利用lucene构建自己的搜索引擎
lucene 是什么?
lucene是一个基于JAVA的全文信息检索工具包,它不是一个完整的搜索引擎,它只为你的程序构建索引,然后在索引上进行搜索。具体lucene能做什么,见下图:
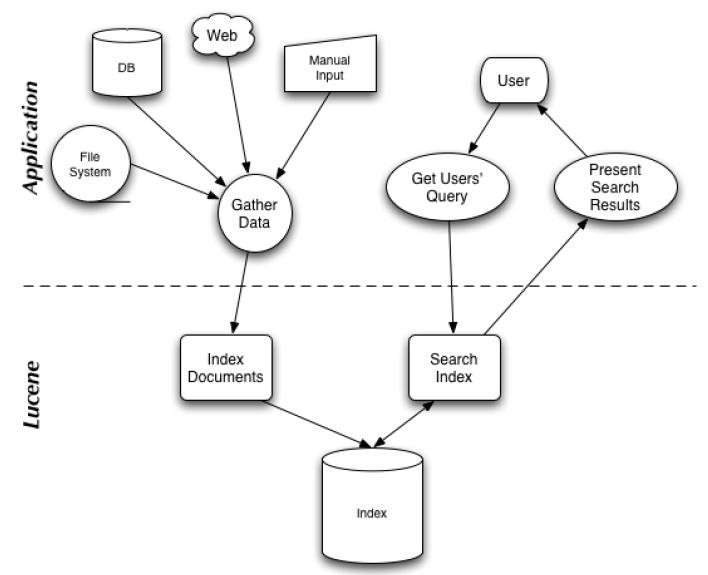
lucene能做什么?
任何文本的东西都可以给lucene构建索引,不管是pdf、html只要能转换为文本,lucene就可以构建索引,查询索引。就这么简单
下面就用一个简单的例子来构建自己的应用程序:
Lucene 软件包分析
Lucene 软件包的发布形式是一个 JAR 文件,下面我们分析一下这个 JAR 文件里面的主要的 JAVA 包,使读者对之有个初步的了解。
Package: org.apache.lucene.document
这个包提供了一些为封装要索引的文档所需要的类,比如 Document, Field。这样,每一个文档最终被封装成了一个 Document 对象。
Package: org.apache.lucene.analysis
这个包主要功能是对文档进行分词,因为文档在建立索引之前必须要进行分词,所以这个包的作用可以看成是为建立索引做准备工作。
Package: org.apache.lucene.index
这个包提供了一些类来协助创建索引以及对创建好的索引进行更新。这里面有两个基础的类:IndexWriter 和 IndexReader,其中 IndexWriter 是用来创建索引并添加文档到索引中的,IndexReader 是用来删除索引中的文档的。
Package: org.apache.lucene.search
这个包提供了对在建立好的索引上进行搜索所需要的类。比如 IndexSearcher 和 Hits, IndexSearcher 定义了在指定的索引上进行搜索的方法,Hits 用来保存搜索得到的结果。
首先介绍一下lucene的基本类:
Document : 用于表示一个文件,document由Field组成,是Field的一个集合,Field表示用于建立索引和查询索引。所以为了能合理的区分多个document,建议对每个文档用到的Field应该是能唯一标识该docuemnt,尽量和别的document的Field内容不同。
Field: Document的集合内容,用于区分文档和查询文档的基本单位,有两部分组成一个是name,一个是原始的未加工的文本内容。如Field field = new Field("name" ,"value");,在查询索引的时刻可以依据name来查询,也就是用name对应的value来匹配我们的关键字。
Analyze: 建立索引避免不了对文档内容进行分词,Analyze对象正是用于分词的对象。该类是一个抽象内,你可以依据自己的业务规则来分词,还有很多第三方分词器,自己用适配模式+代理模式来适配自己的业务也行。
Directory: Directory是用来存储index文件的目录,该类有两个实现类FSDirectory/RAMDirectory(FS = FileSystem , RAM...).
IndexWriter: IndexWriter是用来建立索引的具体类,IndexReader 是用来删除索引的具体类.
IndexSearcher:IndexSearcher是在已经建立的索引上进行查询的具体类。
建立索引的例子代码:
利用lucene构建自个儿的搜索引擎
利用lucene构建自己的搜索引擎lucene 是什么?lucene是一个基于JAVA的全文信息检索工具包,它不是一个完整的