运行时: 块内存复制,第 2 部分
我的?前一专栏专注于 16-MB 的内存块,这次我将讨论大小范围在 4 字节到 64 MB 之间的内存块。先前,我检验了各种执行内存传送的方法并确定使用系统提供的?memcpy()?例程是一个很不错的主意(至少在学会其它更好的方法之前,我会一直这样认为)。
在此处描述的测试中,我运行了几次传送以确保数据是可再生的。我的测试仅在内存为 576 MB 的 ThinkPad 600X (650 MHz) 上运行。没有在其它的双重引导系统上运行过。
我鼓励您在双重引导机器上运行这些测试并报告测试结果。另外,我还鼓励您对程序中的编程方法提出批评和提高性能的建议。本文中,我们的目的是演示最好的编程实践,而不是为证明一个系统比另一个好。
测试内存复制时间
我将使用与上个月几乎相同的程序。仍然使用一个开销小的、简单的源代码管理系统,我将程序重命名为?memxfer5c.cpp。
我所做的更改考虑到了小于 32 个字节的内存块。由于部分循环展开是通过?"double *"?传送进行,所以上个月的程序只允许传送大于或等于 32 个字节。Memxfer5c.cpp 只是仅仅不用?"double *"?方法传送小于 32 字节的内存块。另外,还纠正了用法信息中的一个错误。
现在,让我们检查一下块大小和编程技术。我们的测试运行的测试脚本是?test2c.sh。它主要由一长列带有不同块大小和循环计数的 memxfer5c 命令行组成。
Memxfer5c.cpp 的用法信息几乎相同:
memxfer5c 用法信息
测试脚本文件中一个典型的命令行如下所示:
?
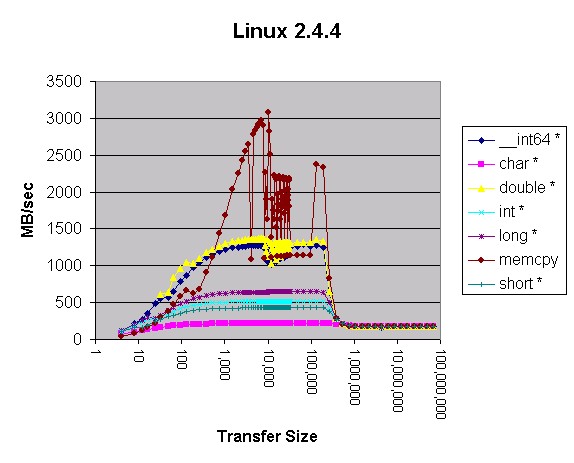
图 2. Linux 2.4.4?
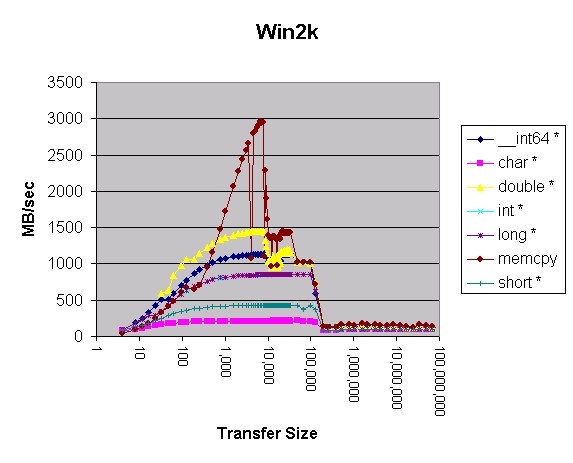
图 3. Win2k?
我还为每个方法绘了一张图,用来显示不同的操作系统:
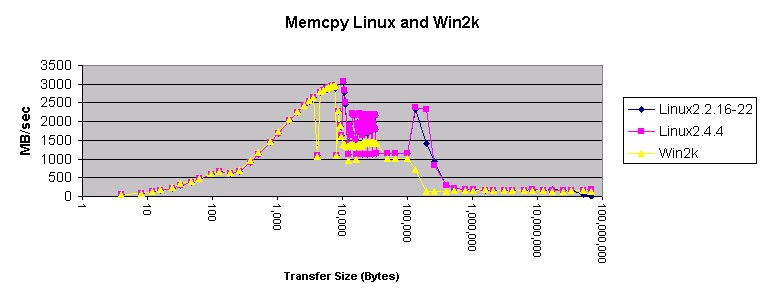
图 4. Linux 和 Win2k 中的 Memcpy?
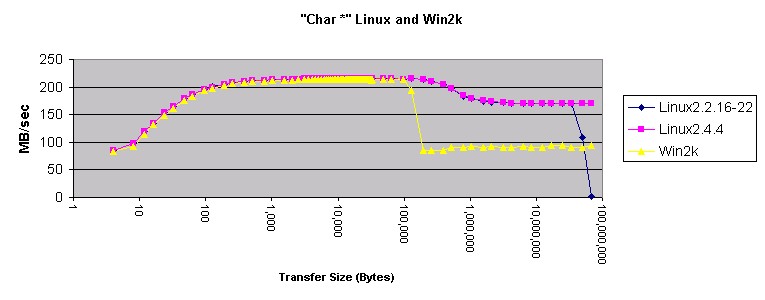
图 5. Linux 和 Win2k 中的 "Char"?
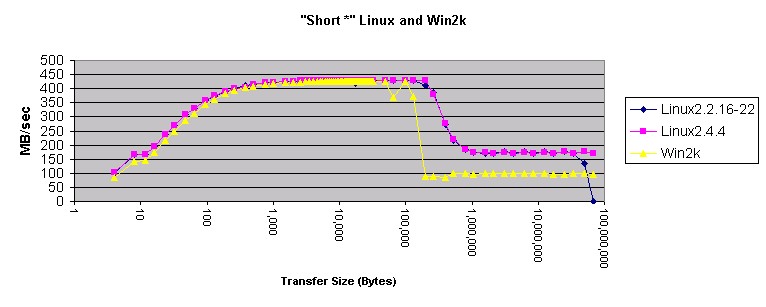
图 6. Linux 和 Win2k 中的 "Short"?
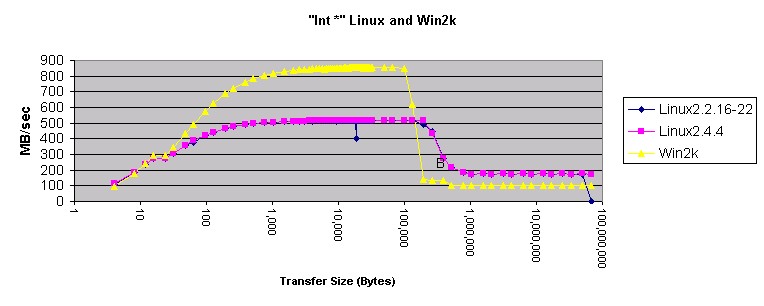
图 7. Linux 和 Win2k 中的 "Int"?
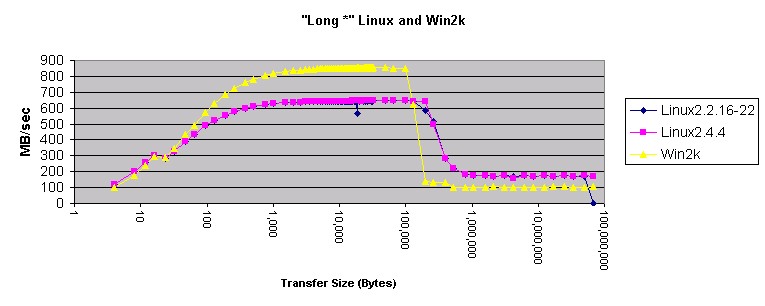
图 8. Linux 和 Win2k 中的 "Long"?
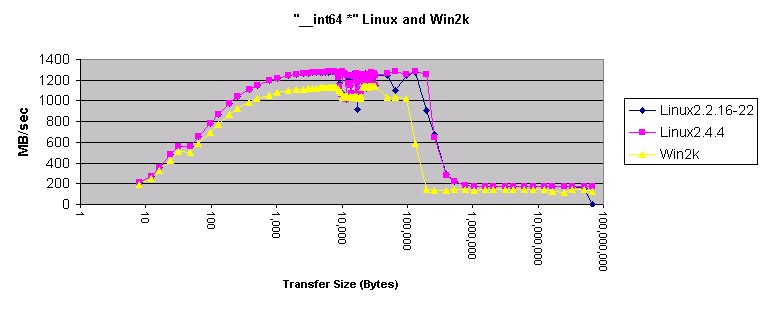
图 9. Linux 和 Win2k 中的 "_int64"?
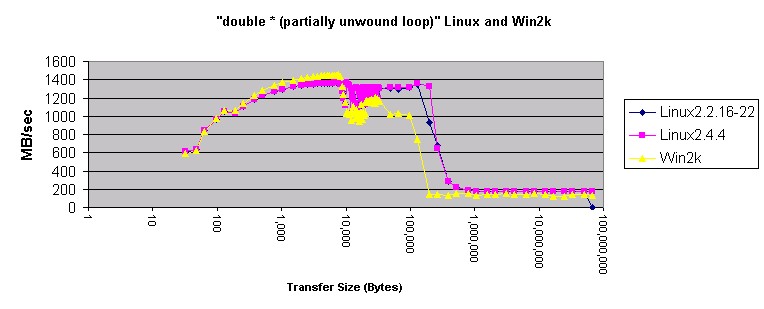
图 10. Linux 和 Win2k 中的 "Double"?
这些图有一些古怪的地方。首先,在 Linux 上使用?
"long *"?好象比使用?"int *"?更好。既然?int?和?long?变量在 Linux 和 Windows 上的长度相同,肯定是什么地方出错了。main(方法 3 和方法 4 )的相关部分的反汇编如下所示:
方法 3 和方法 4("int *" 和 "long *")反汇编?这种表现看起来象是高速缓存级别之间的差频。系统设计者可能不得不解释为什么 Linux 会这样。
回页首关于编译器优化的注意事项
读者 Matteo Ianeselli 指出了 gcc 编译器的“-funroll-loops”选项。因为我们输入限制循环次数的变量,所以我不清楚编译器如何展开这些循环中的一个循环。根据我在命令行输入的值,编译器可能已经把循环过分展开。我使用“-funroll-loops”选项在 ThinkPad 770X 上运行一个快速测试。结果如下所示:
 ?
? ?
? ?
? ?
? ?
? ?
? ?
? ?
? ?
?- 对于小于 1.5 MB 的传送,展开循环比不使用这个选项展开的速度稍慢。对于大于 1.5 MB 的传送,展开循环产生的加速大约是 135/131。
我先前已经看过 Microsoft C++ 编译器上的各种选项以查看是否有比“-O2”更好的选项。在我的测试中,我没有发现。我又放弃了继续搜索。但是,如果我们的读者用他/她最喜欢的 cl.exe 上的优化参数编译 memxfer5c.cpp,“并且”使性能得到了提高,请通过?讨论论坛告诉我们。当众多人参与时,搜索 cl.exe 的参数空间的效率就会更高。
回页首
结论
这次好象我提出的问题比答案还多。除上面提出的奇怪现象外,我的结果看起来都是在预料之中的。
先前,我慎重地下了结论:在 Linux 和 Windows 下使用 memcpy() 是一个好主意。这个月的测量肯定了这个结论。Memcpy() 产生的结果比 Windows 和 Linux 上任何其它的方法产生的结果都要好。将 Windows 与 Linux 相比较,Windows 在使用 4 字节指针传送内存和传送小于 200 KB 内存时速度更快。传送的内存小于 10 KB 时,局部展开的?"double *"?方法在 Windows 上也更快。在所有其它的情况下,Linux 移动内存的速度好象更快。
参考资料
- 您可以参阅本文在 developerWorks 全球站点上的?英文原文.?
请单击文章顶部或底部的?讨论,参与本专栏系列的?讨论论坛。?
研究内存传送程序的源代码、测试脚本以及带有图和原始数据的 Excel 电子表格:
- memxfer5c.cpptest2c.shtest2c.xls
请阅读本系列开头的?介绍文章;它定义了 Ed 使用的测量工具。?
请阅读 Ed 的本系列中的?前一专栏。?
请在?developerWorks Linux 专区查找更多的 Linux 参考资料,包括以下文章:
- Operating system flexibilityLinux, the server operating system
关于作者

Edward Bradford 博士现在为 IBM Software Group 管理 Microsoft Premier Support,并且每周