测试服务器最大内存带宽的实验
介绍
Intel Nehalem架构处理器内建了内存控制器,处理器之间通过QPI互联,是典型的NUMA系统。NUMA系统的特点是每一个节点都有自己的内存控制器,尽管每个节点都能访问所有节点上的内存,但是代价不一样,访问本地内存的速度比访问远程节点的速度要快。使用Intel Nehalem架构的处理器时,如果一个节点需要访问另一个节点的内存,那么数据需要通过CPU的QPI通道访问,因此会有一些延时。下面通过实验来测试内存带宽、QPI带宽以及访问远程节点和本地节点内存的性能差异。
?
实验平台硬件:双Intel? Xeon? Processor E5606(8M Cache, 2.13 GHz, 4.80 GT/s Intel? QPI)处理器,每一个处理器有4个物理内核,并且带有3个内存通道。分别在两个处理器的一个通道上插一根4GB DDR3 1066内存,内存总计8GB。
软件:最简64bit gentoo系统,kernel 3.0.6,开启numa支持,系统中除了系统守护进程之外只运行了nfsd和sshd。
?
实验方案要测带宽就要跑满内存,但是真正要把内存带宽跑满还是需要一点技巧的。为了单纯地将读方向的带宽跑满,可以写一个循环读数组。这样有几个问题:
?
如果不开启编译器优化,那么编译器会生成很多垃圾代码,不能充分利用内存带宽。不能将一个数组写入另一个数组,因为如果读写发生在同一个内存通道上,那么这个通道上会发生争用,无法占满带宽。因此为了纯粹地测试“读出数据”产生的带宽,应该将数组读入一个变量。如果开启-O优化,编译器会生成优化的代码,而这个优化的代码会把读内存优化掉,因为光读不写。如果将读入的变量声明为volatile,由于mov不能从内存位置复制到另一个内存位置,所以生成的代码会先将内存中的数据读入一个寄存器,然后再从寄存器写入变量的位置。这一款处理器的cache line为64字节。也就是说读入数组中的第一个字节的时候实际上后面的63个字节也加载到cache中了,所以后面数据的读取实际上走的是cache,没有跑内存。为了解决上面的问题以及问题引发的问题,这个实验采取的方法是开辟一个很大的缓冲区(256MB),然后通过循环将缓冲区的内容读入一个寄存器。循环步进为64字节,但是每一次只执行一次mov指令。实际上只复制了256M/64=4M次数据。这样可以保证每一次循环都从内存加载了数据,但是不能遍历整个缓冲区,不过也没有必要遍历缓冲区的所有字节,因为实验目的是把内存带宽跑满,而不是为了最快复制数据或正确复制数据。
?
另外,为了测试跨节点内存访问,测试程序启两个线程,一个线程(1)生成缓冲区,然后创建另一个线程(2),将缓冲区地址传给线程2。线程2读数据。线程1和线程2分别绑定在两个CPU内核上。绑定之后,Linux的NUMA特性可以确保线程1分配的缓冲区在线程1绑定的节点所属的内存上,而线程2的读取数据的寄存器一定在线程2运行的CPU内核上。如果线程1和线程2在同一个节点(也就是同一个CPU)上,那么可以直接访问内存,而不用通过QPI。如果线程1和线程2不在同一个节点上,那么读取内存就需要通过QPI,必然会有性能损失。
?
实验中通过intel提供的性能调优工具PTU查看当前QPI使用量和内存流量。
实验过程实验代码如下所示:
?
#define _GNU_SOURCE#include <stdio.h>#include <stdlib.h>#include <sched.h>#include <pthread.h>#include <sys/time.h>#include <sys/times.h>#define SIZE_IN_MB 256#define NUM_BYTE (SIZE_IN_MB*1024*1024)#define NUM_LONG (NUM_BYTE/sizeof(long))#define CACHELINE_SIZE 64/* wall time */struct timeval start_time, stop_time, elapse_time;/* process time */struct tms start_process, stop_process, elapse_process;typedef struct{ cpu_set_t binding; size_t times; long* datap;} reader_args_t;typedef struct{ cpu_set_t binding; cpu_set_t reader_binding; size_t reader_times;} gen_args_t;void* read_data(void *arg){ reader_args_t *my_args = (reader_args_t *)arg; /* do binding */ sched_setaffinity(0, sizeof(cpu_set_t), &(my_args->binding)); /* int *buf = (int *)malloc( (my_args->datasz) * sizeof(int));*/ gettimeofday(&start_time, NULL); times(&start_process); long *datap; for (size_t times = 0; times < my_args->times; ++times) { datap = my_args->datap; __asm__ ("movq %0, %%rax\n\t" : :"m"(datap) ); for (size_t i = 0; i < NUM_BYTE / CACHELINE_SIZE; ++i) { __asm__ ("movq (%%rax), %%rcx\n\t" "addq $64, %%rax\n\t" : : "a"(datap) : "%rcx"); } } return ((void *)0);}void* gen_data(void *arg){ pthread_t reader_tid; void *tret; gen_args_t *my_args = (gen_args_t *)arg; /* do binding */ sched_setaffinity(0, sizeof(cpu_set_t), &(my_args->binding)); unsigned long* data = (long*)malloc(NUM_LONG * sizeof(long)); printf("The address of source data is %p\n", data); for (size_t i = 0; i < NUM_LONG; ++i) data[i] = 0x5a5a5a5a5a5a5a5a; reader_args_t *reader_args = (reader_args_t *)malloc(sizeof(reader_args_t)); reader_args->binding = my_args->reader_binding; reader_args->times = my_args->reader_times; reader_args->datap = data; pthread_create(&reader_tid, NULL, read_data, (void*)reader_args); pthread_join(reader_tid, &tret); free(data); return ((void *)0);}int main(int argc, char *argv[]){ if (argc < 4) { fprintf(stderr, "Usage: %s <times> <from> <to>\n", argv[0]); exit(EXIT_FAILURE); } pthread_t gen_tid; void *tret; gen_args_t *gen_args = (gen_args_t *)malloc(sizeof(gen_args_t)); gen_args->reader_times = (size_t)atoi(argv[1]); cpu_set_t from_binding, to_binding; CPU_ZERO(&from_binding); CPU_ZERO(&to_binding); CPU_SET(atoi(argv[2]), &from_binding); CPU_SET(atoi(argv[3]), &to_binding); gen_args->binding = from_binding; gen_args->reader_binding = to_binding; pthread_create(&gen_tid, NULL, gen_data, (void *)gen_args); pthread_join(gen_tid, &tret); gettimeofday(&stop_time, NULL); times(&stop_process); timersub(&stop_time, &start_time, &elapse_time); printf("time cost %ld.%06ld secs.\n", elapse_time.tv_sec, elapse_time.tv_usec); return 0;}?
read_data()是读取数据的线程调用的线程函数。这个函数里面通过内嵌汇编确保真的将数据读入了rcx寄存器。将数据读入寄存器可以尽可能地避免写数据的干扰。
?
这个程序可以在参数中选择要复制的次数,以及两个线程分别绑在哪个CPU内核上。在这个实验平台中,第一个CPU的4个内核对应的id是0,1,2,3;第二个CPU的4个内核对应的id是4,5,6,7。
?
因此,运行
?
zsy-gentoo thread_read # ./thread_read 500 0 0The address of source data is 0x7f1aeda5a010time cost 16.759935 secs.
表示程序运行500次,两个线程都在CPU内核0上,因此这是节点内读取。这一次的读取时间是16.8秒。
运行这条命令的时候,PTU显示如下图所示:
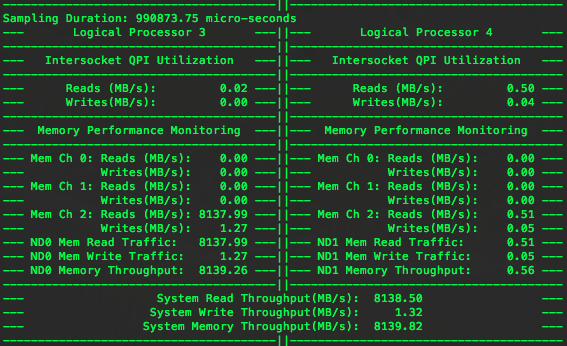
可以看出,内存通道2上读数据的流量为8140MB/s。这是1066的通道,所以理论带宽为1066*8 = 8528,因此实测带宽为理论带宽的95%以上。
?
下面运行
?
zsy-gentoo thread_read # ./thread_read 500 3 4The address of source data is 0x7f29a8bd7010time cost 19.825897 secs.
?
这一次,缓冲区在第一个节点上,而数据读取在第二个节点上,所以会产生跨节点通信。PTU显示如下图所示:
?
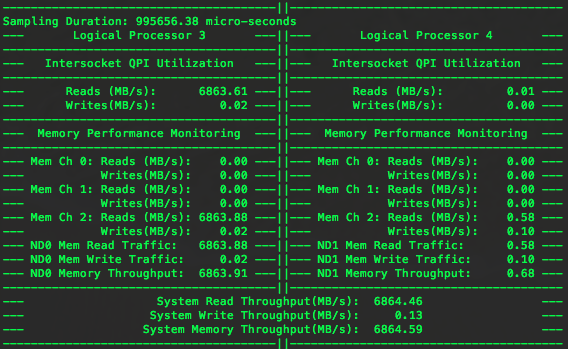
这一次,虽然读取数据发生在第二个节点,但是实际的数据在第一个节点上,所以内存流量全部都发生在第一个节点上,QPI负责从第一个节点上访问数据。由于跨节点访问,所以读取数据的时间从16.8秒降为19.8秒。这一次很明显节点1的内存带宽受制于QPI所以没有跑满。
?
那么这是不是说明QPI的带宽就是6.8GB/s呢?根据Intel的qpi白皮书文档,4.80 GT/s的QPI相当于19.2GB/s的理论带宽,单向带宽就是19.2/2 = 9.6GB/s。
?
下面做另一个实验。把第二块CPU的内存取出,放在第一块CPU的一个空闲通道上,这样第一块CPU就有2个通道,理论内存带宽倍增,第二块CPU没有内存,因此第二块CPU上的任何数据访问都要通过QPI。
?
首先运行以下命令:
?
zsy-gentoo thread_read # ./thread_read 500 4 4The address of source data is 0x7f5228a02010time cost 20.358352 secs.
在第二块CPU上通过QPI访问数据,这是PTU显示如下:
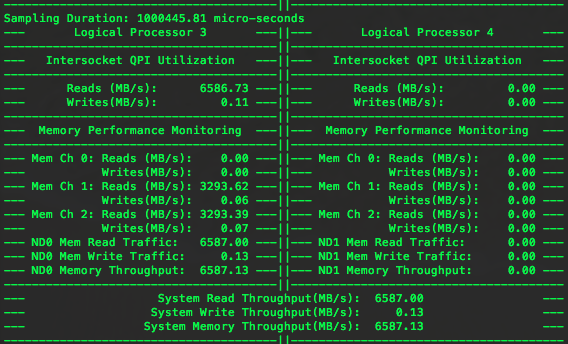
可以看出QPI使用率达到了前一个实验中的使用率。在第一块CPU上的两个内存通道都有流量,而且因为操作系统的调度,这两个内存通道流量均衡,共同承担了数据访问,但是这两个内存通道的使用率明显偏低。
?
下面在第二块CPU上再启一个访问数据的程序,看一看QPI使用率是否会增加。
?
zsy-gentoo thread_read # ./thread_read 500 4 4 &zsy-gentoo thread_read # ./thread_read 500 6 6 &
这时PTU显示如下:
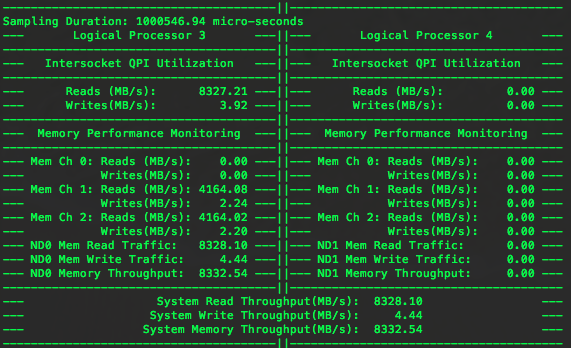
?
这时可以看到QPI使用率提升到了8.3GB/s,说明并发访问能够提升QPI的使用率。可是此时内存通道的使用率仍然不高,两个内存通道都达到一半左右。因此,再增加第二块CPU上的内存访问负载,运行第三个访问内存程序。
?
zsy-gentoo thread_read # ./thread_read 500 4 4 &zsy-gentoo thread_read # ./thread_read 500 6 6 &zsy-gentoo thread_read # ./thread_read 500 5 5 &
这时PTU显示如下图所示:
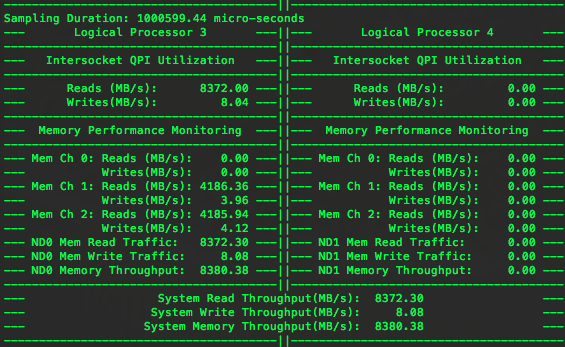
可以看出,QPI使用率并没有明显增加。因此可以看出在这个实验平台上QPI的单向带宽大约为8.3GB/s,是理论带宽的86%。
?