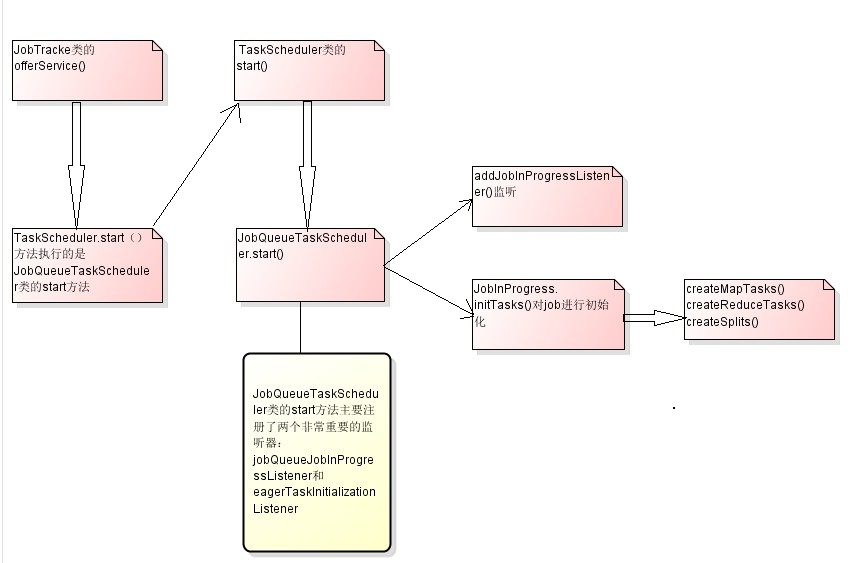
我们可以看到offerService方法其实及时启了taskScheduler.start(),但是我们接着看TaskScheduler类,我们看到调用的TaskScheduler.start()方法,实际上没有做任何事情,实际上taskScheduler.start()方法执行的是JobQueueTaskScheduler类的start方法。
?
?
public void start() throws IOException { // do nothing }?
我们继续看JobQueueTaskScheduler类
?
public synchronized void start() throws IOException { super.start(); taskTrackerManager.addJobInProgressListener(jobQueueJobInProgressListener); eagerTaskInitializationListener.setTaskTrackerManager(taskTrackerManager); eagerTaskInitializationListener.start(); taskTrackerManager.addJobInProgressListener( eagerTaskInitializationListener); }JobQueueTaskScheduler类的start方法主要注册了两个非常重要的监听器:jobQueueJobInProgressListener和eagerTaskInitializationListener。前者是JobQueueJobInProgressListener类的一个实例,该类以先进先出的方式维持一个JobInProgress的队列,并且监听各个JobInProgress实例在生命周期中的变化;后者是EagerTaskInitializationListener类的一个实例,该类不断监听jobInitQueue,一旦发现有新的job被提交(即有新的JobInProgress实例被加入),则立即调用该实例的initTasks方法,对job进行初始化。
那个监听的类我们就不看了,我们看一下JobInProgress类,其中的主要方法initTasks()的主要代码
?
public synchronized void initTasks() throws IOException, KillInterruptedException, UnknownHostException { if (tasksInited.get() || isComplete()) { return; } synchronized(jobInitKillStatus){ if(jobInitKillStatus.killed || jobInitKillStatus.initStarted) { return; } jobInitKillStatus.initStarted = true; } LOG.info("Initializing " + jobId); logSubmissionToJobHistory(); // log the job priority setPriority(this.priority); // // generate security keys needed by Tasks // generateAndStoreTokens(); // // read input splits and create a map per a split // TaskSplitMetaInfo[] taskSplitMetaInfo = createSplits(jobId); numMapTasks = taskSplitMetaInfo.length; checkTaskLimits(); // Sanity check the locations so we don't create/initialize unnecessary tasks for (TaskSplitMetaInfo split : taskSplitMetaInfo) { NetUtils.verifyHostnames(split.getLocations()); } jobtracker.getInstrumentation().addWaitingMaps(getJobID(), numMapTasks); jobtracker.getInstrumentation().addWaitingReduces(getJobID(), numReduceTasks); createMapTasks(jobFile.toString(), taskSplitMetaInfo); if (numMapTasks > 0) { nonRunningMapCache = createCache(taskSplitMetaInfo, maxLevel); } // set the launch time this.launchTime = JobTracker.getClock().getTime(); createReduceTasks(jobFile.toString()); // Calculate the minimum number of maps to be complete before // we should start scheduling reduces completedMapsForReduceSlowstart = (int)Math.ceil( (conf.getFloat(MRJobConfig.COMPLETED_MAPS_FOR_REDUCE_SLOWSTART, DEFAULT_COMPLETED_MAPS_PERCENT_FOR_REDUCE_SLOWSTART) * numMapTasks)); initSetupCleanupTasks(jobFile.toString()); synchronized(jobInitKillStatus){ jobInitKillStatus.initDone = true; if(jobInitKillStatus.killed) { //setup not launched so directly terminate throw new KillInterruptedException("Job " + jobId + " killed in init"); } } tasksInited.set(true); JobInitedEvent jie = new JobInitedEvent( profile.getJobID(), this.launchTime, numMapTasks, numReduceTasks, JobStatus.getJobRunState(JobStatus.PREP), false); jobHistory.logEvent(jie, jobId); // Log the number of map and reduce tasks LOG.info("Job " + jobId + " initialized successfully with " + numMapTasks + " map tasks and " + numReduceTasks + " reduce tasks."); }?
?在这个方法里面有两个重要的方法:
createMapTasks(jobFile.toString(), taskSplitMetaInfo);
createReduceTasks(jobFile.toString())
其实初始化Tasks的过程应该就是这部分最重要的一步
?
//map task的个数就是input split的个数numMapTasks = splits.length;//为每个map tasks生成一个TaskInProgress来处理一个input splitmaps = newTaskInProgress[numMapTasks];for(inti=0; i < numMapTasks; ++i) {inputLength += splits[i].getDataLength();maps[i] =new TaskInProgress(jobId, jobFile,splits[i],jobtracker, conf, this, i);}?
对于map task,将其放入nonRunningMapCache,是一个Map<Node,
List<TaskInProgress>>,也即对于map task来讲,其将会被分配到其input
split所在的Node上。在此,Node代表一个datanode或者机架或者数据中
心。nonRunningMapCache将在JobTracker向TaskTracker分配map task的
时候使用。
?
if(numMapTasks > 0) {nonRunningMapCache = createCache(splits,maxLevel);}//创建reduce taskthis.reduces = new TaskInProgress[numReduceTasks];for (int i= 0; i < numReduceTasks; i++) {reduces[i]= new TaskInProgress(jobId, jobFile,numMapTasks, i,jobtracker, conf, this);/*reducetask放入nonRunningReduces,其将在JobTracker向TaskTracker分配reduce task的时候使用。*/nonRunningReduces.add(reduces[i]);}//创建两个cleanup task,一个用来清理map,一个用来清理reduce.cleanup =new TaskInProgress[2];cleanup[0]= new TaskInProgress(jobId, jobFile, splits[0],jobtracker, conf, this, numMapTasks);cleanup[0].setJobCleanupTask();cleanup[1]= new TaskInProgress(jobId, jobFile, numMapTasks,numReduceTasks, jobtracker, conf, this);cleanup[1].setJobCleanupTask();//创建两个初始化 task,一个初始化map,一个初始化reduce.setup =new TaskInProgress[2];setup[0] =new TaskInProgress(jobId, jobFile, splits[0],jobtracker,conf, this, numMapTasks + 1 );setup[0].setJobSetupTask();setup[1] =new TaskInProgress(jobId, jobFile, numMapTasks,numReduceTasks + 1, jobtracker, conf, this);setup[1].setJobSetupTask();tasksInited.set(true);//初始化完毕}?
?这一部分就结束了,我画一张简单的流程图
启动datanode和TaskTracker(同样我们这里只讲一下TaskTracker)
org.apache.hadoop.mapred.TaskTracker类实现了MapReduce模型中TaskTracker的功能。TaskTracker也是作为一个单独的JVM来运行的,其main函数就是TaskTracker的入口函数,当运行start-all.sh时,脚本就是通过SSH运行该函数来启动TaskTracker的。
我们来看一下TaskTracker类的main函数
?
public static void main(String argv[]) throws Exception { StringUtils.startupShutdownMessage(TaskTracker.class, argv, LOG); if (argv.length != 0) { System.out.println("usage: TaskTracker"); System.exit(-1); } try { JobConf conf=new JobConf(); // enable the server to track time spent waiting on locks ReflectionUtils.setContentionTracing (conf.getBoolean(TT_CONTENTION_TRACKING, false)); new TaskTracker(conf).run(); } catch (Throwable e) { LOG.error("Can not start task tracker because "+ StringUtils.stringifyException(e)); System.exit(-1); } }?
?
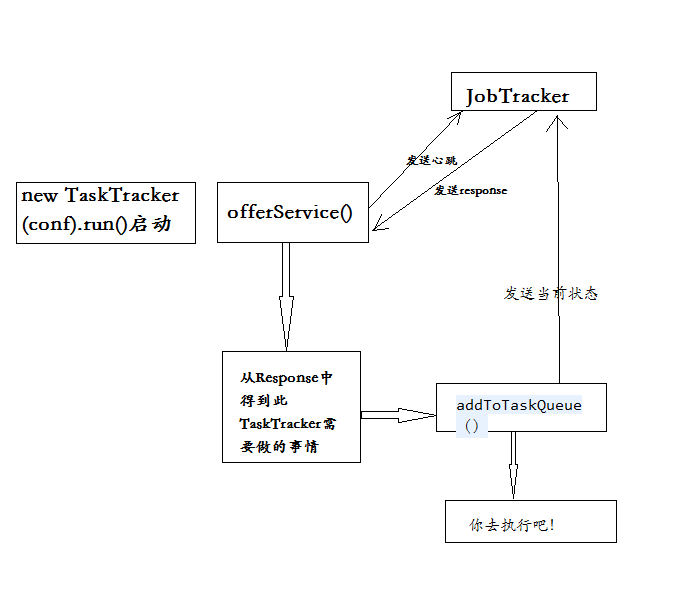
里面主要的代码就是new TaskTracker(conf).run(),传入配置文件conf,其中run函数主要调用了offerService函数
?
public void run() { try { startCleanupThreads(); boolean denied = false; while (running && !shuttingDown && !denied) { boolean staleState = false; try { // This while-loop attempts reconnects if we get network errors while (running && !staleState && !shuttingDown && !denied) { try { State osState = offerService(); if (osState == State.STALE) { staleState = true; } else if (osState == State.DENIED) { denied = true; } } catch (Exception ex) { if (!shuttingDown) { LOG.info("Lost connection to JobTracker [" + jobTrackAddr + "]. Retrying...", ex); try { Thread.sleep(5000); } catch (InterruptedException ie) { } } } } } finally { close(); } if (shuttingDown) { return; } LOG.warn("Reinitializing local state"); initialize(); } if (denied) { shutdown(); } } catch (IOException iex) { LOG.error("Got fatal exception while reinitializing TaskTracker: " + StringUtils.stringifyException(iex)); return; } catch (InterruptedException i) { LOG.error("Got interrupted while reinitializing TaskTracker: " + i.getMessage()); return; } }?
?
每隔一段时间就向JobTracker发送heartbeat
?
long waitTime = heartbeatInterval - (now - lastHeartbeat);
if (waitTime > 0) { // sleeps for the wait time or // until there are empty slots to schedule tasks synchronized (finishedCount) { if (finishedCount.get() == 0) { finishedCount.wait(waitTime); } finishedCount.set(0); } }
?
发送Heartbeat到JobTracker,得到response
?
// Send the heartbeat and process the jobtracker's directives HeartbeatResponse heartbeatResponse = transmitHeartBeat(now);//从Response中得到此TaskTracker需要做的事情 TaskTrackerAction[] actions = heartbeatResponse.getActions();if (actions != null){ for(TaskTrackerAction action: actions) { if (action instanceof LaunchTaskAction) { addToTaskQueue((LaunchTaskAction)action); } else if (action instanceof CommitTaskAction) { CommitTaskAction commitAction = (CommitTaskAction)action; if (!commitResponses.contains(commitAction.getTaskID())) { LOG.info("Received commit task action for " + commitAction.getTaskID()); commitResponses.add(commitAction.getTaskID()); } } else { tasksToCleanup.put(action); } } } markUnresponsiveTasks(); killOverflowingTasks(); ?
?
其中transmitHeartBeat方法的作用就是向JobTracker发送Heartbeat
?
//每隔一段时间,在heartbeat中要返回给JobTracker一些统计信息booleansendCounters;if (now> (previousUpdate + COUNTER_UPDATE_INTERVAL)) {sendCounters = true;previousUpdate = now;}else {sendCounters = false;}?
?
报告给JobTracker,此TaskTracker的当前状态
?
if(status == null) {synchronized (this) {status = new TaskTrackerStatus(taskTrackerName, localHostname,httpPort,cloneAndResetRunningTaskStatuses(sendCounters),failures,maxCurrentMapTasks,maxCurrentReduceTasks);}}?
当满足下面的条件的时候,此TaskTracker请求JobTracker为其分配一个新的Task来运行:
当前TaskTracker正在运行的map task的个数小于可以运行的map task的最大个数
当前TaskTracker正在运行的reduce task的个数小于可以运行的reduce task的最大个数
?
booleanaskForNewTask;longlocalMinSpaceStart;synchronized (this) {askForNewTask = (status.countMapTasks() < maxCurrentMapTasks ||status.countReduceTasks() <maxCurrentReduceTasks)&& acceptNewTasks;localMinSpaceStart = minSpaceStart;}//向JobTracker发送heartbeat,这是一个RPC调用HeartbeatResponse heartbeatResponse = jobClient.heartbeat(status,justStarted, askForNewTask,heartbeatResponseId);……returnheartbeatResponse;}?
?这个过程还是很复杂的这涉及到RPC,以及很复杂的通信控制,我在这里比较简单的概括了一下其中过程,希望大家可以自己深入研究,最后还是贴一张我自己画的流程图
?
今天这分析了两步,我自己也要进一步的深入分析,明天继续分析后面的过程,敬请期待!
?