map/reduce 过程的认识
?
??? map/reduce 过程的认识
?
????? 最初我一直简单的以为map的工作就是将数据打散,而reduce就是将map打散后的数据合并。虽然之前跑过wordcount的例子,但之前只是对输出reduce最终的结果感兴趣,对控制台打印的日志信息完全不懂。这几天我们团队在探索pagerank,才开始对map/reduce有了深一层的了解。当一个job提交后,后续具体的一系列分配调度工作我现在不清楚。我现在只是了解些map/reduce过程。
?原来map过程和reduce的过程也都包含了多个步骤。
?
? 作业的inputFormat类规定了对提交的作业的输入文件切分方法。默认是将输入文件按照字节的大小分割成不同的块。? 至于这个过程到底是怎么实现的我也不清楚。我现在只是记录下我对map reduce的理解。
?
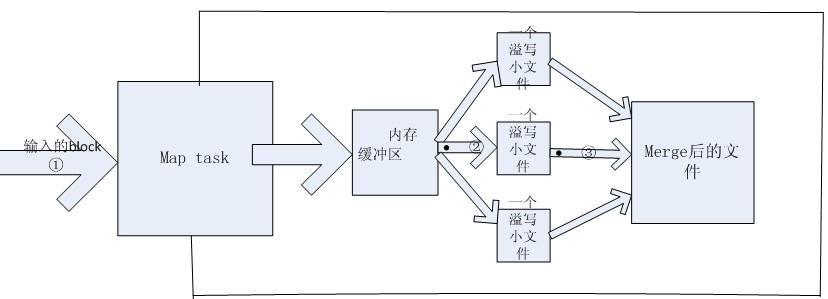
? 输入文件可能会被打散成多个块(block),至于是怎么分成块的,我不清楚。一个块的大小是默认是64MB,也是可以通过参数设置的其大小的。所以若采用默认的,如果初始数据<64MB 时,就只有一个块了。每一个块就是一个Map task的输入。也就是说有多少个块就会有多少个map task。 那map task 的工作是怎么样的呢?
?? 
?
??? 简单的来说,map task 也有几个步骤:从hdfs上获取block数据à从内存中溢写(spill)文件àmerge溢写文件
?
在DataNode节点上的每个map task任务都会有一个内存缓冲区,用来临时存储它的输出结果的,其实也就是减少对磁盘的读写频率。这里面的数据只是key/value对和partition的结果。前者我们都可以理解是什么东西,那后者呢?我们都知道map task的数量不是完全由人为设置的,但reduce task的数目是client设置的,默认是1。这就需要对key值划分区,知道哪些key 是由哪个reduce task处理的。Partitioner就是干这个工作的。默认的方法是使用Hash函数,当然用户也可以通过实现自定义的 ?
?
?
?
但是可能又会有疑问了,如果merge只是简单的合并过程,那如果像wordcount例子的情况,假如第一个溢写文件中 单词“hello”(key值) 出现的次数是4(value值),第二个溢写文件中 单词“hello”(key值) 出现的次数是9(value值),假设只有两个溢写文件。那merge后还是会出现相同的key值键对。所以如果之前设置过combiner ,此就会使用combiner将相同的key的values合并,形成 hello(key值)---[4,9](values值)。 这个combine过程并不一定要等到merge结束后才执行,而且也并不是一定要执行,用户可以自己设置的。 当这些个步骤都结束后map端的工作 才算结束。最终的这个输出文件也是存储在本地磁盘中的。
?
?
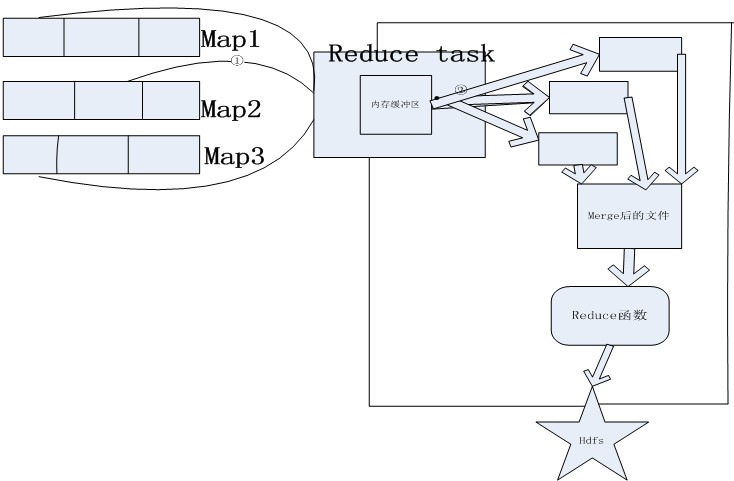
Reduce是将map 的输出结果作为它的输入文件。整个reduce过程就又涉及到多个步骤了。Reduce过程并不是要等到所有的map task执行完后才执行。只要有一个map task执行完后,reduce阶段就可以开始了。
?????? 这个过程我只能用粗略图表示了。
?
?
?
?
?
?
?????三.? 最后还有需要说明的是client可以控制对这些中间结果是否进行压缩以及怎么压缩,使用哪种压缩格式。也不是说一定要这个压缩步骤,若需要写入磁盘的数据量太大,相对来说就可以让CPU帮忙减轻下IO负荷。具体map reduce整个过程中有太多问题还不清楚,还要继续验证。总之就是越发觉得复杂了。